optimum quanto
release: 0.2.6
? Optimum Quanto est un backend de quantification Pytorch pour Optimum.
Il a été conçu avec la polyvalence et la simplicité à l'esprit:
weight_only et? safetensors ,Fonctionnalités à implémenter:
En un mot:
int8 / float8 et les activations float8 sont très proches des modèles de précision complète, Le paragraphe ci-dessous n'est qu'un exemple. Veuillez vous référer au dossier bench pour des résultats détaillés par cas d'utilisation du modèle.
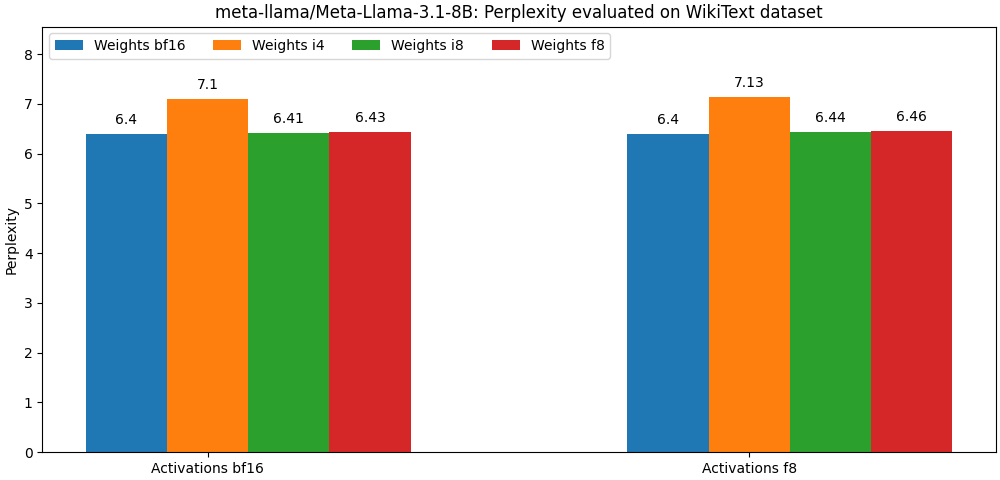
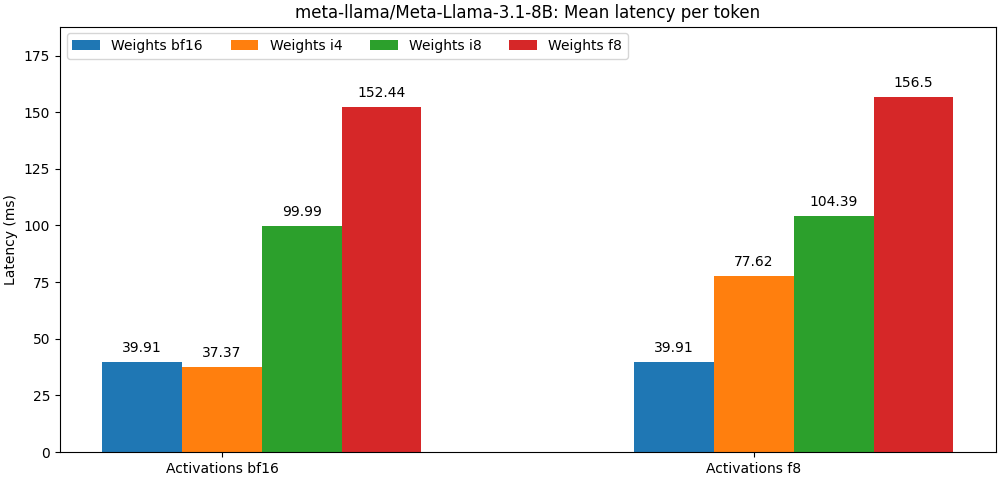
Optimum Quanto est disponible en tant que package PIP.
pip install optimum-quanto optimum-quanto fournit des classes d'assistance pour quantifier, sauver et recharger les modèles quantifiés de visage étreignant.
La première étape consiste à quantifier le modèle
from transformers import AutoModelForCausalLM
from optimum . quanto import QuantizedModelForCausalLM , qint4
model = AutoModelForCausalLM . from_pretrained ( 'meta-llama/Meta-Llama-3-8B' )
qmodel = QuantizedModelForCausalLM . quantize ( model , weights = qint4 , exclude = 'lm_head' ) Remarque: Les poids quantifiés du modèle seront gelés. Si vous souhaitez les garder non à dérogérer pour les former, vous devez utiliser optimum.quanto.quantize directement.
Le modèle quantifié peut être enregistré à l'aide de save_pretrained :
qmodel . save_pretrained ( './Llama-3-8B-quantized' ) Il peut être rechargé plus tard en utilisant from_pretrained :
from optimum . quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM . from_pretrained ( 'Llama-3-8B-quantized' )Vous pouvez quantifier l'un des sous-modèles à l'intérieur d'un pipeline Diffusers et les inclure de manière transparente plus tard dans un autre pipeline.
Ici, nous quantifions le transformer d'un pipeline Pixart .
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel , qfloat8
model = PixArtTransformer2DModel . from_pretrained ( "PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" , subfolder = "transformer" )
qmodel = QuantizedPixArtTransformer2DModel . quantize ( model , weights = qfloat8 )
qmodel . save_pretrained ( "./pixart-sigma-fp8" )Plus tard, nous pouvons recharger le modèle quantifié et recréer le pipeline:
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel
transformer = QuantizedPixArtTransformer2DModel . from_pretrained ( "./pixart-sigma-fp8" )
transformer . to ( device = "cuda" )
pipe = PixArtSigmaPipeline . from_pretrained (
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" ,
transformer = None ,
torch_dtype = torch . float16 ,
). to ( "cuda" )
pipe . transformer = transformer Une chose à garder à l'esprit lors de l'utilisation de l'API Quanto de faible niveau est que par défaut, les modèles sont quantifiés dynamiquement: un appel explicite doit être fait pour «geler» les poids quantifiés.
Un flux de travail de quantification typique comprendrait les étapes suivantes:
1. Quantifier
La première étape convertit un modèle flottant standard en un modèle quantifié dynamiquement.
from optimum . quanto import quantize , qint8
quantize ( model , weights = qint8 , activations = qint8 )À ce stade, seule l'inférence du modèle est modifiée pour quantifier dynamiquement les poids.
2. Calibrate (facultatif si les activations ne sont pas quantifiées)
Quanto prend en charge un mode d'étalonnage qui permet d'enregistrer les plages d'activation tout en passant des échantillons représentatifs via le modèle quantifié.
from optimum . quanto import Calibration
with Calibration ( momentum = 0.9 ):
model ( samples )Cela active automatiquement la quantification des activations dans les modules quantifiés.
3. Tune, alias la formation de quantification (facultative)
Si les performances du modèle se dégradent trop, on peut le régler pour quelques époques pour récupérer les performances du modèle flottant.
import torch
model . train ()
for batch_idx , ( data , target ) in enumerate ( train_loader ):
data , target = data . to ( device ), target . to ( device )
optimizer . zero_grad ()
output = model ( data ). dequantize ()
loss = torch . nn . functional . nll_loss ( output , target )
loss . backward ()
optimizer . step ()4. Freeze Integer Poids
Lors de la congélation d'un modèle, ses poids flottants sont remplacés par des poids entiers quantifiés.
from optimum . quanto import freeze
freeze ( model )5. Serializer le modèle quantifié
Les poids des modèles quantifiés peuvent être sérialisés dans un state_dict et enregistrés dans un fichier. Les pickle et safetensors (recommandés) sont pris en charge.
from safetensors . torch import save_file
save_file ( model . state_dict (), 'model.safetensors' )Afin de pouvoir recharger ces poids, vous devez également stocker la carte de quantification du modèle quantifié.
import json
from optimum . quanto import quantization_map
with open ( 'quantization_map.json' , 'w' ) as f :
json . dump ( quantization_map ( model ), f )5. Recharger un modèle quantifié
Un modèle quantifié sérialisé peut être rechargé à partir d'un state_dict et un quantization_map en utilisant l'assistance requantize . Notez que vous devez d'abord instancier un modèle vide.
import json
from safetensors . torch import load_file
from optimum . quanto import requantize
state_dict = load_file ( 'model.safetensors' )
with open ( 'quantization_map.json' , 'r' ) as f :
quantization_map = json . load ( f )
# Create an empty model from your modeling code and requantize it
with torch . device ( 'meta' ):
new_model = ...
requantize ( new_model , state_dict , quantization_map , device = torch . device ( 'cuda' ))Veuillez vous référer aux exemples d'instanciations de ce flux de travail.
Au cœur de Quanto se trouve une sous-classe tensor qui correspond à:
Pour les types de destination à virgule flottante, le mappage est effectué par la distribution pytorch native (c'est-à-dire Tensor.to() ).
Pour les types de destinations entiers, le mappage est une opération d'arrondi simple (c'est-à-dire torch.round() ).
Le but de la projection est d'augmenter la précision de la conversion en minimisant le nombre de:
La projection est symétrique par tenseur ou par canal pour int8 et float8 , et affine par groupe (avec un quart de travail ou un «point zéro») pour une largeur de bit inférieure.
L'un des avantages de l'utilisation d'une représentation de la largeur inférieure est que vous pourrez profiter des opérations accélérées pour le type de destination, ce qui est généralement plus rapide que leurs équivalents de précision plus élevés.
Quanto ne prend pas en charge la conversion d'un tenseur à l'aide de types de destinations mixtes.
Quanto fournit un mécanisme générique pour remplacer les modules torch par des modules optimum-quanto qui sont capables de traiter les tenseurs quantiques.
Les modules optimum-quanto convertissent dynamiquement leurs poids jusqu'à ce qu'un modèle soit gelé, ce qui ralentit un peu d'inférence mais est nécessaire si le modèle doit être réglé.
Les poids sont généralement quantifiés par canal le long de la première dimension (caractéristiques de sortie).
Les biais ne sont pas convertis pour préserver la précision d'une opération addmm typique.
Explication: Pour être cohérent avec les opérations arithmétiques non qualifiées, les biais devraient être quantifiés avec une échelle égale au produit des échelles d'entrée et de poids, ce qui conduit à une échelle ridiculement petite et nécessite à l'inverse une bidwidth très élevée pour éviter la coupe. En règle générale, avec les entrées et les poids int8 , les biais devraient être quantifiés avec au moins 12 bits, c'est-à-dire dans int16 . Étant donné que la plupart des biais sont aujourd'hui float16 , c'est une perte de temps.
Les activations sont quantifiées par tenseur à l'aide de échelles statiques (par défaut à la plage [-1, 1] ).
Pour préserver la précision, le modèle doit être calibré pour évaluer les meilleures échelles d'activation (en utilisant un moment).
Les modules suivants peuvent être quantifiés:
Les activations sont toujours quantifiées par tenseur car la plupart des opérations d'algèbre linéaires dans un graphique de modèle ne sont pas compatibles avec les entrées par axe: vous ne pouvez tout simplement pas ajouter de nombres qui ne sont pas exprimés dans la même base ( you cannot add apples and oranges ).
Les poids impliqués dans les multiplications de la matrice sont, au contraire, toujours quantifiés le long de leur premier axe, car toutes les caractéristiques de sortie sont évaluées indépendamment les unes des autres.
Les sorties d'une multiplication matricielle quantifiée seront de toute façon désactivées, même si les activations sont quantifiées, car:
int32 ou float32 ) que la largeur de bit d'activation (généralement int8 ou float8 ),float . La quantification des activations par tenseur à int8 peut entraîner de graves erreurs de quantification si les tenseurs correspondants contiennent de grandes valeurs aberrantes. En règle générale, cela conduira à des tenseurs quantifiés avec la plupart des valeurs définies sur zéro (sauf les valeurs aberrantes).
Une solution possible pour contourner ce problème consiste à «lisser» les activations statiquement comme illustré par Smoothand. Vous pouvez trouver un script pour lisser certaines architectures de modèle sous externe / lisse.
Une meilleure option consiste à représenter les activations à l'aide de float8 .


