ChineseNER
1.0.0
This project uses
If you don’t understand named entity recognition, you can read this article first. By the way, please star~
This is the easiest way to identify a BiLSTM+CRF model for a named entity.
There are three open source data sets available in the data folder, Boson Data (https://bosonnlp.com), 1998 People's Daily Labeled Data, and MSRA Microsoft Asia Research Institute open source data. Among them, there are 6 entity types in the boson data set. People's Daily Corpus and MSRA generally only extract three entity types: person name, place name, and organization name.
First run the python file in the data to process the data for the model to use.
Start training with python train.py , and the trained model will be saved in the model folder.
Using python train.py pretrained will start training using pretrained word vectors. vec.txt is a smaller pretrained word vector found online. You can refer to my code to modify it to use other better pretrained word vectors.
Use python train.py test for testing, and the latest model in the model folder will be automatically read and enter Chinese to test. The quality of the test results depends on the accuracy of the model.
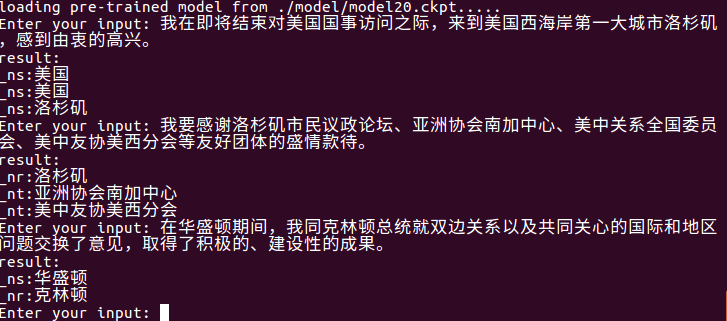
Use python train.py input_file output_file for file-level entity extraction.
It can automatically read the latest model in the model folder, extract the entities in input_file and write them into output_file . First there is the original sentence, then the entity type and entity (can be modified as needed).
For example, python train.py test1.txt res.txt , res.txt content is as follows:
Additional modifications are added from time to time. .
Use the Bilstm+crf model in pytorch tutorial directly.
Just run train.py training. Since we use CPU and do not use batch, the training speed is super slow. If you want to simply run the code, it is recommended to use only some data to run it. pytorch will not be updated for the time being.
The parameters were not adjusted too carefully. The f value of the boson data set was around 70%~75%, and the f value of the People's Daily and MSRA data sets was around 85%~90%. (After all, boson has 6 entity types, and the other two have only 3 types)
2018-9-15 Added tensorflow version.
2018-9-17 Added the People's Daily data set in 1998 and the MSRA Microsoft Asia Research Institute data set.
2018-9-19 The code style was simply modified and the model was extracted for future expansion.
2018-9-22 Added python train.py test function.
2018-10-6 Add the use parameters to determine whether to use pre-trained word vectors for training.
2018-10-11 Added function: It can extract entities from a text file and write them to another file.



