optimum quanto
release: 0.2.6
? Optimum Quanto는 Pytorch Quantization 백엔드입니다.
다양성과 단순성을 염두에두고 설계되었습니다.
weight_only 와 호환되는 직렬화? safetensors ,아직 구현되지 않은 기능 :
간단히 말해서 :
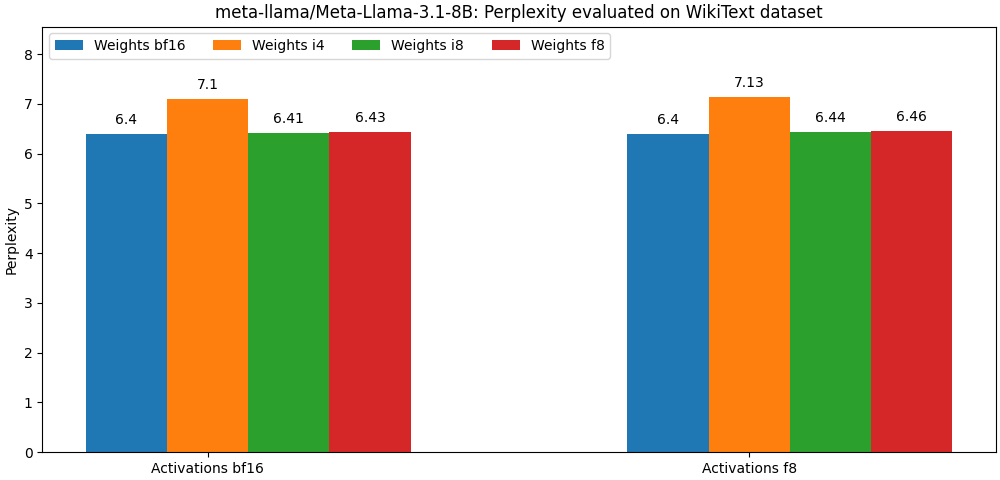
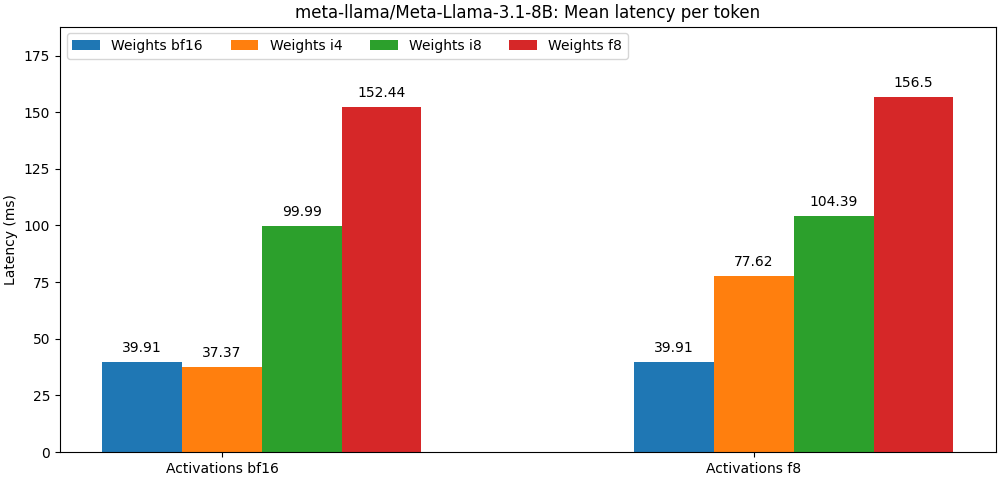
int8 / float8 가중치 및 float8 활성화로 컴파일 된 모델은 전체 정밀 모델에 매우 가깝습니다. 아래 단락은 예입니다. 모델의 사용 사례 당 자세한 결과는 bench 폴더를 참조하십시오.
Optimum Quanto는 PIP 패키지로 제공됩니다.
pip install optimum-quanto optimum-quanto 헬퍼 클래스를 제공하여 양자화 된 모델을 양자화, 저장 및 다시로드합니다.
첫 번째 단계는 모델을 정량화하는 것입니다
from transformers import AutoModelForCausalLM
from optimum . quanto import QuantizedModelForCausalLM , qint4
model = AutoModelForCausalLM . from_pretrained ( 'meta-llama/Meta-Llama-3-8B' )
qmodel = QuantizedModelForCausalLM . quantize ( model , weights = qint4 , exclude = 'lm_head' ) 참고 : 모델 양자화 된 가중치가 동결됩니다. 훈련하기 위해 끊어지지 않은 상태로 유지하려면 최적의 optimum.quanto.quantize 사용해야합니다.
양자화 된 모델은 save_pretrained 사용하여 저장할 수 있습니다.
qmodel . save_pretrained ( './Llama-3-8B-quantized' ) 나중에 from_pretrained 사용하여 다시로드 할 수 있습니다.
from optimum . quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM . from_pretrained ( 'Llama-3-8B-quantized' )디퓨저 파이프 라인 내부의 서브 모델을 정량화하고 나중에 다른 파이프 라인에 원활하게 포함시킬 수 있습니다.
여기서 우리는 Pixart 파이프 라인의 transformer 를 정량화합니다.
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel , qfloat8
model = PixArtTransformer2DModel . from_pretrained ( "PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" , subfolder = "transformer" )
qmodel = QuantizedPixArtTransformer2DModel . quantize ( model , weights = qfloat8 )
qmodel . save_pretrained ( "./pixart-sigma-fp8" )나중에 양자화 된 모델을 다시로드하고 파이프 라인을 재현 할 수 있습니다.
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel
transformer = QuantizedPixArtTransformer2DModel . from_pretrained ( "./pixart-sigma-fp8" )
transformer . to ( device = "cuda" )
pipe = PixArtSigmaPipeline . from_pretrained (
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" ,
transformer = None ,
torch_dtype = torch . float16 ,
). to ( "cuda" )
pipe . transformer = transformer 낮은 수준의 Quanto API를 사용할 때 명심해야 할 한 가지는 기본적으로 모델로 가중치가 동적으로 양자화된다는 것입니다.
일반적인 양자화 워크 플로는 다음 단계로 구성됩니다.
1. Quantize
첫 번째 단계는 표준 플로트 모델을 동적으로 양자화 된 모델로 변환합니다.
from optimum . quanto import quantize , qint8
quantize ( model , weights = qint8 , activations = qint8 )이 단계에서는 가중치를 동적으로 양자화하도록 모델의 추론 만 수정됩니다.
2. 교정 (활성화가 양자화되지 않은 경우 선택 사항)
Quanto는 양자화 된 모델을 통해 대표적인 샘플을 전달하면서 활성화 범위를 기록 할 수있는 보정 모드를 지원합니다.
from optimum . quanto import Calibration
with Calibration ( momentum = 0.9 ):
model ( samples )이것은 양자화 된 모듈에서 활성화의 양자화를 자동으로 활성화시킨다.
3. 튜닝, 일명 양자화 인식 훈련 (선택 사항)
모델의 성능이 너무 많이 저하되면 플로트 모델 성능을 복구하기 위해 몇 가지 에포크에 맞게 조정할 수 있습니다.
import torch
model . train ()
for batch_idx , ( data , target ) in enumerate ( train_loader ):
data , target = data . to ( device ), target . to ( device )
optimizer . zero_grad ()
output = model ( data ). dequantize ()
loss = torch . nn . functional . nll_loss ( output , target )
loss . backward ()
optimizer . step ()4. 정수 웨이트를 동결시킵니다
모델을 동결 할 때 플로트 가중치는 양자화 된 정수 무게로 대체됩니다.
from optimum . quanto import freeze
freeze ( model )5. 양자화 된 모델 직렬화
양자 모델 가중치는 state_dict 로 직렬화되어 파일에 저장 될 수 있습니다. pickle 과 safetensors (권장) 모두 지원됩니다.
from safetensors . torch import save_file
save_file ( model . state_dict (), 'model.safetensors' )이러한 가중치를 다시로드하려면 양자화 된 모델 양자화 맵을 저장해야합니다.
import json
from optimum . quanto import quantization_map
with open ( 'quantization_map.json' , 'w' ) as f :
json . dump ( quantization_map ( model ), f )5. 양자화 된 모델을 다시로드하십시오
직렬화 된 양자화 된 모델은 requantize 도우미를 사용하여 state_dict 및 quantization_map 에서 다시로드 될 수 있습니다. 먼저 빈 모델을 인스턴스화해야합니다.
import json
from safetensors . torch import load_file
from optimum . quanto import requantize
state_dict = load_file ( 'model.safetensors' )
with open ( 'quantization_map.json' , 'r' ) as f :
quantization_map = json . load ( f )
# Create an empty model from your modeling code and requantize it
with torch . device ( 'meta' ):
new_model = ...
requantize ( new_model , state_dict , quantization_map , device = torch . device ( 'cuda' ))해당 워크 플로의 인스턴스화에 대한 예제를 참조하십시오.
Quanto의 핵심에는 다음에 해당하는 텐서 서브 클래스가 있습니다.
부동 소수점 대상 유형의 경우, 매핑은 기본 Pytorch Cast (예 : Tensor.to() )에 의해 수행됩니다.
정수 대상 유형의 경우 매핑은 간단한 반올림 작업 (예 : torch.round() )입니다.
투영의 목표는 수를 최소화하여 변환의 정확도를 높이는 것입니다.
투영은 int8 및 float8 의 대칭 당 파마당 또는 채널 당 및 낮은 비트 width에 대한 그룹 별 아파이 인 (시프트 또는 '제로 포인트')입니다.
낮은 비트 전체 표현을 사용하면 이점 중 하나는 대상 유형에 대한 가속화 된 작업을 활용할 수 있다는 것입니다.
Quanto는 혼합 대상 유형을 사용하여 텐서의 변환을 지원하지 않습니다.
Quanto는 Quanto 텐서를 처리 할 수있는 optimum-quanto 모듈로 torch 모듈을 대체하는 일반적인 메커니즘을 제공합니다.
optimum-quanto 모듈은 모델이 동결 될 때까지 가중치를 동적으로 변환하여 추론이 약간 느려지지만 모델을 조정 해야하는 경우 필요합니다.
가중치는 일반적으로 첫 번째 차원 (출력 기능)을 따라 채널 당 양자화됩니다.
바이어스는 일반적인 addmm 작동의 정확도를 보존하기 위해 변환되지 않습니다.
설명 : 정의되지 않은 산술 작업과 일치하기 위해서는 편향이 입력 및 중량 스케일의 산물과 동일한 척도로 양자화되어야하며, 이는 말도 안되게 작은 규모로 이어지고 반대로 클리핑을 피하기 위해 매우 높은 비트 폭이 필요합니다. 일반적으로, int8 입력 및 가중치를 사용하면, int16 에서는 최소 12 비트, 즉 12 비트 이상의 양자화가 필요합니다. 대부분의 편견은 오늘날 float16 이므로 시간 낭비입니다.
활성화는 정적 스케일을 사용하여 동적으로 정량화됩니다 ( [-1, 1] 범위로의 기본값).
정확도를 보존하려면 최상의 활성화 척도 (운동량 사용)를 평가하려면 모델을 교정해야합니다.
다음 모듈은 양자화 될 수 있습니다.
모델 그래프의 대부분의 선형 대수 연산은 축당 입력과 호환되지 않기 때문에 활성화는 항상 양자화 된 당분자입니다. 단순히 동일한베이스에서 표현되지 않은 숫자를 추가 할 수 없습니다 ( you cannot add apples and oranges ).
모든 출력 기능은 서로 독립적으로 평가되기 때문에 매트릭스 곱셈에 관여 한 가중치는 항상 첫 번째 축을 따라 양자화됩니다.
양자화 된 매트릭스 곱셈의 출력은 활성화가 양자화 되더라도 다음과 같은 이유는 항상 비판 될 것이다.
int8 또는 float8 )보다 훨씬 높은 비트 폭 (일반적으로 int32 또는 float32 )으로 표현됩니다.float 바이어스와 결합 될 수 있습니다. 해당 텐서에 큰 특이점 값이 포함 된 경우 int8 에 대한 활성화 당의 활성화는 심각한 양자화 오차를 초래할 수 있습니다. 일반적으로 이것은 대부분의 값이 0으로 설정된 양자화 된 텐서로 이어집니다 (이상치 제외).
이 문제를 해결할 수있는 가능한 해결책은 SmoothQuant에 의해 설명 된 바와 같이 정적으로 활성화를 '매끄럽게'하는 것입니다. 외부/부드러운 퀘이트에서 일부 모델 아키텍처를 부드럽게하는 스크립트를 찾을 수 있습니다.
더 나은 옵션은 float8 사용하여 활성화를 나타내는 것입니다.


