ChineseNER
1.0.0
Ce projet utilise
Si vous ne comprenez pas la reconnaissance des entités nommées, vous pouvez d'abord lire cet article. Au fait, s'il vous plaît, étaler ~
C'est le moyen le plus simple d'identifier un modèle BILSTM + CRF pour une entité nommée.
Il existe trois ensembles de données open source disponibles dans le dossier de données, Boson Data (https://bosonnlp.com), 1998 Données quotidiennes étiquetées par les personnes, et les données open source de MSRA Microsoft Asia Research Institute. Parmi eux, il existe 6 types d'entités dans l'ensemble de données de boson. Le Corpus quotidien des gens et MSRA n'extraient généralement que trois types d'entités: nom de la personne, nom de lieu et nom de l'organisation.
Exécutez d'abord le fichier Python dans les données pour traiter les données que le modèle à utiliser.
Commencez à s'entraîner avec python train.py , et le modèle formé sera enregistré dans le dossier du modèle.
Utilisation python train.py pretrained commencera une formation à l'aide de vecteurs de mots pré-entraînés. Vec.txt est un plus petit vecteur de mots pré-entraîné trouvé en ligne. Vous pouvez vous référer à mon code pour le modifier pour utiliser d'autres meilleurs vecteurs de mots pré-entraînés.
Utilisez python train.py test pour les tests, et le dernier modèle du dossier du modèle sera automatiquement lu et entrera en chinois pour tester. La qualité des résultats des tests dépend de la précision du modèle.
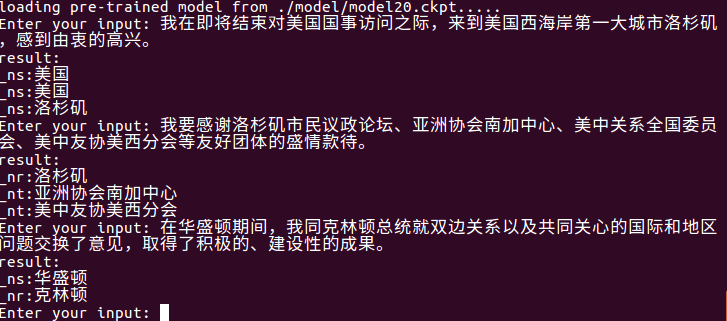
Utilisez python train.py input_file output_file pour l'extraction d'entité au niveau du fichier.
Il peut lire automatiquement le dernier modèle dans le dossier du modèle, extraire les entités dans input_file et les écrire dans output_file . Il y a d'abord la phrase d'origine, puis le type d'entité et l'entité (peut être modifié selon les besoins).
Par exemple, python train.py test1.txt res.txt , res.txt, le contenu est le suivant:
Des modifications supplémentaires sont ajoutées de temps à autre. .
Utilisez directement le modèle BILSTM + CRF dans le didacticiel Pytorch.
Il suffit de courir Train.py Training. Puisque nous utilisons le CPU et n'utilisons pas de lot, la vitesse d'entraînement est super lente. Si vous souhaitez simplement exécuter le code, il est recommandé d'utiliser uniquement des données pour l'exécuter. Pytorch ne sera pas mis à jour pour le moment.
Les paramètres n'ont pas été ajustés trop soigneusement. La valeur F de l'ensemble de données du boson était d'environ 70% à 75%, et la valeur F des ensembles de données quotidiens et MSRA était d'environ 85% ~ 90%. (Après tout, Boson a 6 types d'entités, et les deux autres n'ont que 3 types)
2018-9-15 Ajout de la version TensorFlow.
2018-9-17 a ajouté l'ensemble de données quotidiennes des gens en 1998 et l'ensemble de données MSRA Microsoft Asia Research Institute.
2018-9-19 Le style de code a été simplement modifié et le modèle a été extrait pour une expansion future.
2018-9-22 Ajout de la fonction python train.py test .
2018-10-6 Ajouter les paramètres d'utilisation pour déterminer s'il faut utiliser des vecteurs de mots pré-formés pour la formation.
2018-10-1111 Fonction ajoutée: il peut extraire des entités à partir d'un fichier texte et les écrire dans un autre fichier.



