LangChain SynData RAG Eval
1.0.0
該存儲庫展示了Langchain,Llama2-Chat和零和少數及時的及時工程,以實現信息檢索(IR)和檢索增強生成(RAG)評估的合成數據生成。
簡介•亮點•示例筆記本•背景•指標•好處•提示模板•問題•todos
大型語言模型(LLM)通過理解複雜的查詢來改變信息檢索(IR)和搜索。該存儲庫展示了可用於生成IR和檢索增強生成(RAG)評估的複雜合成數據集的概念和軟件包。
生成的合成數據是給定上下文的查詢和答案。合成生成的上下文Query-Asswer的一個示例如下:
Provided Context (usually split from documents / text sources):
Pure TalkUSA is an American mobile virtual network operator headquartered in Covington, Georgia, United States.
It is most notable for an industry-first offering of rollover data in their data add-on packages, which has since been discontinued.
Pure TalkUSA is a subsidiary of Telrite Corporation. Bring Your Own Phone!
Synthetically Generated Query:
What was the outstanding service offered by Pure TalkUSA?
Synthetically Generated Answer:
The outstanding service from Pure TalkUSA was its industry-first offering of rollover data.
構建IR或抹布系統時,上下文,查詢和答案的數據集對於評估系統性能至關重要。人類宣布的數據集提供了出色的基礎真理,但可以獲得昂貴且具有挑戰性。因此,使用LLMS生成的合成數據集是一種有吸引力的解決方案和補充。
通過採用LLM提示工程,可以生成各種綜合查詢和答案,以形成可靠的驗證數據集。該存儲庫展示了一個生成合成數據的過程,同時強調零和少量彈出,以創建高度可自定義的合成數據集。圖1概述了此存儲庫中所示的合成數據集生成過程。
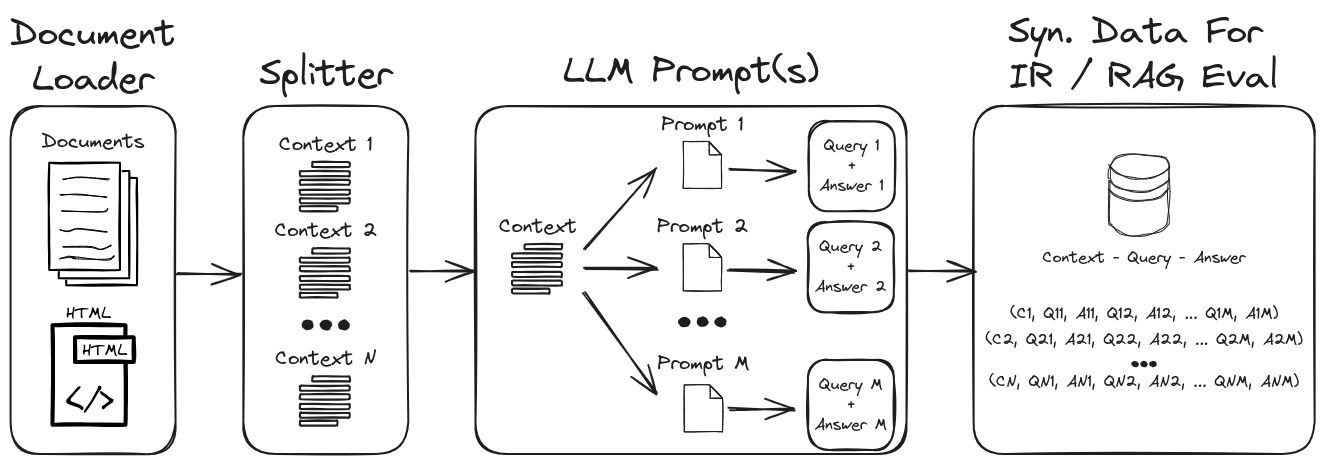
圖1:IR和抹布評估的合成數據生成
注意:請參閱背景和指標部分,以更深入地了解IR,抹布以及如何評估這些系統。
存儲庫中的一些關鍵亮點是:
1.)帶有自定義提示和輸出解析器的Langchain,用於結構化數據輸出:有關合成上下文 - 問題 - Query-Asswer數據生成的示例,請參見Gen-Question-Question-asswer-query.ipynb。該筆記本的關鍵方面是:
1.) Langchain自定義LLAMA2-CHAT提示:有關如何構建Langchain自定義提示模板的示例,請參見QA-Gen-Query-langchain.ipynb。本筆記本中顯示的一些蘭鏈功能是:
1.)零和少量彈藥提示工程:有關自定義數據集的合成上下文查詢數據生成的示例,請參見QA-gen-Query.ipynb。這裡介紹的關鍵功能是:
zero- and few-shot annotations LLMS。2.)上下文保護:有關參數檢索任務的綜合上下文查詢數據的示例,請參見參數 - Query.ipynb。在信息檢索的背景下,這些任務旨在從文檔等各種來源中檢索相關參數。在參數檢索中,目標是為用戶提供有說服力和可信的信息,以支持他們的論點或做出明智的決定。
可以很容易地在網上找到查詢特定生成模型的其他示例(例如, BeIR/query-gen-msmarco-t5-base-v1 )(請參閱Beir問題生成)。
IR系統的主要功能是檢索,該功能旨在確定用戶查詢與要檢索的內容之間的相關性。實施IR或破布系統需要特定於用戶的文檔。但是,缺乏自定義數據集的註釋數據集籃板系統評估。圖2概述了提問系統的典型抹布過程。
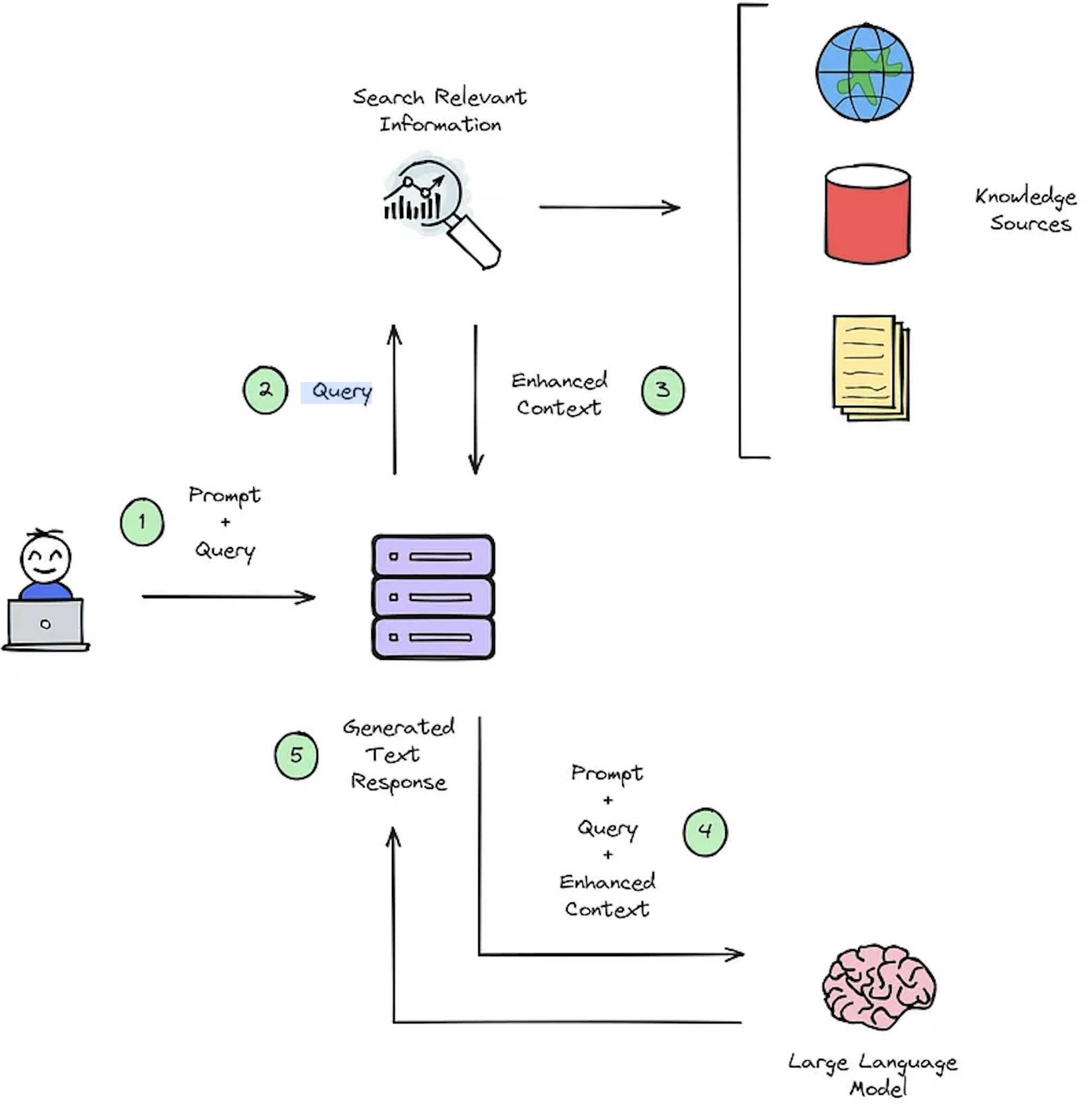
圖2:抹布過程概述[源]。
此合成上下文廣播數據集對於評估至關重要:1)IR的系統能夠選擇增強的上下文的能力,如圖2-步驟#3和2)所示,如圖2-步驟#5所示,抹布的生成響應。通過允許離線評估,它可以對系統之間的速度和準確性之間的平衡進行詳盡的分析,告知必要的修訂並選擇冠軍系統設計。
如圖3所述,IR和抹布系統的設計變得越來越複雜。
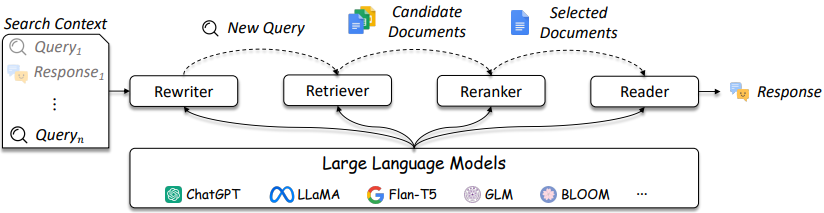
圖3:LLM可以在查詢重寫器,獵犬,Reranker和Reader [source]中使用
如圖所示,它們是IR /抹佈設計中的幾個考慮因素,解決方案的複雜性範圍從傳統方法(例如,基於項的稀疏方法)到基於神經的方法(例如,嵌入式和LLM)。對這些系統的評估對於做出完善的設計決策至關重要。從搜索到建議,評估措施對於了解在檢索中有效和不起作用至關重要。
提問(QA)系統(例如,抹布系統)有兩個組成部分:
在評估質量檢查系統時,兩個組件都需要分別評估並共同評估以獲得整體系統得分。
每當向抹布應用程序提出問題時,都可以考慮以下對象[來源]:
指標的選擇不是該存儲庫的主要重點,因為指標取決於應用程序。但是,為方便起見提供參考文章和信息。
圖4顯示了IR的常見評估指標,圖1中的Dataset可用於圖4所示的Offline Metrics 。
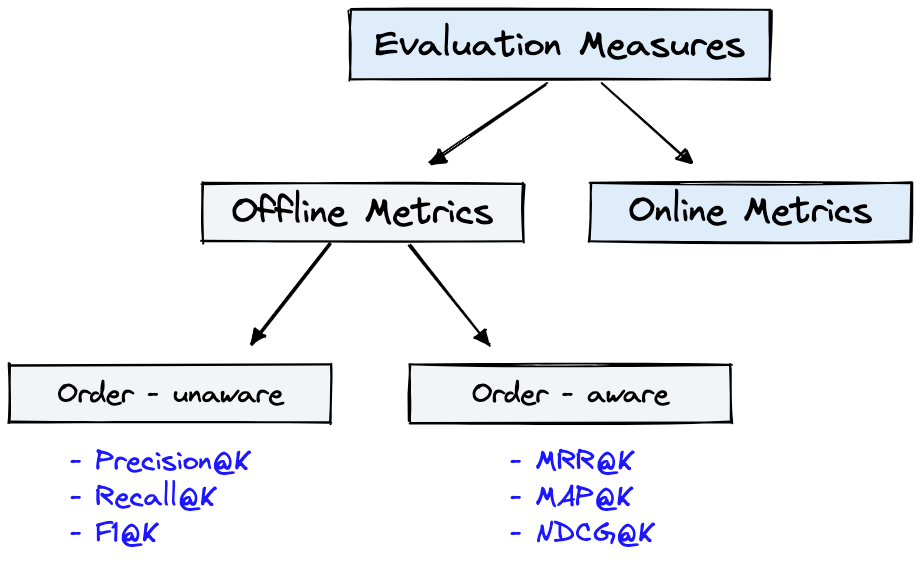
圖4:排名評估指標[來源]
Offline metrics在部署新的IR系統之前在孤立的環境中進行測量。這些查看使用系統檢索項目時是否返回一組特定的相關結果[源]。
對發電機指標的簡要回顧將展示一些度量複雜性。評估發電機時,查看所選答案段落是否與正確的答案或答案相匹配。
下面提供的是最少列出的生成器指標。
請參閱文章《深刻:評估問題回答系統的指標》,並使用ragas + langsmith評估詳細介紹這些指標的抹布管道。
LLM及時工程的合成數據生成的一些關鍵好處是:
Customized IR Task Query Generation :提示LLMS在可以生成的查詢類型的類型中提供了極大的靈活性。這很有幫助,因為IR任務在其應用中有所不同。例如,基準測試-IR(BEIR)是一個異質基準,其中包含不同的IR任務,例如提問,論證或反論點檢索,事實檢查等。由於IR任務中的多樣性,這是LLM提示的好處,因為可以在其中啟用LLM提示的好處,因為該提示可以為您量身定制,以生成IR IR任務的合成數據。圖5顯示了Beir中不同IR任務和數據集的概述。請參閱Beir排行榜以查看基於NLP的檢索模型的性能。 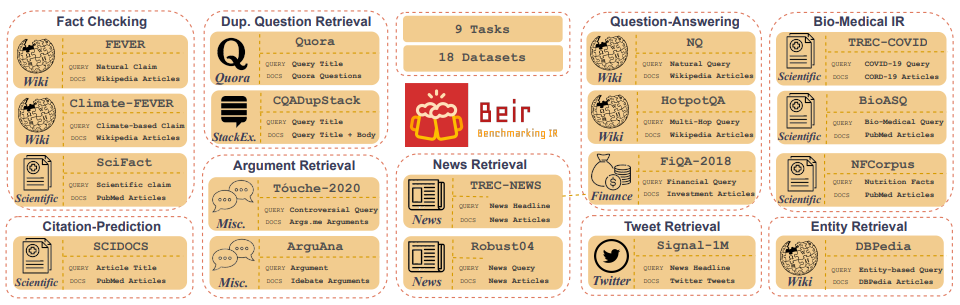
圖5:從[源]獲取的貝爾基準數據集和IR任務圖像
Zero or Few-Shot Annotations :在稱為零或幾次提示的技術中,開發人員可以向LLMS提供特定於域的示例查詢,從而大大增強查詢生成。這種方法通常只需要少數帶註釋的樣品。Longer Context Length :基於GPT的LLM模型(如Llama2)提供了擴展的上下文長度,與Bert的512代幣相比,高達4,096個令牌。這種較長的上下文增強了文檔解析和查詢生成控制。Llama2將在此存儲庫中用於生成合成查詢,因為它可以在消費級GPU上本地運行。下面顯示的是Llama2聊天的及時模板,該模板是對話和指導應用程序的微調。
<s>[INST] <<SYS>>
{your_system_message}
<</SYS>>
{user_message_1} [/INST]
<<SYS>>是開放訪問模型的無名優勢之一,是您對聊天應用程序中的系統提示完全控制。這對於指定聊天助手的行為至關重要 - 甚至使它具有某些個性 - 但它在APIS後面使用的模型中是無法實現的[來源]。請注意,基本Llama2模型沒有及時的結構,因為它們是原始的非教學調諧模型[源]。
其他資源和參考,以幫助提示技術和基礎知識:
Prompt Engineering和Consistency Filtering的更多詳細信息。該存儲庫將竭盡所能維護。如果您面臨任何問題或想進行改進,請提出問題或提交拉動請求。 ?


