ChineseNER
1.0.0
يستخدم هذا المشروع
إذا كنت لا تفهم التعرف على الكيان المسماة ، فيمكنك قراءة هذه المقالة أولاً. بالمناسبة ، يرجى النجوم ~
هذه هي أسهل طريقة لتحديد نموذج BILSTM+CRF لكيان مسمى.
هناك ثلاث مجموعات بيانات مفتوحة المصدر متوفرة في مجلد البيانات وبيانات Boson (https://bosonnlp.com) و 1998 بيانات المسمى اليومية للأفراد ومعهد MSRA Microsoft Asia Research Institute Open Source. من بينها ، هناك 6 أنواع كيانات في مجموعة بيانات Boson. تقوم شركة People Daily Corpus و MSRA بشكل عام باستخراج ثلاثة أنواع من الكيانات: اسم الشخص واسم المكان واسم المنظمة.
قم أولاً بتشغيل ملف Python في البيانات لمعالجة البيانات التي يجب استخدامها للنموذج.
ابدأ التدريب مع python train.py ، وسيتم حفظ النموذج المدرب في مجلد النموذج.
باستخدام python train.py pretrained سيبدأ التدريب باستخدام ناقلات Word PretRained. Vec.txt هو ناقل كلمة أصغر مسبقًا موجودًا على الإنترنت. يمكنك الرجوع إلى الكود الخاص بي لتعديله لاستخدام ناقلات Word Pretried Prested الأخرى.
استخدم python train.py test للاختبار ، وسيتم قراءة أحدث طراز في مجلد النموذج تلقائيًا وإدخال الصينية للاختبار. تعتمد جودة نتائج الاختبار على دقة النموذج.
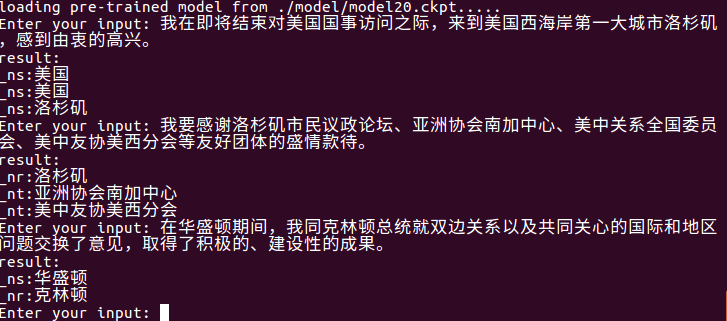
استخدم python train.py input_file output_file لاستخراج كيان مستوى الملف.
يمكنه تلقائيًا قراءة أحدث طراز في مجلد النموذج ، واستخراج الكيانات في input_file واكتبها في output_file . أولاً ، هناك الجملة الأصلية ، ثم نوع الكيان والكيان (يمكن تعديله حسب الحاجة).
على سبيل المثال ، python train.py test1.txt res.txt ، محتوى res.txt كما يلي:
تتم إضافة تعديلات إضافية من وقت لآخر. .
استخدم نموذج BILSTM+CRF في البرنامج التعليمي Pytorch مباشرة.
فقط قم بتشغيل Train.py Training. نظرًا لأننا نستخدم وحدة المعالجة المركزية ولا نستخدم دفعة ، فإن سرعة التدريب بطيئة للغاية. إذا كنت ترغب ببساطة في تشغيل الكود ، فمن المستحسن استخدام بعض البيانات فقط لتشغيله. لن يتم تحديث Pytorch في الوقت الحالي.
لم يتم ضبط المعلمات بعناية للغاية. بلغت قيمة F لمجموعة بيانات Boson حوالي 70 ٪ ~ 75 ٪ ، وكانت قيمة F لمجموعات بيانات MSRA اليومية ومجموعات MSRA حوالي 85 ٪ ~ 90 ٪. (بعد كل شيء ، يحتوي Boson على 6 أنواع كيان ، والآخران لهما 3 أنواع فقط)
2018-9-15 أضيفت نسخة TensorFlow.
أضافت 2018-9-17 مجموعة البيانات اليومية للأشخاص في عام 1998 ومجموعة بيانات MSRA Microsoft Asia Research Institute.
2018-9-19 تم تعديل نمط الكود ببساطة وتم استخراج النموذج للتوسع في المستقبل.
2018-9-22 تمت إضافة وظيفة python train.py test .
2018-10-6 أضف معلمات الاستخدام لتحديد ما إذا كنت تريد استخدام ناقلات الكلمات المدربة مسبقًا للتدريب.
2018-10-11 الوظيفة المضافة: يمكنها استخراج الكيانات من ملف نصي واكتبها إلى ملف آخر.



