optimum quanto
release: 0.2.6
? Optimum Quanto es un backend de cuantización de Pytorch para Optimum.
Ha sido diseñado con versatilidad y simplicidad en mente:
weight_only y? safetensors ,Características aún por implementar:
En una palabra:
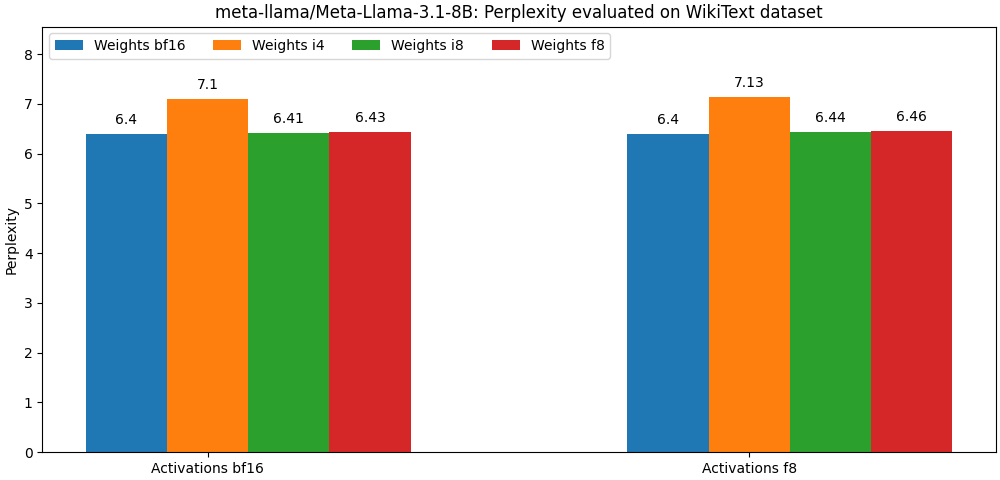
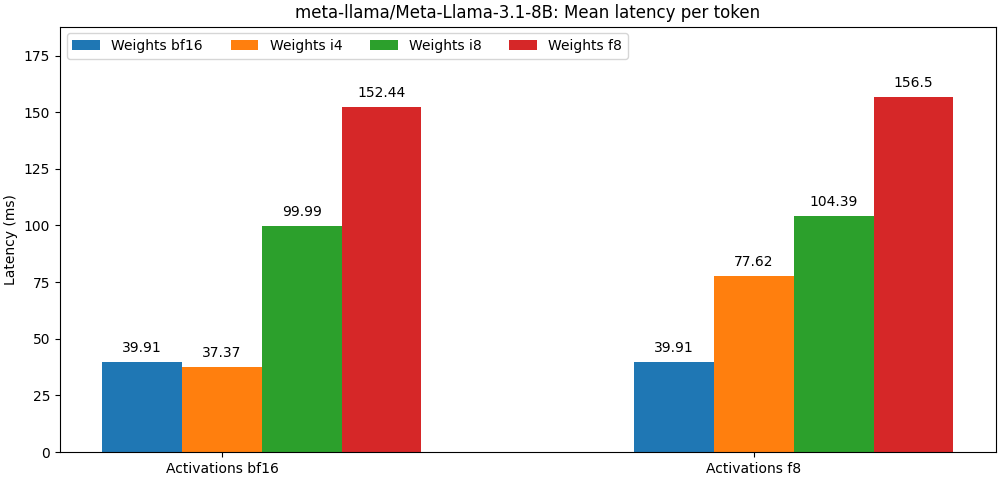
int8 / float8 y las activaciones float8 están muy cerca de los modelos de precisión completa, El párrafo a continuación es solo un ejemplo. Consulte la carpeta bench para obtener resultados detallados por caso de uso del modelo.
Optimum Quanto está disponible como un paquete PIP.
pip install optimum-quanto optimum-quanto proporciona clases de ayuda para cuantificar, guardar y recargar modelos cuantificados faciales.
El primer paso es cuantizar el modelo
from transformers import AutoModelForCausalLM
from optimum . quanto import QuantizedModelForCausalLM , qint4
model = AutoModelForCausalLM . from_pretrained ( 'meta-llama/Meta-Llama-3-8B' )
qmodel = QuantizedModelForCausalLM . quantize ( model , weights = qint4 , exclude = 'lm_head' ) Nota: Los pesos cuantificados del modelo se congelarán. Si desea mantenerlos sin congelar para entrenarlos, debe usar optimum.quanto.quantize directamente.
El modelo cuantificado se puede guardar utilizando save_pretrained :
qmodel . save_pretrained ( './Llama-3-8B-quantized' ) Más tarde se puede volver a cargar usando from_pretrained :
from optimum . quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM . from_pretrained ( 'Llama-3-8B-quantized' )Puede cuantificar cualquiera de los submodelos dentro de una tubería de difusores y incluirlos sin problemas más tarde en otra tubería.
Aquí cuantificamos el transformer de una tubería Pixart .
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel , qfloat8
model = PixArtTransformer2DModel . from_pretrained ( "PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" , subfolder = "transformer" )
qmodel = QuantizedPixArtTransformer2DModel . quantize ( model , weights = qfloat8 )
qmodel . save_pretrained ( "./pixart-sigma-fp8" )Más tarde, podemos recargar el modelo cuantificado y recrear la tubería:
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel
transformer = QuantizedPixArtTransformer2DModel . from_pretrained ( "./pixart-sigma-fp8" )
transformer . to ( device = "cuda" )
pipe = PixArtSigmaPipeline . from_pretrained (
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" ,
transformer = None ,
torch_dtype = torch . float16 ,
). to ( "cuda" )
pipe . transformer = transformer Una cosa a tener en cuenta al usar la API Quanto de bajo nivel es que los pesos de los modelos por defecto se cuantifican dinámicamente: se debe hacer una llamada explícita para 'congelar' los pesos cuantificados.
Un flujo de trabajo de cuantificación típico consistiría en los siguientes pasos:
1. Cuantizar
El primer paso convierte un modelo flotante estándar en un modelo cuantificado dinámicamente.
from optimum . quanto import quantize , qint8
quantize ( model , weights = qint8 , activations = qint8 )En esta etapa, solo la inferencia del modelo se modifica para cuantificar dinámicamente los pesos.
2. Calibrar (opcional si las activaciones no se cuantifican)
Quanto admite un modo de calibración que permite registrar los rangos de activación mientras pasa muestras representativas a través del modelo cuantificado.
from optimum . quanto import Calibration
with Calibration ( momentum = 0.9 ):
model ( samples )Esto activa automáticamente la cuantización de las activaciones en los módulos cuantificados.
3. Tune, también conocido como capacitación consciente de cuantización (opcional)
Si el rendimiento del modelo se degrada demasiado, uno puede sintonizarlo para algunas épocas para recuperar el rendimiento del modelo flotante.
import torch
model . train ()
for batch_idx , ( data , target ) in enumerate ( train_loader ):
data , target = data . to ( device ), target . to ( device )
optimizer . zero_grad ()
output = model ( data ). dequantize ()
loss = torch . nn . functional . nll_loss ( output , target )
loss . backward ()
optimizer . step ()4. Freeze enteros pesos
Al congelar un modelo, sus pesos flotantes son reemplazados por pesos enteros cuantificados.
from optimum . quanto import freeze
freeze ( model )5. Serializar modelo cuantificado
Los pesos de los modelos cuantizados se pueden serializar a un state_dict y guardar en un archivo. Se admiten tanto pickle como safetensors (recomendado).
from safetensors . torch import save_file
save_file ( model . state_dict (), 'model.safetensors' )Para poder recargar estos pesos, también debe almacenar el mapa de cuantización del modelo cuantificado.
import json
from optimum . quanto import quantization_map
with open ( 'quantization_map.json' , 'w' ) as f :
json . dump ( quantization_map ( model ), f )5. Recargar un modelo cuantificado
Un modelo cuantificado serializado se puede volver a cargar desde un state_dict y un quantization_map utilizando el ayudante requantize . Tenga en cuenta que primero necesita instanciar un modelo vacío.
import json
from safetensors . torch import load_file
from optimum . quanto import requantize
state_dict = load_file ( 'model.safetensors' )
with open ( 'quantization_map.json' , 'r' ) as f :
quantization_map = json . load ( f )
# Create an empty model from your modeling code and requantize it
with torch . device ( 'meta' ):
new_model = ...
requantize ( new_model , state_dict , quantization_map , device = torch . device ( 'cuda' ))Consulte los ejemplos para obtener instancias de ese flujo de trabajo.
En el corazón de Quanto hay una subclase tensor que corresponde a:
Para los tipos de destino de punto flotante, el mapeo lo realiza el elenco nativo de Pytorch (es decir, Tensor.to() ).
Para los tipos de destino entero, el mapeo es una operación de redondeo simple (es decir, torch.round() ).
El objetivo de la proyección es aumentar la precisión de la conversión minimizando el número de:
La proyección es simétrica por tensor o por canal para int8 y float8 , y Affine en forma de grupo (con un cambio o 'punto cero') para el ancho de bit más bajo.
Uno de los beneficios de usar una representación de ancho de bits inferior es que podrá aprovechar las operaciones aceleradas para el tipo de destino, que generalmente es más rápido que sus equivalentes de mayor precisión.
Quanto no admite la conversión de un tensor utilizando tipos de destino mixto.
Quanto proporciona un mecanismo genérico para reemplazar los módulos torch mediante módulos optimum-quanto que pueden procesar tensores Quanto.
Los módulos optimum-quanto convierten dinámicamente sus pesos hasta que se congele un modelo, lo que ralentiza un poco la inferencia, pero se requiere si el modelo necesita ser sintonizado.
Los pesos generalmente se cuantifican por canal a lo largo de la primera dimensión (características de salida).
Los sesgos no se convierten para preservar la precisión de una operación típica addmm .
Explicación: Para ser consistente con las operaciones aritméticas no cuantizadas, los sesgos deberían cuantificarse con una escala que sea igual al producto de las escalas de entrada y peso, lo que conduce a una escala ridículamente pequeña y, por el contrario, requiere un ancho de bits muy alto para evitar el recorte. Por lo general, con las entradas y pesos int8 , los sesgos necesitarían cuantificar con al menos 12 bits, es decir, en int16 . Dado que la mayoría de los sesgos son hoy float16 , esta es una pérdida de tiempo.
Las activaciones se cuantifican dinámicamente por tensor utilizando escalas estáticas (predeterminados al rango [-1, 1] ).
Para preservar la precisión, el modelo debe calibrarse para evaluar las mejores escalas de activación (usando un impulso).
Se pueden cuantificar los siguientes módulos:
Las activaciones siempre se cuantifican por tensor porque la mayoría de las operaciones de álgebra lineal en un gráfico de modelo no son compatibles con las entradas por eje: simplemente no puede agregar números que no se expresan en la misma base ( you cannot add apples and oranges ).
Los pesos involucrados en las multiplicaciones de matriz están, por el contrario, siempre cuantizados a lo largo de su primer eje, porque todas las características de salida se evalúan independientemente entre sí.
De todos modos, las salidas de una multiplicación de matriz cuantificada siempre se desquantizarán, incluso si las activaciones se cuantifican, porque:
int32 o float32 ) que el ancho de bit de activación (típicamente int8 o float8 ),float . Las activaciones de cuantificación por tensor a int8 pueden conducir a errores de cuantización graves si los tensores correspondientes contienen grandes valores atípicos. Por lo general, esto conducirá a tensores cuantificados con la mayoría de los valores establecidos en cero (excepto los valores atípicos).
Una posible solución para solucionar ese problema es "suavizar" las activaciones estáticamente como lo ilustran Smoothquant. Puede encontrar un script para suavizar algunas arquitecturas de modelos en externo/suave.
Una mejor opción es representar activaciones usando float8 .


