optimum quanto
release: 0.2.6
? Optimal Quanto ist ein Pytorch -Quantisierungs -Backend für Optimum.
Es wurde im Hinblick auf Vielseitigkeit und Einfachheit konzipiert:
weight_only und? safetensors ,Merkmale noch implementiert:
Kurzgesagt:
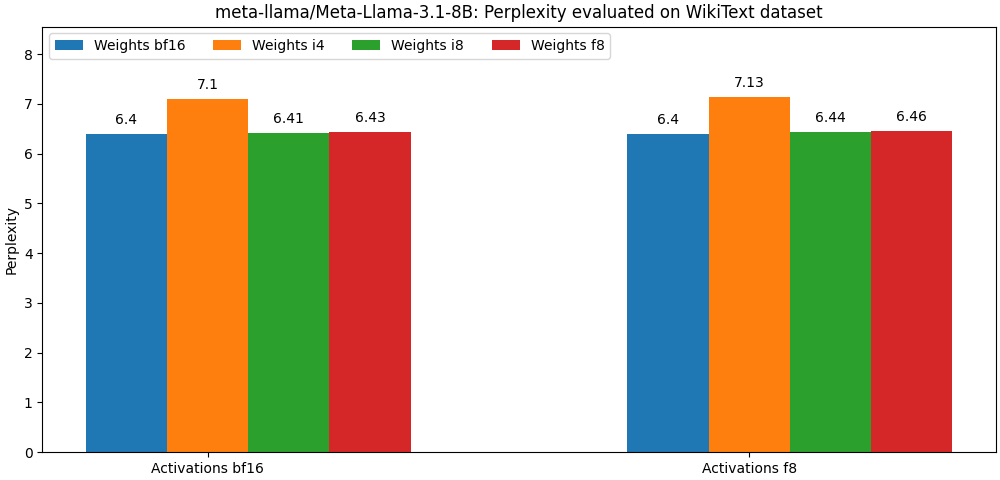
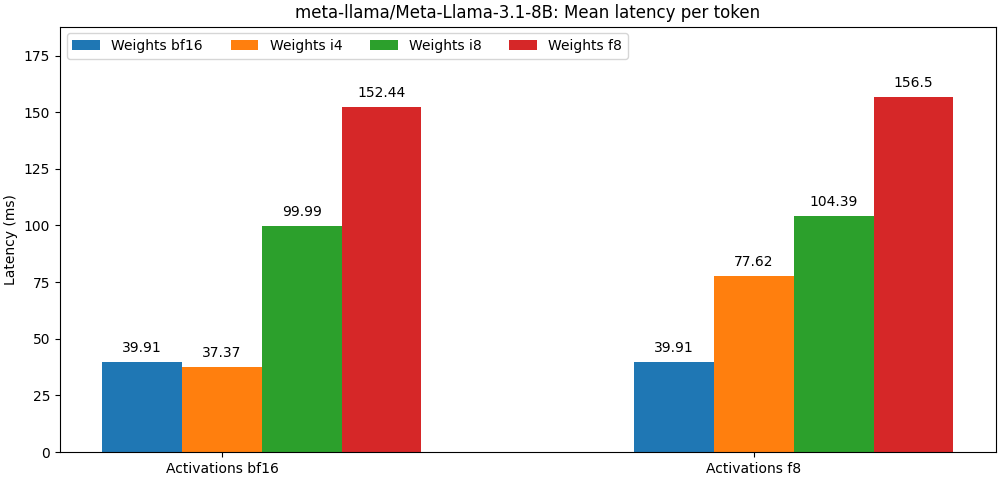
int8 / float8 Gewichten und float8 Aktivierungen zusammengestellt wurden, liegen sehr nahe an den Modellen der vollständigen Präzision. Der folgende Absatz ist nur ein Beispiel. Weitere detaillierte Ergebnisse pro US-Modell finden Sie im bench -Ordner.
Optimal Quanto ist als PIP -Paket erhältlich.
pip install optimum-quanto optimum-quanto bietet Helferklassen zum Quantisieren, Speichern und Nachladen von umarmenden Gesichtsmodellen.
Der erste Schritt besteht darin, das Modell zu quantisieren
from transformers import AutoModelForCausalLM
from optimum . quanto import QuantizedModelForCausalLM , qint4
model = AutoModelForCausalLM . from_pretrained ( 'meta-llama/Meta-Llama-3-8B' )
qmodel = QuantizedModelForCausalLM . quantize ( model , weights = qint4 , exclude = 'lm_head' ) HINWEIS: Die quantisierten Modellgewichte werden eingefroren. Wenn Sie sie nicht mehr trainieren möchten, müssen Sie optimum.quanto.quantize direkt verwenden.
Das quantisierte Modell kann mit save_pretrained gespeichert werden:
qmodel . save_pretrained ( './Llama-3-8B-quantized' ) Es kann später mit from_pretrained RELODED werden:
from optimum . quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM . from_pretrained ( 'Llama-3-8B-quantized' )Sie können alle Submodelle in einer Diffusoren -Pipeline quantisieren und später in einer anderen Pipeline nahtlos aufgenommen werden.
Hier quantisieren wir den transformer einer Pixart -Pipeline.
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel , qfloat8
model = PixArtTransformer2DModel . from_pretrained ( "PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" , subfolder = "transformer" )
qmodel = QuantizedPixArtTransformer2DModel . quantize ( model , weights = qfloat8 )
qmodel . save_pretrained ( "./pixart-sigma-fp8" )Später können wir das quantisierte Modell neu laden und die Pipeline neu erstellen:
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel
transformer = QuantizedPixArtTransformer2DModel . from_pretrained ( "./pixart-sigma-fp8" )
transformer . to ( device = "cuda" )
pipe = PixArtSigmaPipeline . from_pretrained (
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" ,
transformer = None ,
torch_dtype = torch . float16 ,
). to ( "cuda" )
pipe . transformer = transformer Eine Sache, die Sie bei der Verwendung der Quanto-API auf niedriger Ebene berücksichtigen sollten, ist, dass standardmäßige Modelle dynamisch quantifiziert werden: Es muss ein expliziter Anruf getätigt werden, um die quantisierten Gewichte einzufrieren.
Ein typischer Quantisierungs -Workflow würde aus den folgenden Schritten bestehen:
1.. Quantisieren
Der erste Schritt wandelt ein Standard -Float -Modell in ein dynamisch quantifiziertes Modell um.
from optimum . quanto import quantize , qint8
quantize ( model , weights = qint8 , activations = qint8 )In diesem Stadium wird nur die Inferenz des Modells so modifiziert, dass die Gewichte dynamisch quantisieren.
2. Kalibrieren (optional, wenn Aktivierungen nicht quantisiert werden)
Quanto unterstützt einen Kalibrierungsmodus, mit dem die Aktivierungsbereiche aufgezeichnet werden können, während repräsentative Proben über das quantisierte Modell übertragen werden.
from optimum . quanto import Calibration
with Calibration ( momentum = 0.9 ):
model ( samples )Dies aktiviert automatisch die Quantisierung der Aktivierungen in den quantisierten Modulen.
3. Tune, auch bekannt als quantisierungsbewusst (optional)
Wenn sich die Leistung des Modells zu stark beeinträchtigt, kann man es für einige Epochen einstellen, um die Leistung des Float -Modells wiederherzustellen.
import torch
model . train ()
for batch_idx , ( data , target ) in enumerate ( train_loader ):
data , target = data . to ( device ), target . to ( device )
optimizer . zero_grad ()
output = model ( data ). dequantize ()
loss = torch . nn . functional . nll_loss ( output , target )
loss . backward ()
optimizer . step ()4. Ganzzahl einfrieren Gewichte
Beim Einfrieren eines Modells werden seine Schwimmergewichte durch quantisierte Ganzzahlgewichte ersetzt.
from optimum . quanto import freeze
freeze ( model )5. Quantisiertes Modell serialisieren
Quantisierte Modelle Gewichte können in einem state_dict serialisiert und in einer Datei gespeichert werden. Sowohl pickle als auch safetensors (empfohlen) werden unterstützt.
from safetensors . torch import save_file
save_file ( model . state_dict (), 'model.safetensors' )Um diese Gewichte neu zu laden, müssen Sie auch die quantisierte Modellquantisierungskarte speichern.
import json
from optimum . quanto import quantization_map
with open ( 'quantization_map.json' , 'w' ) as f :
json . dump ( quantization_map ( model ), f )5. Ein quantisiertes Modell neu laden
Ein serialisiertes quantisiertes Modell kann mit dem requantize -Helfer aus einem state_dict und einer quantization_map neu geladen werden. Beachten Sie, dass Sie zuerst ein leeres Modell instanziieren müssen.
import json
from safetensors . torch import load_file
from optimum . quanto import requantize
state_dict = load_file ( 'model.safetensors' )
with open ( 'quantization_map.json' , 'r' ) as f :
quantization_map = json . load ( f )
# Create an empty model from your modeling code and requantize it
with torch . device ( 'meta' ):
new_model = ...
requantize ( new_model , state_dict , quantization_map , device = torch . device ( 'cuda' ))Bitte beachten Sie die Beispiele für Instanziationen dieses Workflows.
Im Herzen von Quanto befindet sich eine Tensor -Unterklasse, die entspricht:
Für die Ziellentypen für Gleitpunkte erfolgt die Mapping durch den nativen Pytorch-Cast (dh Tensor.to() ).
Für Ganzzahlzieltypen ist die Zuordnung ein einfacher Rundungsvorgang (dh torch.round() ).
Ziel der Projektion ist es, die Genauigkeit der Umwandlung zu erhöhen, indem die Anzahl der Anzahl minimiert wird:
Die Projektion ist symmetrisch pro Tensor oder prochannel für int8 und float8 sowie gruppenbezogene affine (mit einer Verschiebung oder "Nullpunkt" für die niedrigere Bitbreite.
Einer der Vorteile der Verwendung einer Darstellung mit niedrigerer Bitbreite besteht darin, dass Sie in der Lage sein können, beschleunigte Operationen für den Zieltyp zu nutzen, der in der Regel schneller ist als ihre höheren Präzisionsäquivalente.
Quanto unterstützt die Konvertierung eines Tensors unter Verwendung gemischter Zieltypen nicht.
Quanto bietet einen generischen Mechanismus, um torch durch optimum-quanto Module zu ersetzen, die Quanto-Tensoren verarbeiten können.
optimum-quanto Module wandeln ihre Gewichte dynamisch um, bis ein Modell eingefroren ist, was die Inferenz etwas verlangsamt, aber wenn das Modell eingestellt werden muss.
Die Gewichte werden normalerweise entlang der ersten Abmessung (Ausgangsmerkmale) pro-kanal quantisiert.
Verzerrungen werden nicht umgewandelt, um die Genauigkeit eines typischen addmm -Betriebs zu erhalten.
Erläuterung: Um mit den unangemessenen arithmetischen Operationen übereinzustimmen, müssten Verzerrungen mit einer Skala quantisiert werden, die dem Produkt der Eingangs- und Gewichtsskalen entspricht, was zu einer lächerlich kleinen Skala führt und umgekehrt eine sehr hohe Bitbreite erfordert, um ein Ausschneiden zu vermeiden. In der Regel müssten bei int8 -Eingängen und Gewichten Verzerrungen mit mindestens 12 Bits quantisiert werden, dh in int16 . Da die meisten Verzerrungen heute float16 sind, ist dies Zeitverschwendung.
Die Aktivierungen werden per Tensor unter Verwendung statischer Skalen dynamisch quantisiert (Standardeinstellungen zum Bereich [-1, 1] ).
Um die Genauigkeit zu erhalten, muss das Modell kalibriert werden, um die besten Aktivierungsskalen (unter Verwendung eines Impulses) zu bewerten.
Die folgenden Module können quantisiert werden:
Aktivierungen werden immer pro Tensor quantisiert, da die meisten linearen Algebra-Operationen in einem Modelldiagramm nicht mit Eingängen pro Achse kompatibel sind: Sie können einfach keine Zahlen hinzufügen, die nicht in derselben Basis ausgedrückt werden ( you cannot add apples and oranges ).
Gewichte, die an Matrix -Multiplikationen beteiligt sind, sind im Gegenteil immer entlang ihrer ersten Achse quantisiert, da alle Ausgangsmerkmale unabhängig voneinander bewertet werden.
Die Ausgänge einer quantisierten Matrixmultiplikation werden sowieso immer dequantisiert, auch wenn Aktivierungen quantisiert werden, weil:
int32 oder float32 ) ausgedrückt als die Aktivierungsbitbreite (typischerweise int8 oder float8 ).float kombiniert werden. Quantisierung von Aktivierungen pro Tensor zu int8 kann zu schwerwiegenden Quantisierungsfehlern führen, wenn die entsprechenden Tensoren große Ausreißerwerte enthalten. In der Regel führt dies zu quantisierten Tensoren mit den meisten auf Null gesetzten Werten (mit Ausnahme der Ausreißer).
Eine mögliche Lösung für dieses Problem besteht darin, die Aktivierungen statisch zu „glätten“, wie sie von Smoothquant veranschaulicht wird. Sie können ein Skript finden, um einige Modellarchitekturen unter externem/glattemquant zu glätten.
Eine bessere Option besteht darin, Aktivierungen mit float8 darzustellen.


