optimum quanto
release: 0.2.6
? Optimum Quanto - это бэкэнд квантования Pytorch для оптимального.
Он был разработан с учетом универсальности и простоты:
weight_only и? safetensors ,Функции еще предстоит реализованы:
В двух словах:
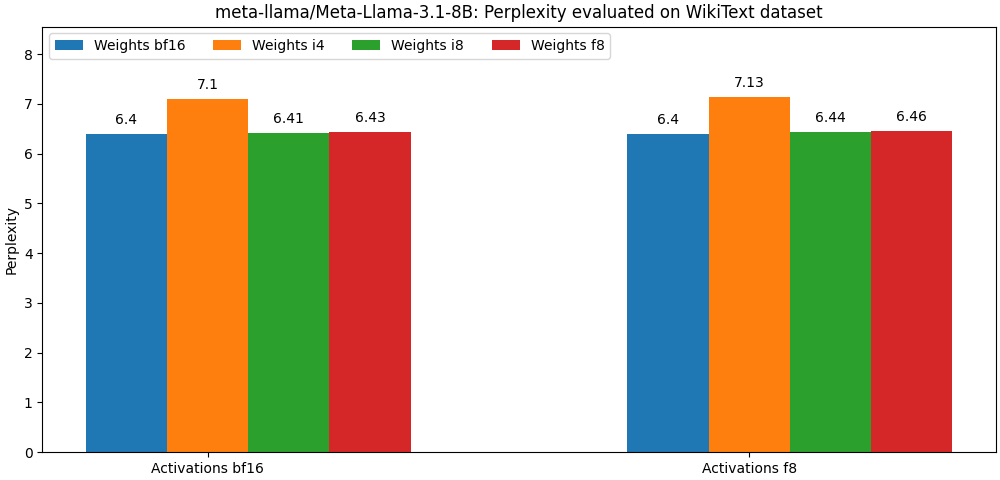
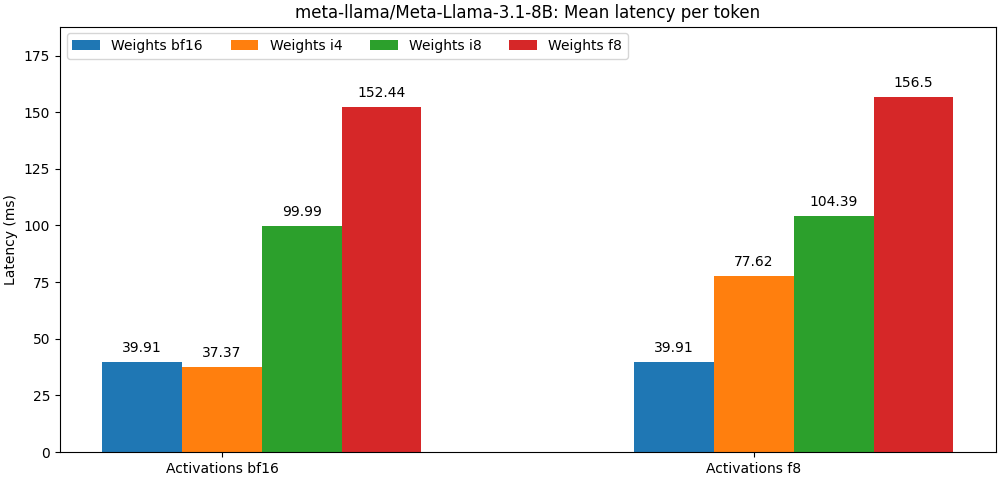
int8 / float8 и активациями float8 , очень близки к моделям с полной режиссером, Параграф ниже является лишь примером. Пожалуйста, обратитесь к папке bench для подробных результатов для использования модели.
Оптимальный Quanto доступен в виде пакета PIP.
pip install optimum-quanto optimum-quanto предоставляет вспомогательные классы для квантования, экономии и перезагрузки обнимающих квантованных моделей.
Первый шаг - квантовать модель
from transformers import AutoModelForCausalLM
from optimum . quanto import QuantizedModelForCausalLM , qint4
model = AutoModelForCausalLM . from_pretrained ( 'meta-llama/Meta-Llama-3-8B' )
qmodel = QuantizedModelForCausalLM . quantize ( model , weights = qint4 , exclude = 'lm_head' ) Примечание. Модель квантованные веса будут заморожены. Если вы хотите сохранить их незамерзкие, чтобы обучить их, вам нужно использовать optimum.quanto.quantize напрямую.
Квантовая модель можно сохранить с помощью save_pretrained :
qmodel . save_pretrained ( './Llama-3-8B-quantized' ) Позже он может быть перезагружен с помощью from_pretrained :
from optimum . quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM . from_pretrained ( 'Llama-3-8B-quantized' )Вы можете квантовать любое из подмоделей внутри трубопровода диффузоров и плавно включить их позже в другой трубопровод.
Здесь мы определяем transformer трубопровода Pixart .
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel , qfloat8
model = PixArtTransformer2DModel . from_pretrained ( "PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" , subfolder = "transformer" )
qmodel = QuantizedPixArtTransformer2DModel . quantize ( model , weights = qfloat8 )
qmodel . save_pretrained ( "./pixart-sigma-fp8" )Позже мы можем перезагрузить квантованную модель и воссоздать трубопровод:
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel
transformer = QuantizedPixArtTransformer2DModel . from_pretrained ( "./pixart-sigma-fp8" )
transformer . to ( device = "cuda" )
pipe = PixArtSigmaPipeline . from_pretrained (
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" ,
transformer = None ,
torch_dtype = torch . float16 ,
). to ( "cuda" )
pipe . transformer = transformer При использовании низкоуровневого Quanto API следует помнить о том, что по умолчанию веса моделей динамически квантованы: должен быть сделан явный вызов, чтобы «заморозить» квантовые веса.
Типичный рабочий процесс квантования будет состоять из следующих шагов:
1. квантовать
Первый шаг преобразует стандартную модель плавания в динамически квантовую модель.
from optimum . quanto import quantize , qint8
quantize ( model , weights = qint8 , activations = qint8 )На этом этапе только вывод модели модифицируется, чтобы динамически квантовать веса.
2. Калибровать (необязательно, если активации не являются квантовыми)
Quanto поддерживает режим калибровки, который позволяет записывать диапазоны активации при прохождении репрезентативных образцов через квантовую модель.
from optimum . quanto import Calibration
with Calibration ( momentum = 0.9 ):
model ( samples )Это автоматически активирует квантование активаций в квантованных модулях.
3. tune, aka-квантование-обучение (необязательно)
Если производительность модели слишком сильно ухудшается, можно настроить ее на несколько эпох, чтобы восстановить производительность модели поплавок.
import torch
model . train ()
for batch_idx , ( data , target ) in enumerate ( train_loader ):
data , target = data . to ( device ), target . to ( device )
optimizer . zero_grad ()
output = model ( data ). dequantize ()
loss = torch . nn . functional . nll_loss ( output , target )
loss . backward ()
optimizer . step ()4. Заморозить целые веса
При замерзании модели его веса поплавок заменяются квантованными целочисленными весами.
from optimum . quanto import freeze
freeze ( model )5. сериализуйте квантованную модель
Квантовые модели веса могут быть сериализованы на state_dict и сохранены в файл. Поддерживаются как pickle , так и safetensors (рекомендуемые).
from safetensors . torch import save_file
save_file ( model . state_dict (), 'model.safetensors' )Чтобы иметь возможность перезагрузить эти веса, вам также необходимо сохранить квантованную карту квантования модели.
import json
from optimum . quanto import quantization_map
with open ( 'quantization_map.json' , 'w' ) as f :
json . dump ( quantization_map ( model ), f )5. перезагрузить квантованную модель
Сериализованная квантовая модель может быть перезагружена из state_dict и quantization_map с использованием помощника requantize . Обратите внимание, что вам нужно сначала создать пустую модель.
import json
from safetensors . torch import load_file
from optimum . quanto import requantize
state_dict = load_file ( 'model.safetensors' )
with open ( 'quantization_map.json' , 'r' ) as f :
quantization_map = json . load ( f )
# Create an empty model from your modeling code and requantize it
with torch . device ( 'meta' ):
new_model = ...
requantize ( new_model , state_dict , quantization_map , device = torch . device ( 'cuda' ))Пожалуйста, обратитесь к примерам экземпляров этого рабочего процесса.
В основе кванто лежит тензорный подкласс, который соответствует:
Для типов назначения с плавающей точкой картирование выполняется нативным актерским составом (т.е. Tensor.to() ).
Для целочисленных типов назначения отображение представляет собой простую операцию округления (то есть torch.round() ).
Цель проекции состоит в том, чтобы повысить точность конверсии путем минимизации количества:
Проекция представляет собой симметричный для перспектива или для каждого канала для int8 и float8 , а также групповой аффинной (со сдвигом или «нулевой точкой») для более низкой битовой провайды.
Одним из преимуществ использования представления с более низкой прошивкой является то, что вы сможете воспользоваться преимуществами ускоренных операций для типа назначения, что обычно быстрее, чем их более высокие точные эквиваленты.
Quanto не поддерживает преобразование тензора с использованием смешанных типов назначения.
Quanto обеспечивает общий механизм для замены модулей torch optimum-quanto модулями, которые способны обрабатывать квантовые тензоры.
optimum-quanto модули кванто динамически преобразуют свои веса до тех пор, пока модель не заморожена, что немного замедляет вывод, но требуется, если модель нужно настроить.
Веса обычно определяются на канате вдоль первого измерения (выходные функции).
Предвзятость не преобразуется для сохранения точности типичной работы addmm .
Объяснение: Чтобы соответствовать неквалифицированным арифметическим операциям, предвзяты должны быть квантованы с помощью шкалы, равного продукту ввода и веса, что приводит к смехотворно небольшим масштабам, и наоборот требуется очень высокая битва, чтобы избежать обрезки. Как правило, с входами и весами int8 , предвзяты должны быть квантованы как минимум с 12 битами, т.е. в int16 . Поскольку большинство предвзятости сегодня float16 , это пустая трата времени.
Активации являются динамически квантовыми на тензор с использованием статических шкал (по умолчанию в диапазоне [-1, 1] ).
Чтобы сохранить точность, модель должна быть откалибрована для оценки лучших шкал активации (с использованием импульса).
Следующие модули могут быть квантованы:
Активации всегда являются квантовыми для для тензора, потому что большинство линейных операций алгебры в модельном графике не совместимы с входами на оси: вы просто не можете добавить числа, которые не выражаются в одной и той же базе ( you cannot add apples and oranges ).
Веса, связанные с умножением матрицы, напротив, всегда квантованы вдоль их первой оси, потому что все выходные функции оцениваются независимо друг от друга.
Выходы квантового умножения матрицы в любом случае всегда будут отказаны, даже если активации квантации, потому что:
int32 или float32 ), чем битовая проходная активация (обычно int8 или float8 ),float . Квантование активации на тензор до int8 может привести к серьезным ошибкам квантования, если соответствующие тензоры содержат большие выбросы. Как правило, это приведет к квантовым тензорам с большинством значений, установленных к нулю (кроме выбросов).
Возможное решение для решения этой проблемы состоит в том, чтобы «сгладить» активации статически, как показано с Smoothquant. Вы можете найти сценарий, чтобы сгладить некоторые модели архитектуры под внешней/плавной
Лучшим вариантом является представление активаций с использованием float8 .


