ChineseNER
1.0.0
Este projeto usa
Se você não entende o reconhecimento de entidade nomeado, pode ler este artigo primeiro. A propósito, por favor estrela ~
Esta é a maneira mais fácil de identificar um modelo BILSTM+CRF para uma entidade nomeada.
Existem três conjuntos de dados de código aberto disponíveis na pasta de dados, dados do bóson (https://bosonnlp.com), 1998 Data Daily Roted Data e MSRA Microsoft Asia Research Institute Data. Entre eles, existem 6 tipos de entidade no conjunto de dados do bóson. O corpus diário das pessoas e a MSRA geralmente extraem apenas três tipos de entidades: nome da pessoa, nome do local e nome da organização.
Primeiro execute o arquivo python nos dados para processar os dados para o modelo usar.
Comece a treinar com python train.py , e o modelo treinado será salvo na pasta do modelo.
O uso python train.py pretrained começará a treinar usando vetores de palavras pré -traído. Vec.txt é um vetor de palavras pré -ridículo menor encontrado online. Você pode consultar o meu código para modificá -lo para usar outros vetores de palavras pré -treinados.
Use python train.py test para teste, e o modelo mais recente da pasta do modelo será lido e inserido automaticamente para testar o chinês. A qualidade dos resultados do teste depende da precisão do modelo.
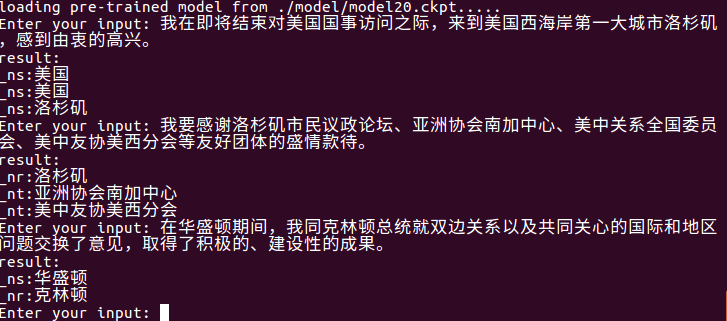
Use python train.py input_file output_file para extração de entidades no nível do arquivo.
Ele pode ler automaticamente o modelo mais recente na pasta do modelo, extrair as entidades no input_file e escrevê -las no output_file . Primeiro, há a frase original, depois o tipo de entidade e a entidade (podem ser modificados conforme necessário).
Por exemplo, python train.py test1.txt res.txt , res.txt Conteúdo é o seguinte:
Modificações adicionais são adicionadas de tempos em tempos. .
Use o modelo BILSTM+CRF no tutorial Pytorch diretamente.
Basta executar o treinamento de trem.py. Como usamos a CPU e não usamos lote, a velocidade de treinamento é super lenta. Se você deseja simplesmente executar o código, é recomendável usar apenas alguns dados para executá -los. Pytorch não será atualizado por enquanto.
Os parâmetros não foram ajustados com muito cuidado. O valor F do conjunto de dados do bóson foi de cerca de 70%~ 75%, e o valor F dos conjuntos de dados diários e MSRA das pessoas foi de cerca de 85%~ 90%. (Afinal, Boson tem 6 tipos de entidade, e os outros dois têm apenas 3 tipos)
2018-9-15 adicionou versão TensorFlow.
2018-9-17 adicionou o conjunto de dados diários das pessoas em 1998 e o conjunto de dados do MSRA Microsoft Asia Research Institute.
2018-9-19 O estilo de código foi simplesmente modificado e o modelo foi extraído para expansão futura.
2018-9-22 adicionou função python train.py test .
2018-10-6 Adicione os parâmetros de uso para determinar se o uso de vetores de palavras pré-treinados para treinamento.
2018-10-11 Função adicionada: ele pode extrair entidades de um arquivo de texto e escrevê-las para outro arquivo.



