optimum quanto
release: 0.2.6
؟ Optimum Quanto هو الواجهة الخلفية لقياس الكميات Pytorch إلى الأمثل.
لقد تم تصميمه مع الأخذ في الاعتبار التنوع والبساطة:
weight_only و؟ safetensors ،الميزات التي لم يتم تنفيذها بعد:
باختصار:
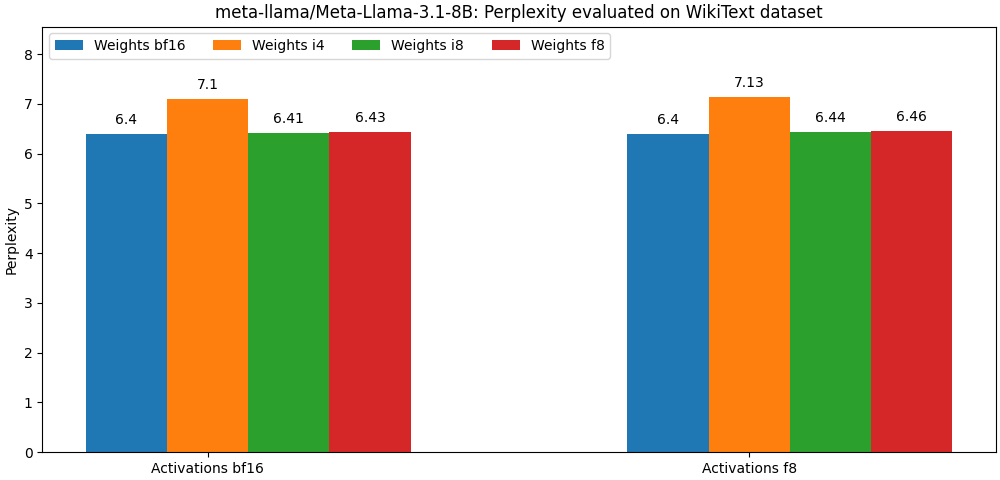
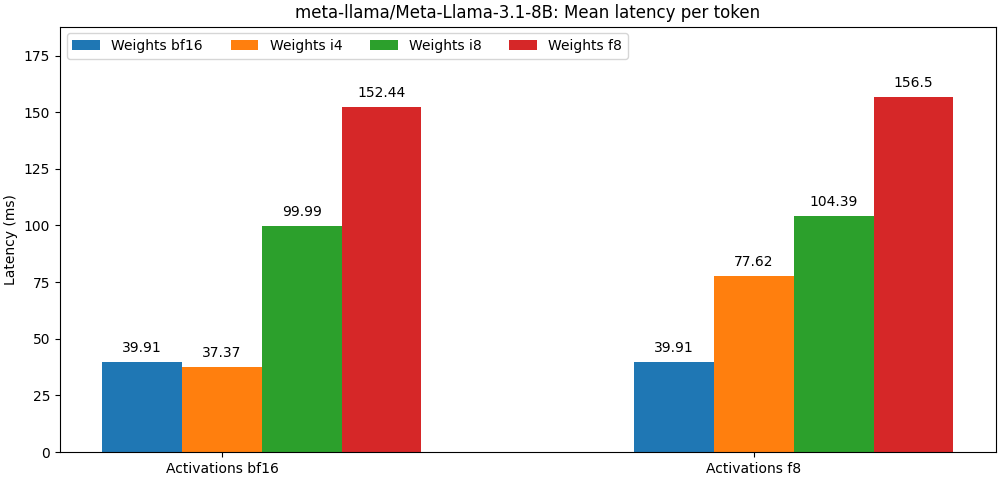
int8 / float8 وتفعيل float8 قريبة جدًا من النماذج الدقيقة الكاملة ، الفقرة أدناه هي مجرد مثال. يرجى الرجوع إلى مجلد bench للحصول على نتائج مفصلة لكل حالة استخدام للنموذج.
يتوفر الكمية الأمثل كحزمة PIP.
pip install optimum-quanto يوفر optimum-quanto دروسًا مساعدًا لتوفير وتوفير وإعادة تحميل النماذج الكمية المعانقة.
الخطوة الأولى هي تحديد النموذج
from transformers import AutoModelForCausalLM
from optimum . quanto import QuantizedModelForCausalLM , qint4
model = AutoModelForCausalLM . from_pretrained ( 'meta-llama/Meta-Llama-3-8B' )
qmodel = QuantizedModelForCausalLM . quantize ( model , weights = qint4 , exclude = 'lm_head' ) ملاحظة: سيتم تجميد الأوزان الكمية النموذجية. إذا كنت ترغب في إبقائهم غير متجانسين لتدريبهم ، فأنت بحاجة إلى استخدام optimum.quanto.quantize .
يمكن حفظ النموذج الكمي باستخدام save_pretrained :
qmodel . save_pretrained ( './Llama-3-8B-quantized' ) يمكن إعادة تحميله لاحقًا باستخدام from_pretrained :
from optimum . quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM . from_pretrained ( 'Llama-3-8B-quantized' )يمكنك تحديد أي من النماذج الفرعية داخل خط أنابيب الناشرون وتضمينها بسلاسة لاحقًا في خط أنابيب آخر.
نحن هنا نقوم بتكليف transformer خط أنابيب Pixart .
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel , qfloat8
model = PixArtTransformer2DModel . from_pretrained ( "PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" , subfolder = "transformer" )
qmodel = QuantizedPixArtTransformer2DModel . quantize ( model , weights = qfloat8 )
qmodel . save_pretrained ( "./pixart-sigma-fp8" )في وقت لاحق ، يمكننا إعادة تحميل النموذج الكمي وإعادة إنشاء خط الأنابيب:
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel
transformer = QuantizedPixArtTransformer2DModel . from_pretrained ( "./pixart-sigma-fp8" )
transformer . to ( device = "cuda" )
pipe = PixArtSigmaPipeline . from_pretrained (
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" ,
transformer = None ,
torch_dtype = torch . float16 ,
). to ( "cuda" )
pipe . transformer = transformer هناك شيء واحد يجب وضعه في الاعتبار عند استخدام API Quanto ذات المستوى المنخفض هو أن الأوزان ذات النماذج الافتراضية يتم تقديرها بشكل ديناميكي: يجب إجراء مكالمة صريحة لتجميد الأوزان الكمية.
يتكون سير العمل الكمي النموذجي من الخطوات التالية:
1. كمية
تقوم الخطوة الأولى بتحويل نموذج تعويم قياسي إلى نموذج كمي ديناميكي.
from optimum . quanto import quantize , qint8
quantize ( model , weights = qint8 , activations = qint8 )في هذه المرحلة ، يتم تعديل استنتاج النموذج فقط لتوظيف الأوزان ديناميكيًا.
2. معايرة (اختياري إذا لم تكن التنشيطات كمية)
يدعم Quanto وضع المعايرة الذي يسمح بتسجيل نطاقات التنشيط مع تمرير عينات تمثيلية من خلال النموذج الكمي.
from optimum . quanto import Calibration
with Calibration ( momentum = 0.9 ):
model ( samples )هذا ينشط تلقائيا تقدير التنشيط في الوحدات الكمية.
3. اللحن ، ويعرف أيضًا باسم التدريب الكمي المدرك (اختياري)
إذا كان أداء النموذج يتدهور أكثر من اللازم ، فيمكن للمرء أن يربحه لعدد قليل من الحقائب لاستعادة أداء طراز Float.
import torch
model . train ()
for batch_idx , ( data , target ) in enumerate ( train_loader ):
data , target = data . to ( device ), target . to ( device )
optimizer . zero_grad ()
output = model ( data ). dequantize ()
loss = torch . nn . functional . nll_loss ( output , target )
loss . backward ()
optimizer . step ()4. تجميد الأوزان العددية
عند تجميد النموذج ، يتم استبدال أوزانه العائمة بأوزان عدد صحيح كمي.
from optimum . quanto import freeze
freeze ( model )5. تسلسل النموذج الكمي
يمكن تسلسل الأوزان النماذج الكمية إلى state_dict ، وحفظها في ملف. يتم دعم كل من pickle و safetensors (الموصى به).
from safetensors . torch import save_file
save_file ( model . state_dict (), 'model.safetensors' )من أجل أن تكون قادرًا على إعادة تحميل هذه الأوزان ، تحتاج أيضًا إلى تخزين خريطة قياس الكميات الكمية.
import json
from optimum . quanto import quantization_map
with open ( 'quantization_map.json' , 'w' ) as f :
json . dump ( quantization_map ( model ), f )5. إعادة تحميل نموذج كمي
يمكن إعادة تحميل النموذج الكمي المسلسل من state_dict و quantization_map باستخدام المساعد requantize . لاحظ أنك تحتاج أولاً إلى إنشاء نموذج فارغ.
import json
from safetensors . torch import load_file
from optimum . quanto import requantize
state_dict = load_file ( 'model.safetensors' )
with open ( 'quantization_map.json' , 'r' ) as f :
quantization_map = json . load ( f )
# Create an empty model from your modeling code and requantize it
with torch . device ( 'meta' ):
new_model = ...
requantize ( new_model , state_dict , quantization_map , device = torch . device ( 'cuda' ))يرجى الرجوع إلى الأمثلة على إنشاءات سير العمل هذا.
في قلب Quanto توجد فئة فرعية موتر تتوافق مع:
بالنسبة لأنواع الوجهة العائمة ، يتم التعيين بواسطة Pytorch الأصلي (أي Tensor.to() ).
بالنسبة لأنواع الوجهة الصحيحة ، فإن التعيين هو عملية تقريب بسيطة (أي torch.round() ).
الهدف من الإسقاط هو زيادة دقة التحويل عن طريق تقليل عدد:
الإسقاط متماثل لكل مستتر أو كل قناة لـ int8 و float8 ، و Affine الجماعي (مع نوبة أو "نقطة صفر") لخفض النطاق.
واحدة من فوائد استخدام تمثيل العطوبة المنخفضة هو أنك ستتمكن من الاستفادة من العمليات المتسارعة لنوع الوجهة ، والتي عادة ما تكون أسرع من مكافئاتها العليا.
لا يدعم Quanto تحويل الموتر باستخدام أنواع الوجهة المختلطة.
يوفر Quanto آلية عامة لاستبدال وحدات torch بوحدات optimum-quanto القادر على معالجة الموترات الكمية.
تقوم وحدات optimum-quanto بتحويل أوزانها بشكل ديناميكي حتى يتم تجميد النموذج ، مما يبطئ الاستدلال قليلاً ولكن مطلوب إذا كان هناك حاجة إلى ضبط النموذج.
عادة ما يتم تحديد الأوزان لكل قناة على طول البعد الأول (ميزات الإخراج).
لا يتم تحويل التحيزات للحفاظ على دقة عملية addmm النموذجية.
Explanation: لكي تكون متسقة مع العمليات الحسابية غير المخصصة ، يجب أن تكون التحيزات كمية بمقياس يساوي منتج مقاييس المدخلات والوزن ، مما يؤدي إلى مقياس صغير يبعث على السخرية ، ويتطلب العكس من عرض عالي جدًا لتجنب القطع. عادةً ، مع مدخلات وأوزان int8 ، يجب أن تكون التحيزات كمية مع ما لا يقل عن 12 بت ، أي في int16 . نظرًا لأن معظم التحيزات float16 اليوم ، فهذا مضيعة للوقت.
يتم تقدير التنشيطات ديناميكيًا لكل مستتر باستخدام موازين ثابتة (الافتراضيات للنطاق [-1, 1] ).
للحفاظ على الدقة ، يجب معايرة النموذج لتقييم أفضل مقاييس التنشيط (باستخدام زخم).
يمكن تقدير الوحدات التالية:
يتم دائمًا تقدير التنشيطات لكل مستتر لأن معظم عمليات الجبر الخطي في رسم بياني نموذج لا تتوافق مع مدخلات لكل المحور: لا يمكنك ببساطة إضافة أرقام لا يتم التعبير عنها في نفس القاعدة ( you cannot add apples and oranges ).
على العكس من ذلك ، يتم تحديد الأوزان التي تشارك في مضاعفات المصفوفة ، على العكس من ذلك ، على طول المحور الأول ، لأن جميع ميزات الإخراج يتم تقييمها بشكل مستقل عن بعضها البعض.
سيتم تخلص من مخرجات مضاعفة المصفوفة الكمية على أي حال دائمًا ، حتى لو كانت التنشيطات كمية ، لأنه:
int32 أو float32 ) من Bitwidth التنشيط (عادةً int8 أو float8 ) ،float . يمكن أن تؤدي تحديد التنشيط لكل مستتر إلى int8 إلى أخطاء في تحديد كميات خطيرة إذا كانت الموترات المقابلة تحتوي على قيم خارجية كبيرة. عادة ، سيؤدي ذلك إلى توترات كمية مع ضبط معظم القيم على الصفر (باستثناء القيم المتطرفة).
يتمثل أحد الحلول الممكنة للتغلب على هذه المشكلة في "تنعيم" التنشيط بشكل ثابت كما هو موضح من قبل SmoothQuant. يمكنك العثور على نص لتنعيم بعض بنيات النماذج تحت خارجي/سلس.
الخيار الأفضل هو تمثيل التنشيط باستخدام float8 .


