LangChain SynData RAG Eval
1.0.0
Repositori ini menunjukkan rekayasa cepat langchain, llama2-chat, dan nol dan beberapa tembakan untuk memungkinkan pembuatan data sintetis untuk pengambilan informasi (IR) dan evaluasi pengambilan augmented generasi (RAG).
PENDAHULUAN • Sorotan • Contoh Buku Contoh • Latar Belakang • Metrik • Manfaat • Template Prompt • Masalah • Todos
Model Bahasa Besar (LLM) telah mengubah pengambilan informasi (IR) dan pencarian dengan memahami pertanyaan yang kompleks. Repositori ini menampilkan konsep dan paket yang dapat digunakan untuk menghasilkan kumpulan data sintetis yang canggih untuk evaluasi IR dan pengambilan augmented generasi (RAG).
Data sintetis yang dihasilkan adalah kueri dan jawaban untuk konteks yang diberikan. Contoh dari konteks-jawaban yang dihasilkan secara sintetis ditunjukkan di bawah ini:
Provided Context (usually split from documents / text sources):
Pure TalkUSA is an American mobile virtual network operator headquartered in Covington, Georgia, United States.
It is most notable for an industry-first offering of rollover data in their data add-on packages, which has since been discontinued.
Pure TalkUSA is a subsidiary of Telrite Corporation. Bring Your Own Phone!
Synthetically Generated Query:
What was the outstanding service offered by Pure TalkUSA?
Synthetically Generated Answer:
The outstanding service from Pure TalkUSA was its industry-first offering of rollover data.
Saat membangun sistem IR atau RAG, dataset konteks, permintaan, dan jawaban sangat penting untuk mengevaluasi kinerja sistem. Kumpulan data yang dianotasi manusia menawarkan kebenaran tanah yang sangat baik tetapi bisa mahal dan menantang untuk diperoleh; Oleh karena itu, kumpulan data sintetis yang dihasilkan menggunakan LLMS adalah solusi dan suplemen yang menarik.
Dengan menggunakan LLM Prompt Engineering, beragam pertanyaan dan jawaban sintetis dapat dihasilkan untuk membentuk dataset validasi yang kuat. Repositori ini menampilkan suatu proses untuk menghasilkan data sintetis sambil menekankan nol dan beberapa pengambilan gambar untuk membuat dataset sintetis yang sangat dapat disesuaikan. Gambar 1 menguraikan proses pembuatan dataset sintetis yang ditunjukkan dalam repositori ini.
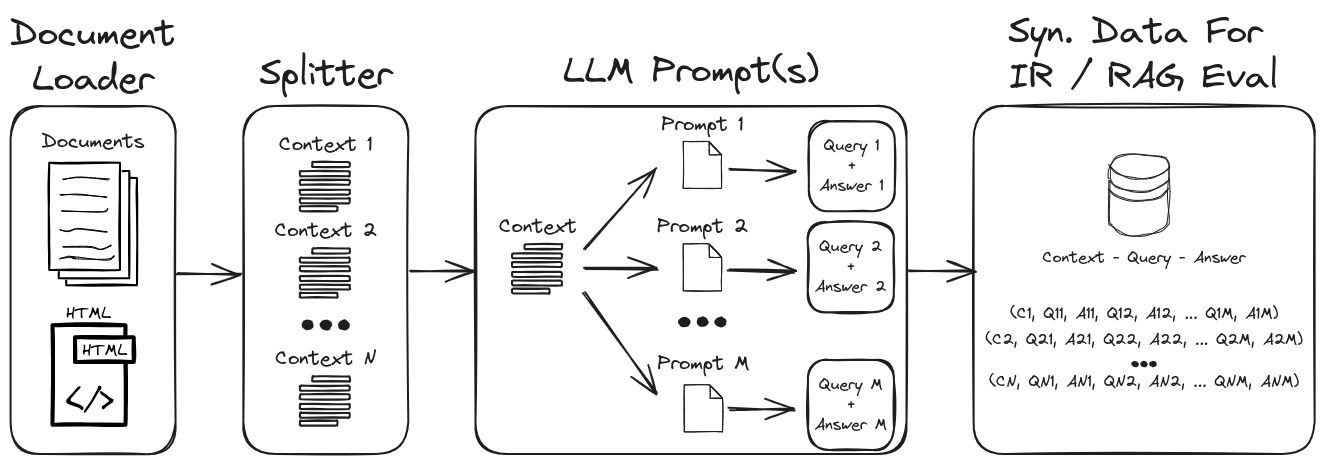
Gambar 1: Pembuatan data sintetis untuk evaluasi IR dan RAG
Catatan : Lihat bagian latar belakang dan metrik untuk menyelam lebih dalam pada IR, RAG, dan bagaimana mengevaluasi sistem ini.
Beberapa sorotan utama dalam repositori adalah:
1.) Langchain dengan prompt khusus dan parser output untuk output data terstruktur : lihat gen-pertanyaan-answer-query.ipynb untuk contoh pembuatan data konteks-query-weery sintetis. Aspek kunci dari buku catatan ini adalah:
1.) Langchain Custom llama2-CHAT CHAT : Lihat QA-Gen-Query-Langchain.ipynb untuk contoh cara membangun templat prompt kustom Langchain untuk pembuatan konteks-kuery. Beberapa fitur Langchain yang ditampilkan dalam buku catatan ini adalah:
1.) Teknik cepat nol dan beberapa tembakan : Lihat QA-GEN-QUERY.IPYNB untuk contoh pembuatan data konteks-konteks sintetis untuk kumpulan data khusus. Fitur utama yang disajikan di sini adalah:
zero- and few-shot annotations pada dataset tanya jawab Squadv2.2.) Konteks-Tamu : Lihat Argumen-Gen-Query.ipynb untuk contoh data kuer-konteks sintetis untuk tugas pengambilan argumen. Dalam konteks pengambilan informasi, tugas -tugas ini dirancang untuk mengambil argumen yang relevan dari berbagai sumber seperti dokumen. Dalam pengambilan argumen, tujuannya adalah untuk memberikan pengguna informasi yang persuasif dan kredibel untuk mendukung argumen mereka atau membuat keputusan yang tepat.
Contoh lain dari model generasi spesifik kueri (misalnya, BeIR/query-gen-msmarco-t5-base-v1 ) dapat dengan mudah ditemukan secara online (lihat BEIR.
Fungsi utama dari sistem IR adalah pengambilan, yang bertujuan untuk menentukan relevansi antara permintaan pengguna dan konten yang akan diambil. Menerapkan IR atau sistem RAG menuntut dokumen khusus pengguna. Namun, kekurangan kumpulan data yang beranotasi untuk evaluasi sistem HAMPERS HAMPERS khusus. Gambar 2 memberikan gambaran umum tentang proses RAG yang khas untuk sistem pertanyaan pertanyaan.
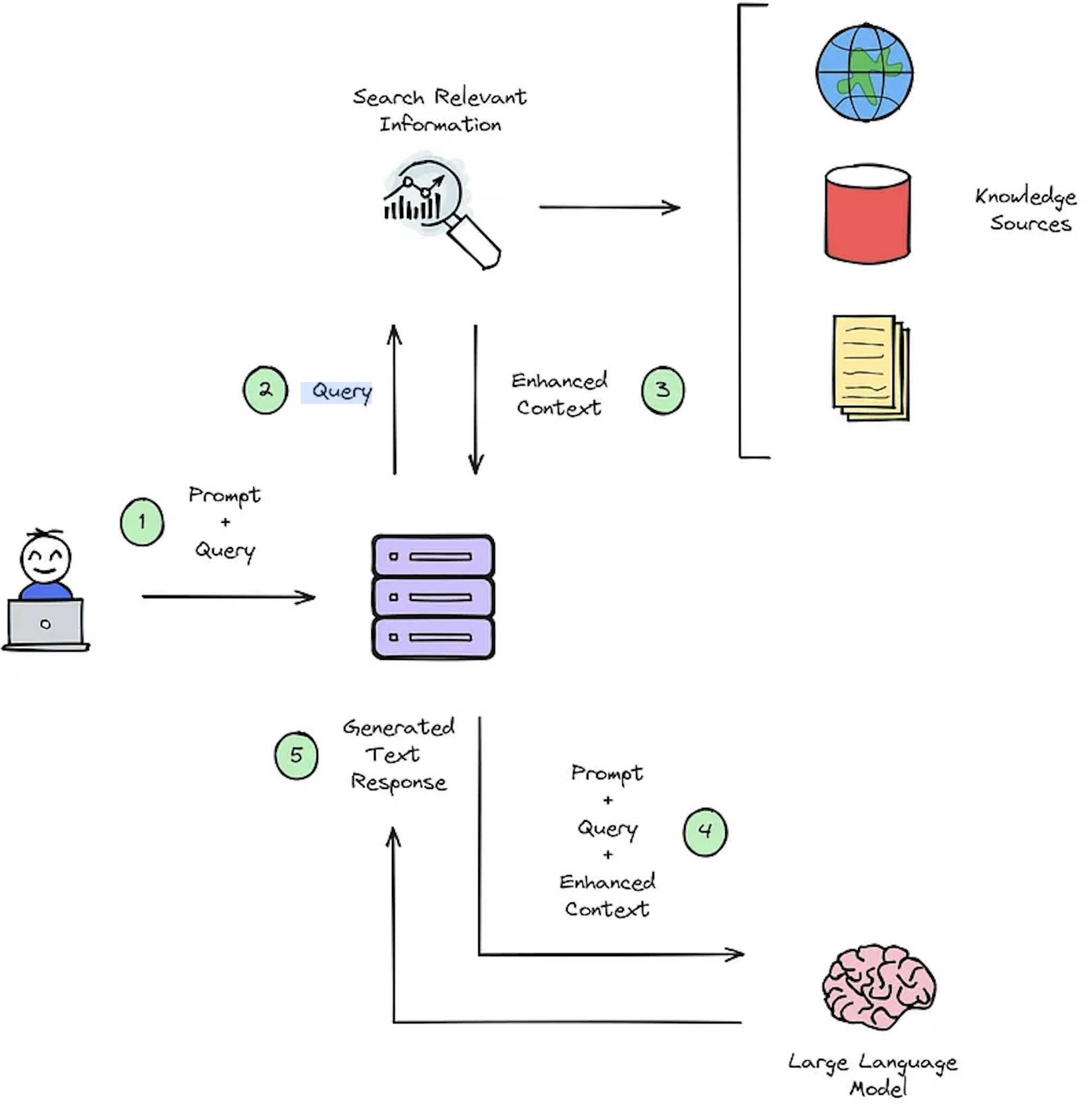
Gambar 2: Ikhtisar Proses RAG [Sumber].
Dataset konteks sintetis -query -jawab ini sangat penting untuk mengevaluasi: 1) Kemampuan sistem IR untuk memilih konteks yang ditingkatkan seperti yang diilustrasikan pada Gambar 2 - Langkah #3, dan 2) respons yang dihasilkan RAG seperti yang ditunjukkan pada Gambar 2 - Langkah #5. Dengan memungkinkan evaluasi offline, ini memungkinkan analisis menyeluruh tentang keseimbangan sistem antara kecepatan dan akurasi, menginformasikan revisi yang diperlukan dan memilih desain sistem Champion.
Desain IR dan sistem RAG menjadi lebih rumit seperti yang dirujuk pada Gambar 3.
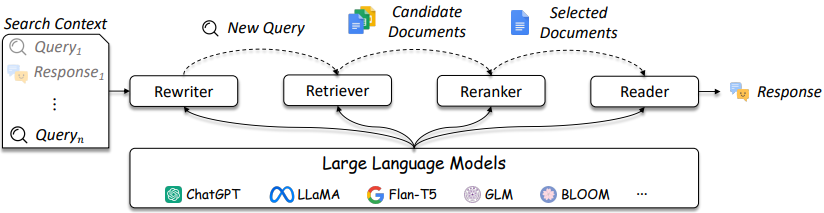
Gambar 3: LLMS dapat digunakan dalam Query Rewriter, Retriever, Reranker, dan Reader [Sumber]
Seperti yang ditunjukkan, mereka adalah beberapa pertimbangan dalam desain dan solusi IR / RAG dapat berkisar dalam kompleksitas dari metode tradisional (misalnya, metode jarang berbasis istilah) hingga metode berbasis saraf (misalnya, embeddings dan LLM). Evaluasi sistem ini sangat penting untuk membuat keputusan desain yang terinformasi dengan baik. Dari pencarian hingga rekomendasi, langkah -langkah evaluasi sangat penting untuk memahami apa yang dilakukan dan tidak berfungsi dalam pengambilan.
Sistem pertanyaan-antermer (misalnya, sistem RAG) memiliki dua komponen:
Saat mengevaluasi sistem QA, kedua komponen perlu dievaluasi secara terpisah dan bersama -sama untuk mendapatkan skor sistem secara keseluruhan.
Setiap kali sebuah pertanyaan diajukan ke aplikasi RAG, objek berikut dapat dipertimbangkan [Sumber]:
Pemilihan metrik bukanlah fokus utama dari repositori ini karena metrik bergantung pada aplikasi; Namun artikel dan informasi referensi disediakan untuk kenyamanan.
Gambar 4 menunjukkan metrik evaluasi umum untuk IR dan Dataset dari Gambar 1 dapat digunakan untuk Offline Metrics yang ditunjukkan pada Gambar 4.
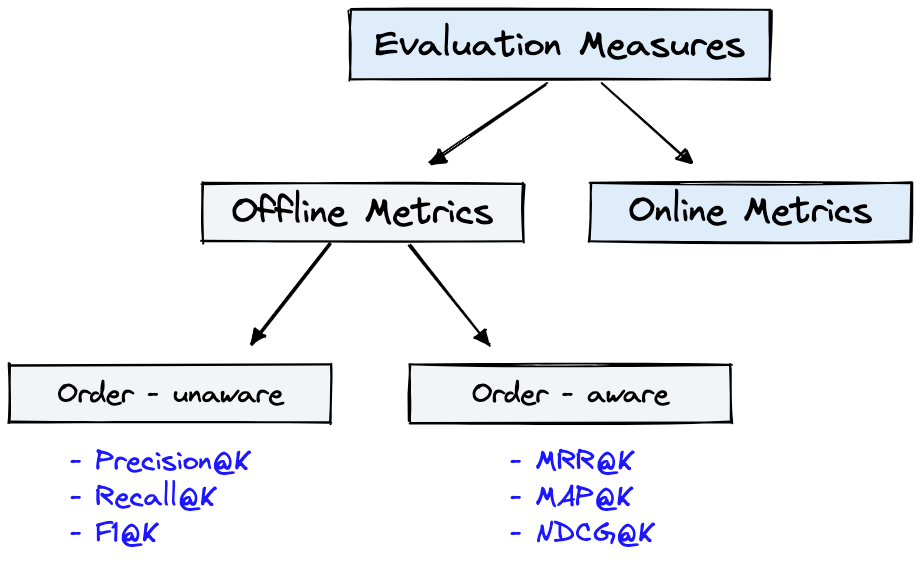
Gambar 4: Metrik Evaluasi Peringkat [Sumber]
Offline metrics diukur dalam lingkungan yang terisolasi sebelum menggunakan sistem IR baru. Ini melihat apakah satu set hasil yang relevan dikembalikan saat mengambil item dengan sistem [sumber].
Tinjauan singkat tentang metrik generator akan memamerkan beberapa tingkatan kompleksitas metrik. Saat mengevaluasi generator, lihat apakah, atau sejauh mana, bagian jawaban yang dipilih cocok dengan jawaban atau jawaban yang benar.
Disediakan di bawah ini adalah metrik generator yang tercantum dalam urutan paling tidak ke paling kompleks.
Silakan merujuk ke artikel Deepset: Metrik untuk mengevaluasi sistem penjawab pertanyaan dan mengevaluasi pipa kain dengan ragas + langssmith yang menguraikan metrik ini.
Beberapa manfaat utama dari pembuatan data sintetis dengan rekayasa cepat LLM adalah:
Customized IR Task Query Generation : Meminta LLMs menawarkan fleksibilitas besar dalam jenis kueri yang dapat dihasilkan. Ini bermanfaat karena tugas IR bervariasi dalam aplikasi mereka. Misalnya, Benchmarking-IR (BEIR) adalah tolok ukur heterogen yang berisi beragam tugas IR seperti jawaban pertanyaan, argumen atau pengambilan argumen kontra, pemeriksaan fakta, dll. Karena keragaman dalam tugas-tugas IR ini adalah di mana manfaat dari LLM dapat keunggulan karena dorongan dapat disesuaikan untuk menghasilkan data synthetical. Gambar 5 menunjukkan tinjauan umum tentang beragam tugas dan dataset IR di Beir. Lihat papan peringkat BEIR untuk melihat kinerja model pengambilan berbasis NLP. 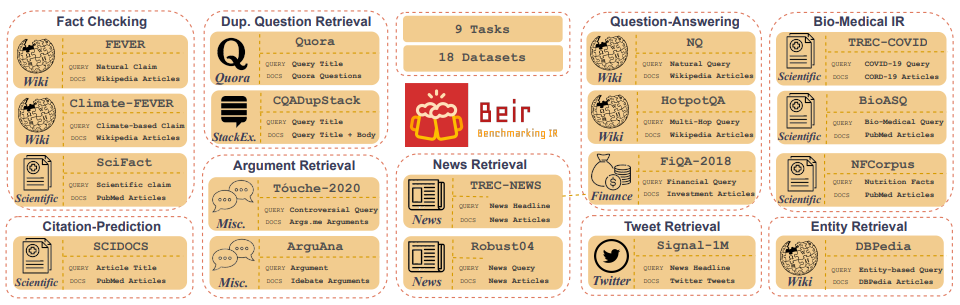
Gambar 5: Dataset Benchmark Beir dan Tugas IR Gambar diambil dari [Sumber]
Zero or Few-Shot Annotations : Dalam teknik yang disebut sebagai nol atau beberapa-shot dorongan, pengembang dapat memberikan kueri contoh khusus domain untuk LLMS, sangat meningkatkan generasi kueri. Pendekatan ini sering hanya membutuhkan beberapa sampel beranotasi.Longer Context Length : Model LLM berbasis GPT, seperti LLAMA2, memberikan panjang konteks yang diperluas, hingga 4.096 token dibandingkan dengan 512 token Bert. Konteks yang lebih lama ini meningkatkan penguraian dokumen dan kontrol generasi kueri.LLAMA2 akan digunakan dalam repositori ini untuk menghasilkan kueri sintetis karena dapat dijalankan secara lokal di GPU kelas konsumen. Di bawah ini adalah templat cepat untuk obrolan llama2 yang disesuaikan untuk dialog dan aplikasi instruksi.
<s>[INST] <<SYS>>
{your_system_message}
<</SYS>>
{user_message_1} [/INST]
<<SYS>> adalah salah satu keuntungan tanpa tanda jasa dari model akses terbuka adalah Anda memiliki kontrol penuh atas prompt sistem dalam aplikasi obrolan. Ini penting untuk menentukan perilaku asisten obrolan Anda - dan bahkan mengilhami beberapa kepribadian -, tetapi tidak dapat dijangkau dalam model yang dilayani di belakang API [sumber].Perhatikan bahwa model LLAMA2 BASE tidak memiliki struktur yang cepat karena mereka adalah model yang disetel non-instruksi mentah [Sumber].
Sumber daya dan referensi tambahan untuk membantu teknik dan dasar -dasarnya:
Prompt Engineering dan Consistency Filtering .Repositori ini akan melakukan yang terbaik untuk dipertahankan. Jika Anda menghadapi masalah apa pun atau ingin melakukan perbaikan, silakan angkat masalah atau kirimkan permintaan tarik. ?


