ChineseNER
1.0.0
이 프로젝트는 사용합니다
이름이 지정된 엔티티 인식을 이해하지 못하면 먼저이 기사를 읽을 수 있습니다. 그건 그렇고, 스타 ~
이것은 명명 된 엔티티의 BILSTM+CRF 모델을 식별하는 가장 쉬운 방법입니다.
데이터 폴더, Boson Data (https://bosonnlp.com), 1998 People 's Daily Labeled Data 및 MSRA Microsoft Asia Research Institute 오픈 소스 데이터에 사용할 수있는 세 가지 오픈 소스 데이터 세트가 있습니다. 그중에는 Boson 데이터 세트에는 6 개의 엔티티 유형이 있습니다. People 's Daily Corpus 및 MSRA는 일반적으로 사람 이름, 장소 이름 및 조직 이름의 세 가지 엔티티 유형 만 추출합니다.
먼저 데이터에서 Python 파일을 실행하여 모델이 사용할 데이터를 처리합니다.
python train.py 로 교육을 시작하면 훈련 된 모델이 모델 폴더에 저장됩니다.
python train.py pretrained 에 사기가 시작됩니다. vec.txt는 온라인에서 발견되는 작은 사전 취사 단어 벡터입니다. 내 코드를 참조하여 다른 더 나은 사전 처리 된 단어 벡터를 사용하도록 수정할 수 있습니다.
테스트를 위해 python train.py test 사용하면 모델 폴더의 최신 모델을 자동으로 읽고 중국어로 입력하여 테스트합니다. 테스트 결과의 품질은 모델의 정확도에 따라 다릅니다.
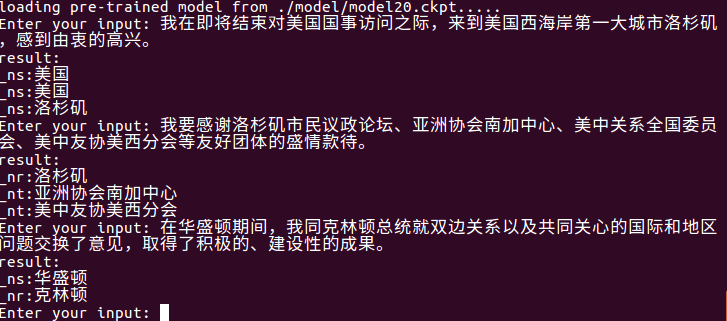
파일 레벨 엔티티 추출에는 python train.py input_file output_file 사용하십시오.
모델 폴더에서 최신 모델을 자동으로 읽고 input_file 에서 엔티티를 추출하여 output_file 에 쓸 수 있습니다. 먼저 원래 문장이 있고 엔티티 유형 및 엔티티가 있습니다 (필요에 따라 수정할 수 있음).
예를 들어, python train.py test1.txt res.txt , res.txt 컨텐츠는 다음과 같습니다.
추가 수정이 수시로 추가됩니다. .
Pytorch 튜토리얼에서 BILSTM+CRF 모델을 직접 사용하십시오.
그냥 기차를 운영하십시오. CPU를 사용하고 배치를 사용하지 않기 때문에 훈련 속도는 매우 느립니다. 단순히 코드를 실행하려면 일부 데이터 만 사용하여 실행하는 것이 좋습니다. Pytorch는 당분간 업데이트되지 않습니다.
매개 변수는 너무 조심스럽게 조정되지 않았습니다. Boson 데이터 세트의 F 값은 약 70%~ 75%였으며 People 's Daily 및 MSRA 데이터 세트의 F 값은 약 85%~ 90%였습니다. (결국 Boson에는 6 개의 엔티티 유형이 있고 다른 두 가지 유형은 3 가지 만 있습니다)
2018-9-15 추가 텐서 플로우 버전.
2018-9-17은 1998 년 People 's Daily Data Set과 MSRA Microsoft Asia Research Institute 데이터 세트를 추가했습니다.
2018-9-19 코드 스타일은 단순히 수정되었으며 향후 확장을 위해 모델이 추출되었습니다.
2018-9-22 추가 python train.py test 기능.
2018-10-6 사용 매개 변수를 추가하여 훈련을 위해 미리 훈련 된 단어 벡터를 사용할지 여부를 결정합니다.
2018-10-11 추가 기능 : 텍스트 파일에서 엔티티를 추출하여 다른 파일에 쓸 수 있습니다.



