ChineseNER
1.0.0
Proyek ini menggunakan
Jika Anda tidak memahami pengakuan entitas yang disebutkan, Anda dapat membaca artikel ini terlebih dahulu. Ngomong -ngomong, tolong bintangi ~
Ini adalah cara termudah untuk mengidentifikasi model BILSTM+CRF untuk entitas bernama.
Ada tiga set data open source yang tersedia di folder data, data Boson (https://bosonnlp.com), 1998 People Daily Data Daily, dan MSRA Microsoft Asia Research Institute data sumber terbuka. Di antara mereka, ada 6 jenis entitas dalam set data Boson. People's Daily Corpus dan MSRA umumnya hanya mengekstrak tiga jenis entitas: nama orang, nama tempat, dan nama organisasi.
Pertama -tama jalankan file Python dalam data untuk memproses data agar model digunakan.
Mulailah berlatih dengan python train.py , dan model terlatih akan disimpan di folder model.
Menggunakan python train.py pretrained akan mulai berlatih menggunakan vektor kata pretrained. Vec.txt adalah kata pretrained yang lebih kecil yang ditemukan secara online. Anda dapat merujuk pada kode saya untuk memodifikasinya untuk menggunakan vektor kata lain yang lebih baik.
Gunakan python train.py test untuk pengujian, dan model terbaru dalam folder model akan secara otomatis dibaca dan dimasukkan Cina untuk diuji. Kualitas hasil tes tergantung pada keakuratan model.
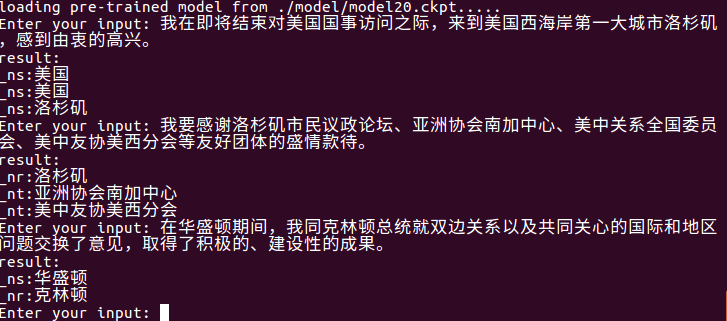
Gunakan python train.py input_file output_file untuk ekstraksi entitas tingkat file.
Ini dapat secara otomatis membaca model terbaru di folder model, mengekstrak entitas di input_file dan menulisnya ke output_file . Pertama ada kalimat asli, maka jenis entitas dan entitas (dapat dimodifikasi sesuai kebutuhan).
Misalnya, python train.py test1.txt res.txt , res.txt konten adalah sebagai berikut:
Modifikasi tambahan ditambahkan dari waktu ke waktu. .
Gunakan model BILSTM+CRF di tutorial Pytorch secara langsung.
Jalankan saja pelatihan train.py. Karena kami menggunakan CPU dan tidak menggunakan batch, kecepatan pelatihannya sangat lambat. Jika Anda hanya ingin menjalankan kode, disarankan untuk hanya menggunakan beberapa data untuk menjalankannya. Pytorch tidak akan diperbarui untuk saat ini.
Parameter tidak disesuaikan terlalu hati -hati. Nilai F dari set data boson adalah sekitar 70%~ 75%, dan nilai f dari set data harian dan MSRA adalah sekitar 85%~ 90%. (Bagaimanapun, Boson memiliki 6 jenis entitas, dan dua lainnya hanya memiliki 3 jenis)
2018-9-15 Menambahkan Versi TensorFlow.
2018-9-17 Menambahkan kumpulan data harian orang pada tahun 1998 dan kumpulan data MSRA Microsoft Asia Research Institute.
2018-9-19 Gaya kode hanya dimodifikasi dan model diekstraksi untuk ekspansi di masa depan.
2018-9-22 Menambahkan python train.py test Function.
2018-10-6 Tambahkan parameter penggunaan untuk menentukan apakah akan menggunakan vektor kata pra-terlatih untuk pelatihan.
Fungsi Penambahan 2018-10-11: Ini dapat mengekstrak entitas dari file teks dan menulisnya ke file lain.



