optimum quanto
release: 0.2.6
? Optimum Quanto adalah backend kuantisasi pytorch untuk optimal.
Ini telah dirancang dengan keserbagunaan dan kesederhanaan dalam pikiran:
weight_only dan? safetensors ,Fitur yang belum diimplementasikan:
Pendeknya:
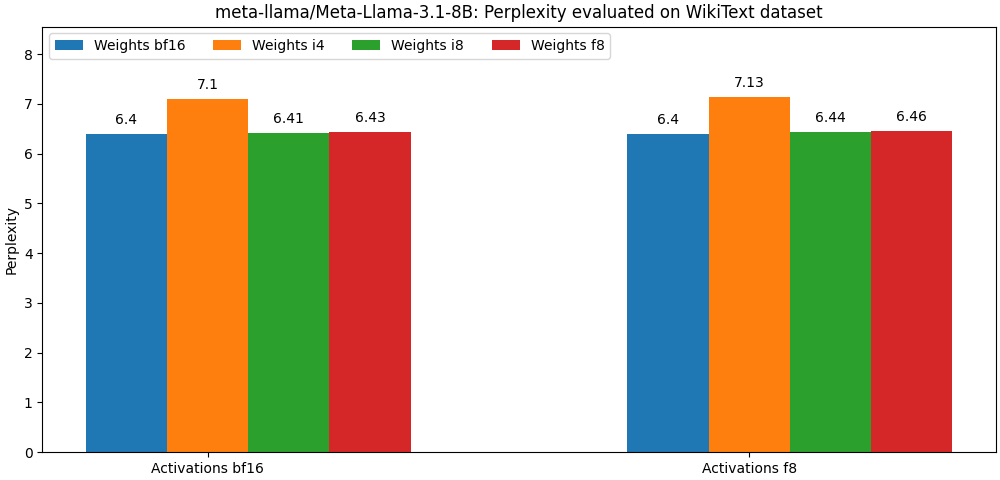
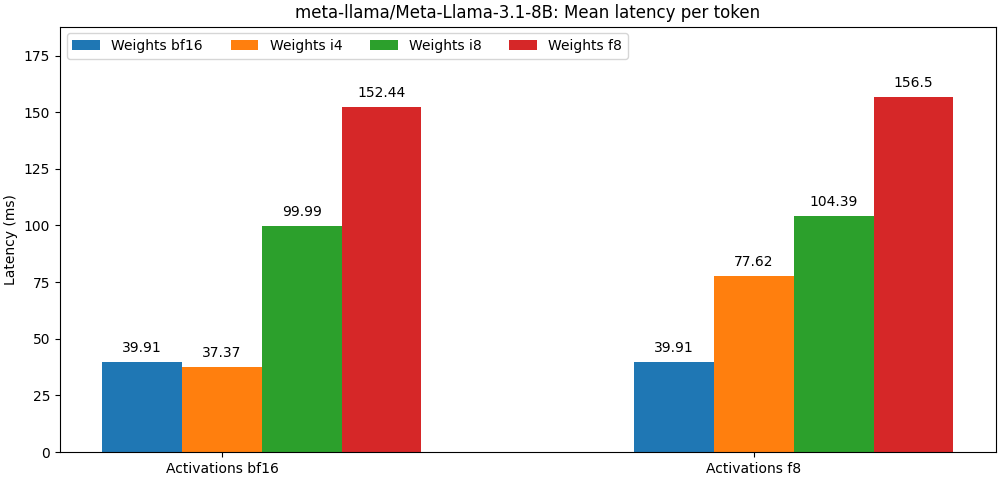
int8 / float8 dan aktivasi float8 sangat dekat dengan model presisi penuh, Paragraf di bawah ini hanyalah sebuah contoh. Silakan merujuk ke folder bench untuk hasil rinci per kasus penggunaan model.
Optimum Quanto tersedia sebagai paket PIP.
pip install optimum-quanto optimum-quanto menyediakan kelas helper untuk mengukur, menyimpan, dan memuat ulang model kuantisasi wajah.
Langkah pertama adalah mengukur model
from transformers import AutoModelForCausalLM
from optimum . quanto import QuantizedModelForCausalLM , qint4
model = AutoModelForCausalLM . from_pretrained ( 'meta-llama/Meta-Llama-3-8B' )
qmodel = QuantizedModelForCausalLM . quantize ( model , weights = qint4 , exclude = 'lm_head' ) Catatan: Model bobot kuantisasi akan dibekukan. Jika Anda ingin membuat mereka tidak beku untuk melatih mereka, Anda perlu menggunakan optimum.quanto.quantize secara langsung.
Model terkuantisasi dapat disimpan menggunakan save_pretrained :
qmodel . save_pretrained ( './Llama-3-8B-quantized' ) Nantinya dapat dimuat ulang menggunakan from_pretrained :
from optimum . quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM . from_pretrained ( 'Llama-3-8B-quantized' )Anda dapat mengukur salah satu submodel di dalam pipa diffuser dan dengan mulus memasukkannya nanti dalam pipa lain.
Di sini kami menghitung transformer pipa Pixart .
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel , qfloat8
model = PixArtTransformer2DModel . from_pretrained ( "PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" , subfolder = "transformer" )
qmodel = QuantizedPixArtTransformer2DModel . quantize ( model , weights = qfloat8 )
qmodel . save_pretrained ( "./pixart-sigma-fp8" )Nanti, kita dapat memuat ulang model kuantisasi dan membuat ulang pipa:
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel
transformer = QuantizedPixArtTransformer2DModel . from_pretrained ( "./pixart-sigma-fp8" )
transformer . to ( device = "cuda" )
pipe = PixArtSigmaPipeline . from_pretrained (
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" ,
transformer = None ,
torch_dtype = torch . float16 ,
). to ( "cuda" )
pipe . transformer = transformer Satu hal yang perlu diingat ketika menggunakan API Quanto level rendah adalah bahwa secara default bobot model secara dinamis dikuantisasi: panggilan eksplisit harus dilakukan untuk 'membekukan' bobot terkuantisasi.
Alur kerja kuantisasi yang khas akan terdiri dari langkah -langkah berikut:
1. Kuantisasi
Langkah pertama mengubah model float standar menjadi model yang dikuantisasi secara dinamis.
from optimum . quanto import quantize , qint8
quantize ( model , weights = qint8 , activations = qint8 )Pada tahap ini, hanya inferensi model yang dimodifikasi untuk secara dinamis mengukur bobot.
2. Calibrate (opsional jika aktivasi tidak dikuantisasi)
Quanto mendukung mode kalibrasi yang memungkinkan untuk merekam rentang aktivasi sambil melewati sampel yang representatif melalui model kuantisasi.
from optimum . quanto import Calibration
with Calibration ( momentum = 0.9 ):
model ( samples )Ini secara otomatis mengaktifkan kuantisasi aktivasi dalam modul terkuantisasi.
3. Tune, alias kuantisasi-sadar-pelatihan (opsional)
Jika kinerja model terlalu banyak menurun, orang dapat menyetelnya untuk beberapa zaman untuk memulihkan kinerja model float.
import torch
model . train ()
for batch_idx , ( data , target ) in enumerate ( train_loader ):
data , target = data . to ( device ), target . to ( device )
optimizer . zero_grad ()
output = model ( data ). dequantize ()
loss = torch . nn . functional . nll_loss ( output , target )
loss . backward ()
optimizer . step ()4. Bobot bobot bilangan bulat
Saat membekukan model, bobot mengambangnya digantikan oleh bobot integer terkuantisasi.
from optimum . quanto import freeze
freeze ( model )5. Serialize Model Terkuantisasi
Bobot model terkuantisasi dapat diserialisasi ke state_dict , dan disimpan ke file. Baik pickle dan safetensors (disarankan) didukung.
from safetensors . torch import save_file
save_file ( model . state_dict (), 'model.safetensors' )Agar dapat memuat ulang bobot ini, Anda juga perlu menyimpan peta kuantisasi model terkuantisasi.
import json
from optimum . quanto import quantization_map
with open ( 'quantization_map.json' , 'w' ) as f :
json . dump ( quantization_map ( model ), f )5. Muat ulang model terkuantisasi
Model kuantisasi serial dapat dimuat ulang dari state_dict dan quantization_map menggunakan helper requantize . Perhatikan bahwa Anda perlu pertama -tama untuk membuat model kosong.
import json
from safetensors . torch import load_file
from optimum . quanto import requantize
state_dict = load_file ( 'model.safetensors' )
with open ( 'quantization_map.json' , 'r' ) as f :
quantization_map = json . load ( f )
# Create an empty model from your modeling code and requantize it
with torch . device ( 'meta' ):
new_model = ...
requantize ( new_model , state_dict , quantization_map , device = torch . device ( 'cuda' ))Silakan merujuk ke contoh untuk instantiasi alur kerja itu.
Di jantung Quanto adalah subkelas tensor yang sesuai dengan:
Untuk tipe tujuan floating-point, pemetaan dilakukan oleh pemeran Pytorch asli (yaitu Tensor.to() ).
Untuk jenis tujuan integer, pemetaan adalah operasi pembulatan sederhana (yaitu torch.round() ).
Tujuan dari proyeksi ini adalah untuk meningkatkan keakuratan konversi dengan meminimalkan jumlah:
Proyeksi ini simetris per-tensor atau per-saluran untuk int8 dan float8 , dan affine kelompok-bijaksana (dengan shift atau 'nol-point') untuk bitwidth yang lebih rendah.
Salah satu manfaat menggunakan representasi bitwidth yang lebih rendah adalah Anda akan dapat memanfaatkan operasi yang dipercepat untuk jenis tujuan, yang biasanya lebih cepat daripada yang setara dengan presisi yang lebih tinggi.
Quanto tidak mendukung konversi tensor menggunakan tipe tujuan campuran.
Quanto menyediakan mekanisme generik untuk menggantikan modul torch dengan modul optimum-quanto yang dapat memproses tensor kuanto.
Modul optimum-quanto secara dinamis mengubah bobotnya sampai model dibekukan, yang sedikit memperlambat inferensi tetapi diperlukan jika model perlu disetel.
Bobot biasanya dikuantisasi per-saluran sepanjang dimensi pertama (fitur output).
Bias tidak dikonversi untuk mempertahankan keakuratan operasi addmm yang khas.
Penjelasan: Agar konsisten dengan operasi aritmatika yang tidak kuantisasi, bias perlu dikuantisasi dengan skala yang sama dengan produk dari skala input dan berat badan, yang mengarah ke skala yang sangat kecil, dan sebaliknya membutuhkan bitwidth yang sangat tinggi untuk menghindari kliping. Biasanya, dengan input dan bobot int8 , bias perlu dikuantisasi dengan setidaknya 12 bit, yaitu di int16 . Karena sebagian besar bias hari ini float16 , ini adalah buang -buang waktu.
Aktivasi secara dinamis dikuantisasi per sensor menggunakan skala statis (default ke kisaran [-1, 1] ).
Untuk menjaga akurasi, model perlu dikalibrasi untuk mengevaluasi skala aktivasi terbaik (menggunakan momentum).
Modul berikut dapat dikuantisasi:
Aktivasi selalu dikuantisasi per tensor karena sebagian besar operasi aljabar linier dalam grafik model tidak kompatibel dengan input per-sumbu: Anda tidak dapat menambahkan angka yang tidak diekspresikan dalam basis yang sama ( you cannot add apples and oranges ).
Bobot yang terlibat dalam multiplikasi matriks, sebaliknya, selalu dikuantisasi di sepanjang sumbu pertama mereka, karena semua fitur output dievaluasi secara independen satu sama lain.
Output dari multiplikasi matriks terkuantisasi akan selalu dequantized, bahkan jika aktivasi dikuantisasi, karena:
int32 atau float32 ) daripada bitwidth aktivasi (biasanya int8 atau float8 ),float . Kuantisasi aktivasi per tensor ke int8 dapat menyebabkan kesalahan kuantisasi yang serius jika tensor yang sesuai berisi nilai outlier yang besar. Biasanya, ini akan menyebabkan tensor terkuantisasi dengan sebagian besar nilai diatur ke nol (kecuali outlier).
Solusi yang mungkin untuk mengatasi masalah itu adalah 'menghaluskan' aktivasi secara statis seperti yang diilustrasikan oleh Smoothquant. Anda dapat menemukan skrip untuk menghaluskan beberapa arsitektur model di bawah eksternal/smoothquant.
Opsi yang lebih baik adalah mewakili aktivasi menggunakan float8 .


