optimum quanto
release: 0.2.6
?最佳量子是最佳的pytorch量化後端。
它的設計具有多功能性和簡單性:
weight_only和? safetensors ,功能尚未實現:
簡而言之:
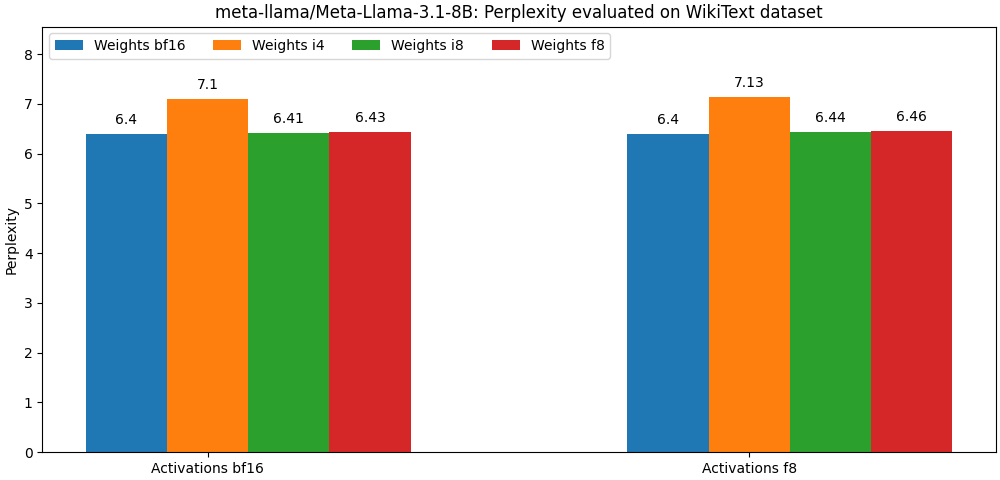
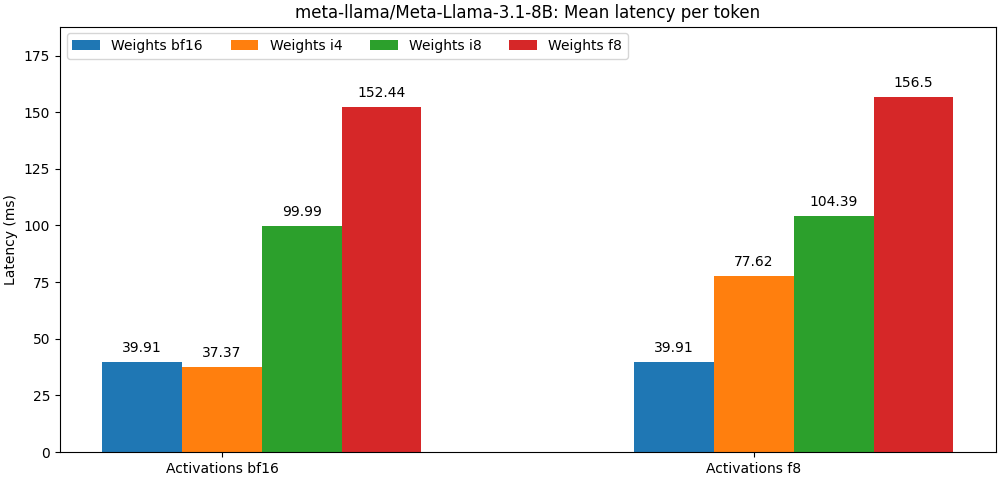
int8 / float8權重和float8激活編輯的型號非常接近Full Percision型號,下面的段落只是一個例子。請參閱bench文件夾,以獲取每個模型用例詳細結果。
最佳量化可作為PIP包裝。
pip install optimum-quantooptimum-quanto提供了輔助類,以量化,保存和重新加載擁抱面部量化模型。
第一步是量化模型
from transformers import AutoModelForCausalLM
from optimum . quanto import QuantizedModelForCausalLM , qint4
model = AutoModelForCausalLM . from_pretrained ( 'meta-llama/Meta-Llama-3-8B' )
qmodel = QuantizedModelForCausalLM . quantize ( model , weights = qint4 , exclude = 'lm_head' )注意:該模型量化權重將被冷凍。如果您想讓它們未能訓練以訓練它們,則需要使用optimum.quanto.quantize 。直接量化。
可以使用save_pretrained保存量化的模型:
qmodel . save_pretrained ( './Llama-3-8B-quantized' )以後可以使用from_pretrained重新加載:
from optimum . quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM . from_pretrained ( 'Llama-3-8B-quantized' )您可以量化擴散器管道中的任何子模型,然後在另一個管道中無縫包含它們。
在這裡,我們量化了Pixart管道的transformer 。
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel , qfloat8
model = PixArtTransformer2DModel . from_pretrained ( "PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" , subfolder = "transformer" )
qmodel = QuantizedPixArtTransformer2DModel . quantize ( model , weights = qfloat8 )
qmodel . save_pretrained ( "./pixart-sigma-fp8" )後來,我們可以重新加載量化的模型並重新創建管道:
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel
transformer = QuantizedPixArtTransformer2DModel . from_pretrained ( "./pixart-sigma-fp8" )
transformer . to ( device = "cuda" )
pipe = PixArtSigmaPipeline . from_pretrained (
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" ,
transformer = None ,
torch_dtype = torch . float16 ,
). to ( "cuda" )
pipe . transformer = transformer 使用低級量子API時要記住的一件事是,默認模型權重是動態量化的:必須進行明確的調用以“凍結”量化的權重。
典型的量化工作流將包括以下步驟:
1。量化
第一步將標準浮點模型轉換為動態量化的模型。
from optimum . quanto import quantize , qint8
quantize ( model , weights = qint8 , activations = qint8 )在此階段,僅修改模型的推斷以動態量化權重。
2。校準(如果未量化激活,可選)
Quanto支持校準模式,該模式允許在通過量化模型傳遞代表樣品的同時記錄激活範圍。
from optimum . quanto import Calibration
with Calibration ( momentum = 0.9 ):
model ( samples )這會自動激活量化模塊中激活的量化。
3。曲調,又稱量化訓練(可選)
如果模型的性能過多,則可以將其調整為一些時代以恢復浮點模型性能。
import torch
model . train ()
for batch_idx , ( data , target ) in enumerate ( train_loader ):
data , target = data . to ( device ), target . to ( device )
optimizer . zero_grad ()
output = model ( data ). dequantize ()
loss = torch . nn . functional . nll_loss ( output , target )
loss . backward ()
optimizer . step ()4。凍結整數重量
冷凍模型時,其浮子重量將被量化的整數重量所取代。
from optimum . quanto import freeze
freeze ( model )5。序列化量化模型
量化的模型權重可以序列化為state_dict ,並保存到文件中。支持pickle和safetensors (推薦)。
from safetensors . torch import save_file
save_file ( model . state_dict (), 'model.safetensors' )為了能夠重新加載這些權重,您還需要存儲量化的模型量化圖。
import json
from optimum . quanto import quantization_map
with open ( 'quantization_map.json' , 'w' ) as f :
json . dump ( quantization_map ( model ), f )5。重新加載量化的模型
可以使用requantize助手從state_dict和quantization_map map重新加載序列化的量化模型。請注意,您需要首先實例化空模型。
import json
from safetensors . torch import load_file
from optimum . quanto import requantize
state_dict = load_file ( 'model.safetensors' )
with open ( 'quantization_map.json' , 'r' ) as f :
quantization_map = json . load ( f )
# Create an empty model from your modeling code and requantize it
with torch . device ( 'meta' ):
new_model = ...
requantize ( new_model , state_dict , quantization_map , device = torch . device ( 'cuda' ))請參閱示例以獲取該工作流程的實例。
Quanto的核心是張量子類,與:
對於浮點目的地類型,映射由本機Pytorch Cast(即Tensor.to() )完成。
對於整數目標類型,映射是一個簡單的圓形操作(即torch.round() )。
預測的目的是通過最大程度地減少以下數量來提高轉換的準確性:
該投影是int8和float8的對稱性或每通道,對於較低的位寬,則是對群的仿射(具有偏移或“零點”)。
使用較低寬度表示的好處之一是,您將能夠利用目標類型的加速操作,通常比其更高的精度等效物更快。
Quanto不支持使用混合目的地類型的張量轉換。
Quanto提供了一種通用機制,可以通過能夠處理定量張量optimum-quanto模塊替換torch模塊。
optimum-quanto模塊會動態轉換其權重,直到模型被冷凍為止,這會減慢推理,但如果需要調整模型,則需要。
權重通常沿著第一維(輸出功能)進行量化。
偏差未轉換以保持典型的addmm操作的準確性。
說明:要與未量化的算術操作一致,需要用等於輸入和重量尺度的乘積的量表進行量化,這會導致較小的尺度,相反,需要一個非常高的位寬度才能避免剪接。通常,使用int8輸入和權重,需要使用至少12位量化偏差,即int16中的偏差。由於今天的大多數偏見是float16 ,所以這是浪費時間。
使用靜態尺度(默認為[-1, 1]範圍)動態量化活性。
為了保持準確性,需要校準模型以評估最佳的激活量表(使用動量)。
可以量化以下模塊:
激活始終是量化的,因為模型圖中的大多數線性代數操作與每軸輸入不兼容:您只是無法添加在同一基礎上未表達的數字( you cannot add apples and oranges )。
相反,矩陣乘法涉及的權重始終沿其第一個軸進行量化,因為所有輸出特徵均相互獨立評估。
無論如何,即使激活進行了量化,量化矩陣乘法的輸出也將始終被取消,因為:
int32或float8 ),以更高的位寬(通常為int8或float32 )表示。float偏見結合在一起。如果相應的張量包含較大的異常值值,則對int8進行量化激活可能會導致嚴重的量化誤差。通常,這將導致量化的張量,其中大多數值設置為零(離群值除外)。
解決該問題的一種可能解決方案是“平滑”在靜態上“平滑”激活,如SpooterQuant所示。您可以找到一個腳本,以使某些模型體系結構在外部/平滑方面平滑。
一個更好的選擇是使用float8表示激活。


