optimum quanto
release: 0.2.6
? O ideal do Quanta é um back -end de quantização de pytorch para ideal.
Foi projetado com versatilidade e simplicidade em mente:
weight_only e? safetensors ,Recursos ainda a serem implementados:
Em poucas palavras:
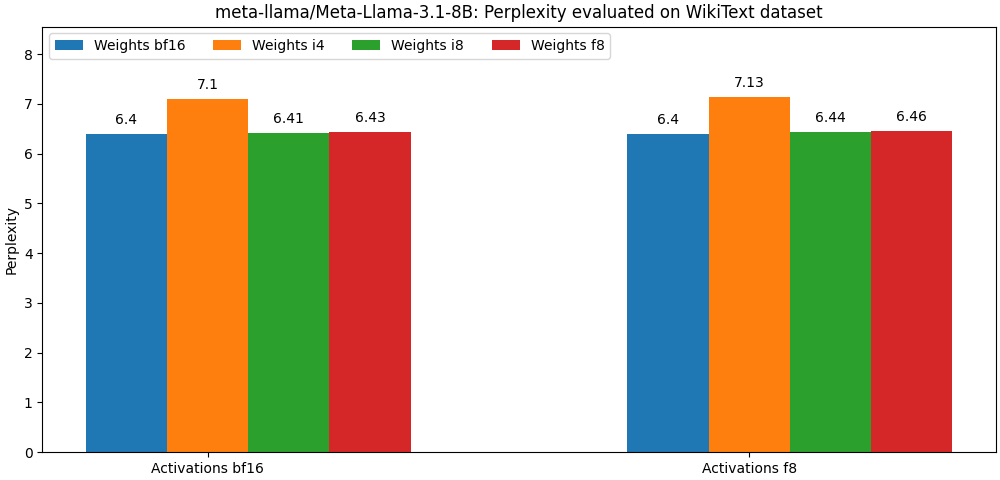
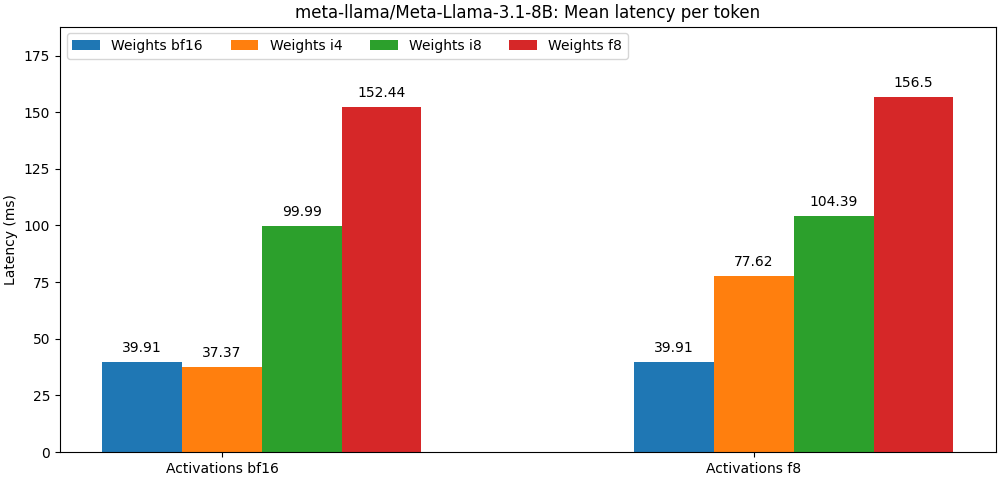
int8 / float8 e ativações float8 estão muito próximas dos modelos de precisão completa, O parágrafo abaixo é apenas um exemplo. Consulte a pasta de bench para obter resultados detalhados por caixa de uso do modelo.
O Optimum Quago está disponível como um pacote PIP.
pip install optimum-quanto optimum-quanto oferece classes auxiliares para quantizar, salvar e recarregar os modelos quantizados de rosto abraçando.
O primeiro passo é quantizar o modelo
from transformers import AutoModelForCausalLM
from optimum . quanto import QuantizedModelForCausalLM , qint4
model = AutoModelForCausalLM . from_pretrained ( 'meta-llama/Meta-Llama-3-8B' )
qmodel = QuantizedModelForCausalLM . quantize ( model , weights = qint4 , exclude = 'lm_head' ) NOTA: O modelo quantizado pesos será congelado. Se você deseja mantê -los descongelados para treiná -los, você precisa usar optimum.quanto.quantize diretamente.
O modelo quantizado pode ser salvo usando save_pretrained :
qmodel . save_pretrained ( './Llama-3-8B-quantized' ) Mais tarde, ele pode ser recarregado usando from_pretrained :
from optimum . quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM . from_pretrained ( 'Llama-3-8B-quantized' )Você pode quantizar qualquer um dos submodelos dentro de um pipeline de difusores e incluí -los perfeitamente mais tarde em outro pipeline.
Aqui quantizamos o transformer de um pipeline Pixart .
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel , qfloat8
model = PixArtTransformer2DModel . from_pretrained ( "PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" , subfolder = "transformer" )
qmodel = QuantizedPixArtTransformer2DModel . quantize ( model , weights = qfloat8 )
qmodel . save_pretrained ( "./pixart-sigma-fp8" )Mais tarde, podemos recarregar o modelo quantizado e recriar o pipeline:
from diffusers import PixArtTransformer2DModel
from optimum . quanto import QuantizedPixArtTransformer2DModel
transformer = QuantizedPixArtTransformer2DModel . from_pretrained ( "./pixart-sigma-fp8" )
transformer . to ( device = "cuda" )
pipe = PixArtSigmaPipeline . from_pretrained (
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS" ,
transformer = None ,
torch_dtype = torch . float16 ,
). to ( "cuda" )
pipe . transformer = transformer Uma coisa a ter em mente ao usar a API de gravação de baixo nível é que, por padrão, os pesos dos modelos são quantizados dinamicamente: uma chamada explícita deve ser feita para 'congelar' os pesos quantizados.
Um fluxo de trabalho de quantização típico consistiria nas seguintes etapas:
1. Quantize
A primeira etapa converte um modelo de flutuação padrão em um modelo quantizado dinamicamente.
from optimum . quanto import quantize , qint8
quantize ( model , weights = qint8 , activations = qint8 )Nesse estágio, apenas a inferência do modelo é modificada para quantizar dinamicamente os pesos.
2. Calibre (opcional se as ativações não forem quantizadas)
O quantsocola suporta um modo de calibração que permite registrar as faixas de ativação enquanto passam amostras representativas através do modelo quantizado.
from optimum . quanto import Calibration
with Calibration ( momentum = 0.9 ):
model ( samples )Isso ativa automaticamente a quantização das ativações nos módulos quantizados.
3. Tune, também conhecido como treinamento com consciência (opcional)
Se o desempenho do modelo degradar demais, pode -se ajustá -lo por algumas épocas para recuperar o desempenho do modelo de flutuação.
import torch
model . train ()
for batch_idx , ( data , target ) in enumerate ( train_loader ):
data , target = data . to ( device ), target . to ( device )
optimizer . zero_grad ()
output = model ( data ). dequantize ()
loss = torch . nn . functional . nll_loss ( output , target )
loss . backward ()
optimizer . step ()4. Freeze pesos inteiros
Ao congelar um modelo, seus pesos de flutuação são substituídos por pesos inteiros quantizados.
from optimum . quanto import freeze
freeze ( model )5. Modelo quantizado serializado
Os pesos dos modelos quantizados podem ser serializados para um state_dict e salvos em um arquivo. Os pickle e safetensors (recomendados) são suportados.
from safetensors . torch import save_file
save_file ( model . state_dict (), 'model.safetensors' )Para poder recarregar esses pesos, você também precisa armazenar o mapa de quantização do modelo quantizado.
import json
from optimum . quanto import quantization_map
with open ( 'quantization_map.json' , 'w' ) as f :
json . dump ( quantization_map ( model ), f )5. Recarregue um modelo quantizado
Um modelo quantizado serializado pode ser recarregado de um state_dict e um quantization_map usando o auxiliar requantize . Observe que você precisa primeiro instanciar um modelo vazio.
import json
from safetensors . torch import load_file
from optimum . quanto import requantize
state_dict = load_file ( 'model.safetensors' )
with open ( 'quantization_map.json' , 'r' ) as f :
quantization_map = json . load ( f )
# Create an empty model from your modeling code and requantize it
with torch . device ( 'meta' ):
new_model = ...
requantize ( new_model , state_dict , quantization_map , device = torch . device ( 'cuda' ))Consulte os exemplos para obter instanciações desse fluxo de trabalho.
No coração do 3, há uma subclasse tensor que corresponde a:
Para tipos de destino de ponto flutuante, o mapeamento é feito pelo elenco nativo de Pytorch (ou seja, Tensor.to() ).
Para tipos de destino inteiro, o mapeamento é uma operação de arredondamento simples (ou seja, torch.round() ).
O objetivo da projeção é aumentar a precisão da conversão, minimizando o número de:
A projeção é simétrica por tensor ou por canal para int8 e float8 , e afins em grupo (com um turno ou 'ponto zero') para menor largura de bits.
Um dos benefícios do uso de uma representação de baixa largura de bits é que você poderá tirar proveito das operações aceleradas para o tipo de destino, que é tipicamente mais rápido que seus equivalentes de precisão mais alta.
O quantia não suporta a conversão de um tensor usando tipos de destino misto.
O Quago fornece um mecanismo genérico para substituir os módulos torch por módulos optimum-quanto que são capazes de processar tensores de perto.
Os módulos optimum-quanto convertem dinamicamente seus pesos até que um modelo esteja congelado, o que diminui um pouco a inferência, mas é necessário se o modelo precisar ser ajustado.
Os pesos geralmente são quantizados por canal ao longo da primeira dimensão (recursos de saída).
Os vieses não são convertidos para preservar a precisão de uma operação típica addmm .
Explicação: Para ser consistente com as operações aritméticas não quantizadas, os vieses precisariam ser quantizados com uma escala igual ao produto das escalas de entrada e peso, o que leva a uma escala ridiculamente pequena e, inversamente, requer uma largura de bit muito alta para evitar o corte. Normalmente, com entradas e pesos int8 , os vieses precisariam ser quantizados com pelo menos 12 bits, ou seja, no int16 . Como a maioria dos vieses é hoje float16 , isso é uma perda de tempo.
As ativações são quantizadas dinamicamente por tensor usando escalas estáticas (padrão para o intervalo [-1, 1] ).
Para preservar a precisão, o modelo precisa ser calibrado para avaliar as melhores escalas de ativação (usando um momento).
Os módulos a seguir podem ser quantizados:
As ativações são sempre quantizadas por tensor, porque a maioria das operações de álgebra linear em um gráfico modelo não é compatível com entradas por eixo: você simplesmente não pode adicionar números que não são expressos na mesma base ( you cannot add apples and oranges ).
Os pesos envolvidos nas multiplicações da matriz são, pelo contrário, sempre quantizados ao longo de seu primeiro eixo, porque todos os recursos de saída são avaliados independentemente um do outro.
As saídas de uma multiplicação de matriz quantizada serão sempre desquantalizadas, mesmo que as ativações sejam quantizadas, porque:
int32 ou float32 ) do que a largura de bits de ativação (normalmente int8 ou float8 ),float . A quantização de ativações por tensor para int8 pode levar a erros de quantização graves se os tensores correspondentes contiver grandes valores externos. Normalmente, isso leva a tensores quantizados com a maioria dos valores definidos como zero (exceto os outliers).
Uma possível solução para contornar esse problema é "suavizar" as ativações estaticamente, conforme ilustrado por Smoothquant. Você pode encontrar um script para suavizar algumas arquiteturas de modelo em externo/smoothquant.
Uma opção melhor é representar ativações usando float8 .


