optimum quanto
release: 0.2.6
? Optimum Quantoは、最適なPytorch Quantizationバックエンドです。
汎用性とシンプルさを念頭に置いて設計されています。
weight_onlyと互換性のあるシリアル化と? safetensors 、まだ実装されていない機能:
一言で言えば:
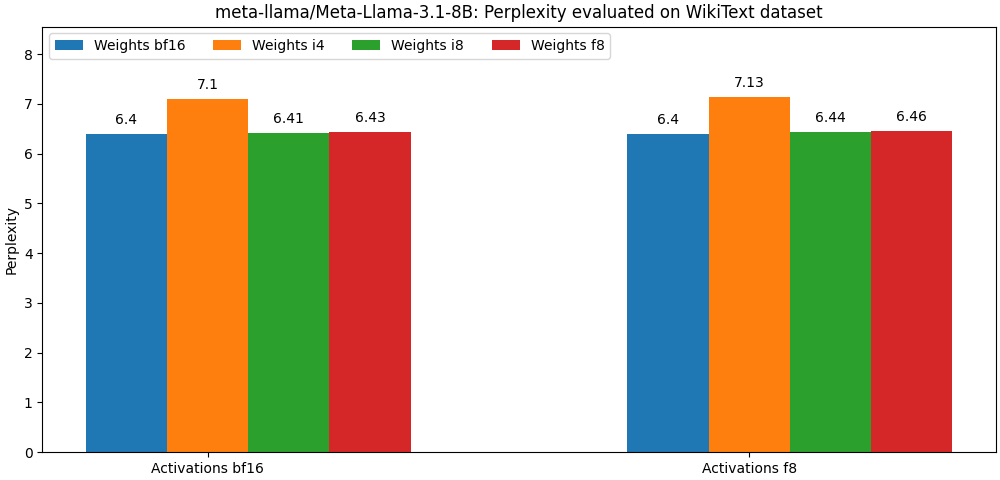
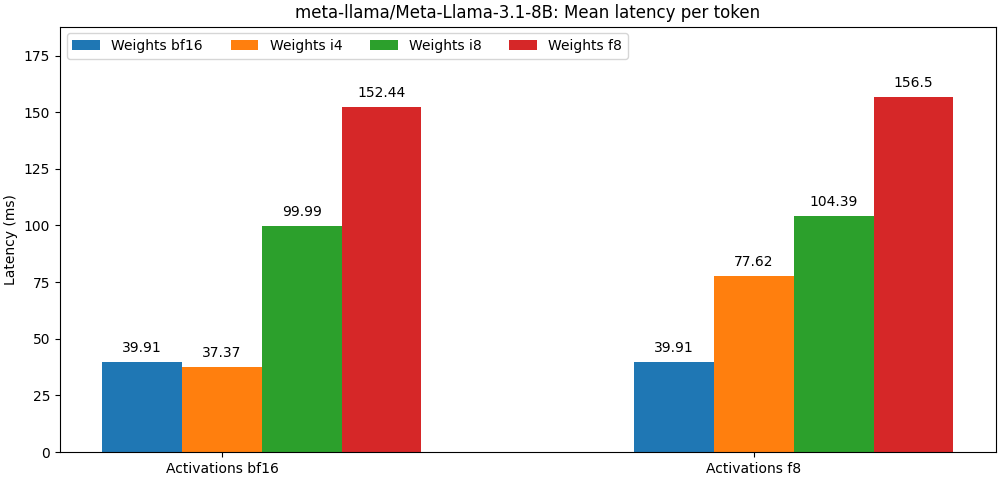
int8 / float8重みとfloat8の活性化でコンパイルされたモデルは、全精度モデルに非常に近い、以下の段落は単なる例です。モデルのユースケースごとの詳細な結果については、 benchフォルダーを参照してください。
Optimum Quantoは、PIPパッケージとして利用できます。
pip install optimum-quantooptimum-quantoフェイスの量子化モデルを量子化、保存、リロードするヘルパークラスを提供します。
最初のステップは、モデルを定量化することです
from transformers import AutoModelForCausalLM
from optimum . quanto import QuantizedModelForCausalLM , qint4
model = AutoModelForCausalLM . from_pretrained ( 'meta-llama/Meta-Llama-3-8B' )
qmodel = QuantizedModelForCausalLM . quantize ( model , weights = qint4 , exclude = 'lm_head' )注:モデルの量子重量は凍結されます。それらを訓練するためにそれらを未zenに保ちたい場合は、 optimum.quanto.quantize直接使用する必要があります。
量子化されたモデルは、 save_pretrainedを使用して保存できます。
qmodel . save_pretrained ( './Llama-3-8B-quantized' )後でfrom_pretrainedを使用してリロードできます。
from optimum . quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM . from_pretrained ( 'Llama-3-8B-quantized' )Diffusersパイプライン内のサブモデルを量子化し、後で別のパイプラインにシームレスに含めることができます。
ここでは、 Pixartパイプラインのtransformerを量子化します。
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel , qfloat8
model = PixArtTransformer2DModel . from_pretrained ( "PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" , subfolder = "transformer" )
qmodel = QuantizedPixArtTransformer2DModel . quantize ( model , weights = qfloat8 )
qmodel . save_pretrained ( "./pixart-sigma-fp8" )その後、量子化されたモデルをリロードして、パイプラインを再現できます。
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel
transformer = QuantizedPixArtTransformer2DModel . from_pretrained ( "./pixart-sigma-fp8" )
transformer . to ( device = "cuda" )
pipe = PixArtSigmaPipeline . from_pretrained (
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" ,
transformer = None ,
torch_dtype = torch . float16 ,
). to ( "cuda" )
pipe . transformer = transformer 低レベルのQuanto APIを使用する際に留意すべきことの1つは、デフォルトでモデルの重みが動的に量子化されることです。量子化された重みを「フリーズ」するために明示的な呼び出しを行う必要があります。
典型的な量子化ワークフローは、次の手順で構成されます。
1。量子化
最初のステップでは、標準のフロートモデルを動的に量子化されたモデルに変換します。
from optimum . quanto import quantize , qint8
quantize ( model , weights = qint8 , activations = qint8 )この段階では、モデルの推論のみが変更され、重みが動的に量子化されます。
2。キャリブレーション(アクティベーションが量子化されていない場合はオプション)
Quantoは、量子化されたモデルに代表的なサンプルを渡しながら、アクティベーション範囲を記録できるキャリブレーションモードをサポートします。
from optimum . quanto import Calibration
with Calibration ( momentum = 0.9 ):
model ( samples )これにより、量子化されたモジュールの活性化の量子化が自動的にアクティブ化されます。
3。チューン、別名Quantization-Aware-Training(オプション)
モデルのパフォーマンスがあまりにも低下している場合、フロートモデルのパフォーマンスを回復するために、いくつかのエポックを調整できます。
import torch
model . train ()
for batch_idx , ( data , target ) in enumerate ( train_loader ):
data , target = data . to ( device ), target . to ( device )
optimizer . zero_grad ()
output = model ( data ). dequantize ()
loss = torch . nn . functional . nll_loss ( output , target )
loss . backward ()
optimizer . step ()4。整数重量を凍結します
モデルを凍結すると、そのフロートの重量は量子化された整数重量に置き換えられます。
from optimum . quanto import freeze
freeze ( model )5。量子化されたモデルをシリアル化します
量子化されたモデルの重みは、 state_dictにシリアル化し、ファイルに保存できます。 pickleとsafetensors (推奨)の両方がサポートされています。
from safetensors . torch import save_file
save_file ( model . state_dict (), 'model.safetensors' )これらの重みをリロードできるようにするには、量子化されたモデル量子化マップも保存する必要があります。
import json
from optimum . quanto import quantization_map
with open ( 'quantization_map.json' , 'w' ) as f :
json . dump ( quantization_map ( model ), f )5.量子化されたモデルをリロードします
シリアル化された量子化されたモデルは、 requantize Helperを使用してstate_dictとquantization_mapからリロードできます。空のモデルをインスタンス化するには、最初に必要であることに注意してください。
import json
from safetensors . torch import load_file
from optimum . quanto import requantize
state_dict = load_file ( 'model.safetensors' )
with open ( 'quantization_map.json' , 'r' ) as f :
quantization_map = json . load ( f )
# Create an empty model from your modeling code and requantize it
with torch . device ( 'meta' ):
new_model = ...
requantize ( new_model , state_dict , quantization_map , device = torch . device ( 'cuda' ))そのワークフローの瞬時の例を参照してください。
Quantoの中心には、次のようなテンソルサブクラスがあります。
フローティングポイントの宛先タイプの場合、マッピングはネイティブのPytorchキャスト(つまりTensor.to() )によって行われます。
整数の宛先タイプの場合、マッピングは単純な丸め操作(つまりtorch.round() )です。
予測の目標は、次の数を最小化することにより、変換の精度を高めることです。
投影は、 int8およびfloat8テンソルあたりの対称またはチャネルごとに、および低幅の場合はグループごとのアフィン(シフトまたは「ゼロポイント」を使用)です。
下位幅の表現を使用する利点の1つは、宛先タイプの加速操作を利用できることです。これは、通常、高精度の等価物よりも速いです。
Quantoは、混合宛先タイプを使用してテンソルの変換をサポートしていません。
Quantoは、Quantoテンソルを処理できるoptimum-quantoモジュールにtorchモジュールを置き換える一般的なメカニズムを提供します。
optimum-quantoモジュールは、モデルが凍結するまで重量を動的に変換します。これは、推論を少し遅くしますが、モデルを調整する必要がある場合は必要です。
ウェイトは通常、最初の次元(出力機能)に沿ってチャネルごとに量子化されます。
典型的なaddmm操作の精度を維持するために、バイアスは変換されません。
説明:定量化されていない算術演算と一致するには、バイアスを入力スケールと重量スケールの積に等しいスケールで量子化する必要があります。通常、 int8入力と重みでは、バイアスは少なくとも12ビット、つまりint16で量子化する必要があります。ほとんどのバイアスは今日float16であるため、これは時間の無駄です。
活性化は、静的スケールを使用してテンソルごとに動的に量子化されます(デフォルトは範囲[-1, 1] )。
精度を維持するには、最適な活性化スケールを評価するためにモデルを調整する必要があります(運動量を使用)。
次のモジュールを定量化できます。
モデルグラフのほとんどの線形代数操作は、軸ごとの入力と互換性がないため、アクティベーションは常に計量されます。同じベースで表されない数値を追加することはできません( you cannot add apples and oranges )。
それどころか、マトリックスの乗算に伴う重みは、すべての出力機能が互いに独立して評価されるため、常に最初の軸に沿って量子化されます。
量子化されたマトリックスの乗算の出力は、とにかく、活性化が量子化されていても、常に不安定になります。
int8またはfloat8 )よりもはるかに高い幅(通常はint32またはfloat32 )で表されます。floatバイアスと組み合わせることができます。テンソルあたりの活性化をint8に量子化すると、対応するテンソルに大きな外れ値値が含まれている場合、深刻な量子化エラーが発生する可能性があります。通常、これは、ほとんどの値がゼロに設定された量子化されたテンソルにつながります(外れ値を除く)。
その問題を回避する可能性のある解決策は、SmoothQuantが示すように、活性化を静的に「スムーズ」することです。外部/smoothquantの下でいくつかのモデルアーキテクチャをスムーズにするためのスクリプトを見つけることができます。
より良いオプションは、 float8を使用してアクティベーションを表すことです。


