optimum quanto
release: 0.2.6
?最佳量子是最佳的pytorch量化后端。
它的设计具有多功能性和简单性:
weight_only和? safetensors ,功能尚未实现:
简而言之:
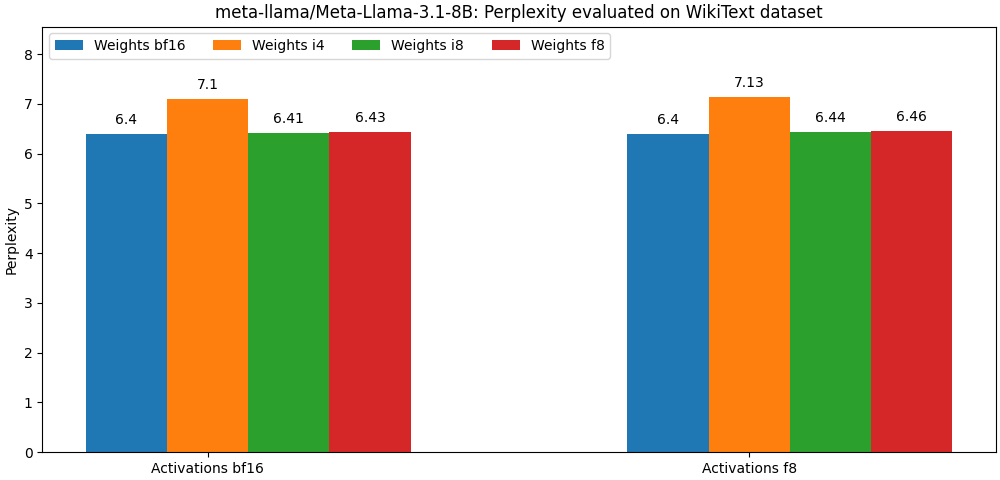
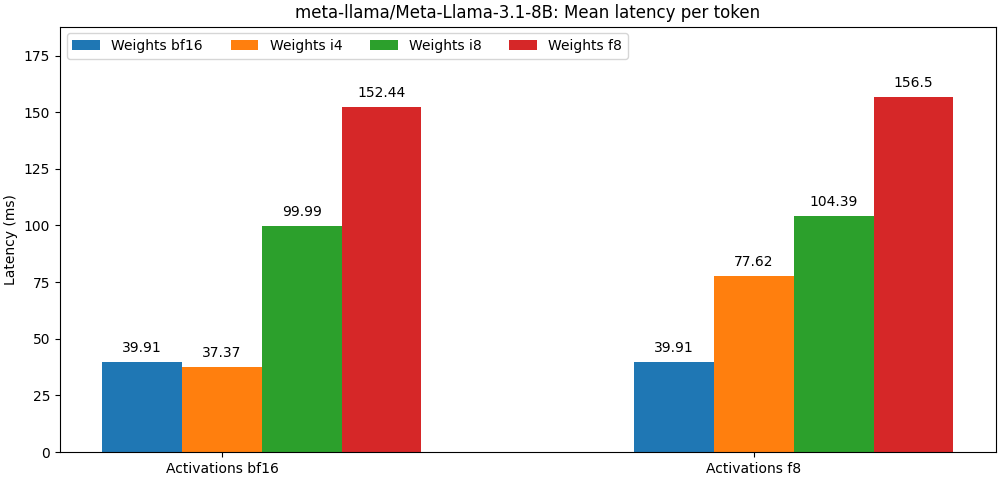
int8 / float8权重和float8激活编辑的型号非常接近Full Percision型号,下面的段落只是一个例子。请参阅bench文件夹,以获取每个模型用例详细结果。
最佳量化可作为PIP包装。
pip install optimum-quantooptimum-quanto提供了辅助类,以量化,保存和重新加载拥抱面部量化模型。
第一步是量化模型
from transformers import AutoModelForCausalLM
from optimum . quanto import QuantizedModelForCausalLM , qint4
model = AutoModelForCausalLM . from_pretrained ( 'meta-llama/Meta-Llama-3-8B' )
qmodel = QuantizedModelForCausalLM . quantize ( model , weights = qint4 , exclude = 'lm_head' )注意:该模型量化权重将被冷冻。如果您想让它们未能训练以训练它们,则需要使用optimum.quanto.quantize 。直接量化。
可以使用save_pretrained保存量化的模型:
qmodel . save_pretrained ( './Llama-3-8B-quantized' )以后可以使用from_pretrained重新加载:
from optimum . quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM . from_pretrained ( 'Llama-3-8B-quantized' )您可以量化扩散器管道中的任何子模型,然后在另一个管道中无缝包含它们。
在这里,我们量化了Pixart管道的transformer 。
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel , qfloat8
model = PixArtTransformer2DModel . from_pretrained ( "PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" , subfolder = "transformer" )
qmodel = QuantizedPixArtTransformer2DModel . quantize ( model , weights = qfloat8 )
qmodel . save_pretrained ( "./pixart-sigma-fp8" )后来,我们可以重新加载量化的模型并重新创建管道:
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel
transformer = QuantizedPixArtTransformer2DModel . from_pretrained ( "./pixart-sigma-fp8" )
transformer . to ( device = "cuda" )
pipe = PixArtSigmaPipeline . from_pretrained (
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" ,
transformer = None ,
torch_dtype = torch . float16 ,
). to ( "cuda" )
pipe . transformer = transformer 使用低级量子API时要记住的一件事是,默认模型权重是动态量化的:必须进行明确的调用以“冻结”量化的权重。
典型的量化工作流将包括以下步骤:
1。量化
第一步将标准浮点模型转换为动态量化的模型。
from optimum . quanto import quantize , qint8
quantize ( model , weights = qint8 , activations = qint8 )在此阶段,仅修改模型的推断以动态量化权重。
2。校准(如果未量化激活,可选)
Quanto支持校准模式,该模式允许在通过量化模型传递代表样品的同时记录激活范围。
from optimum . quanto import Calibration
with Calibration ( momentum = 0.9 ):
model ( samples )这会自动激活量化模块中激活的量化。
3。曲调,又称量化训练(可选)
如果模型的性能过多,则可以将其调整为一些时代以恢复浮点模型性能。
import torch
model . train ()
for batch_idx , ( data , target ) in enumerate ( train_loader ):
data , target = data . to ( device ), target . to ( device )
optimizer . zero_grad ()
output = model ( data ). dequantize ()
loss = torch . nn . functional . nll_loss ( output , target )
loss . backward ()
optimizer . step ()4。冻结整数重量
冷冻模型时,其浮子重量将被量化的整数重量所取代。
from optimum . quanto import freeze
freeze ( model )5。序列化量化模型
量化的模型权重可以序列化为state_dict ,并保存到文件中。支持pickle和safetensors (推荐)。
from safetensors . torch import save_file
save_file ( model . state_dict (), 'model.safetensors' )为了能够重新加载这些权重,您还需要存储量化的模型量化图。
import json
from optimum . quanto import quantization_map
with open ( 'quantization_map.json' , 'w' ) as f :
json . dump ( quantization_map ( model ), f )5。重新加载量化的模型
可以使用requantize助手从state_dict和quantization_map map重新加载序列化的量化模型。请注意,您需要首先实例化空模型。
import json
from safetensors . torch import load_file
from optimum . quanto import requantize
state_dict = load_file ( 'model.safetensors' )
with open ( 'quantization_map.json' , 'r' ) as f :
quantization_map = json . load ( f )
# Create an empty model from your modeling code and requantize it
with torch . device ( 'meta' ):
new_model = ...
requantize ( new_model , state_dict , quantization_map , device = torch . device ( 'cuda' ))请参阅示例以获取该工作流程的实例。
Quanto的核心是张量子类,与:
对于浮点目的地类型,映射由本机Pytorch Cast(即Tensor.to() )完成。
对于整数目标类型,映射是一个简单的圆形操作(即torch.round() )。
预测的目的是通过最大程度地减少以下数量来提高转换的准确性:
该投影是int8和float8的对称性或每通道,对于较低的位宽,则是对群的仿射(具有偏移或“零点”)。
使用较低宽度表示的好处之一是,您将能够利用目标类型的加速操作,通常比其更高的精度等效物更快。
Quanto不支持使用混合目的地类型的张量转换。
Quanto提供了一种通用机制,可以通过能够处理定量张量optimum-quanto模块替换torch模块。
optimum-quanto模块会动态转换其权重,直到模型被冷冻为止,这会减慢推理,但如果需要调整模型,则需要。
权重通常沿着第一维(输出功能)进行量化。
偏差未转换以保持典型的addmm操作的准确性。
说明:要与未量化的算术操作一致,需要用等于输入和重量尺度的乘积的量表进行量化,这会导致较小的尺度,相反,需要一个非常高的位宽度才能避免剪接。通常,使用int8输入和权重,需要使用至少12位量化偏差,即int16中的偏差。由于今天的大多数偏见是float16 ,所以这是浪费时间。
使用静态尺度(默认为[-1, 1]范围)动态量化活性。
为了保持准确性,需要校准模型以评估最佳的激活量表(使用动量)。
可以量化以下模块:
激活始终是量化的,因为模型图中的大多数线性代数操作与每轴输入不兼容:您只是无法添加在同一基础上未表达的数字( you cannot add apples and oranges )。
相反,矩阵乘法涉及的权重始终沿其第一个轴进行量化,因为所有输出特征均相互独立评估。
无论如何,即使激活进行了量化,量化矩阵乘法的输出也将始终被取消,因为:
int32或float8 ),以更高的位宽(通常为int8或float32 )表示。float偏见结合在一起。如果相应的张量包含较大的异常值值,则对int8进行量化激活可能会导致严重的量化误差。通常,这将导致量化的张量,其中大多数值设置为零(离群值除外)。
解决该问题的一种可能解决方案是“平滑”在静态上“平滑”激活,如SpooterQuant所示。您可以找到一个脚本,以使某些模型体系结构在外部/平滑方面平滑。
一个更好的选择是使用float8表示激活。


