LangChain SynData RAG Eval
1.0.0
Этот репозиторий демонстрирует инженерию Langchain, Llama2-Chat и Zero- и несколько выстрелов, чтобы обеспечить оценку синтетических данных для получения информации о поиске информации (IR) и получении для поиска (RAG).
Введение • Основные моменты • Пример записных книг • Фон • Метрики • Преимущества • Шаблоны быстрого
Большие языковые модели (LLMS) преобразовали поиск информации (IR) и поиск путем понимания сложных запросов. Этот репозиторий демонстрирует концепции и пакеты, которые можно использовать для генерации сложных синтетических наборов данных для оценки ИК и получения добычи (RAG).
Сгенерированные синтетические данные являются запросом и ответом для данного контекста. Пример синтетически сгенерированного контекста-Query-answer показан ниже:
Provided Context (usually split from documents / text sources):
Pure TalkUSA is an American mobile virtual network operator headquartered in Covington, Georgia, United States.
It is most notable for an industry-first offering of rollover data in their data add-on packages, which has since been discontinued.
Pure TalkUSA is a subsidiary of Telrite Corporation. Bring Your Own Phone!
Synthetically Generated Query:
What was the outstanding service offered by Pure TalkUSA?
Synthetically Generated Answer:
The outstanding service from Pure TalkUSA was its industry-first offering of rollover data.
При создании системы ИК или RAG, набор данных контекста, запросов и ответов жизненно важен для оценки производительности системы. Наборы данных, аннотируемые человеком, предлагают отличные основные истины, но могут быть дорогими и сложными для получения; Следовательно, синтетические наборы данных, генерируемые с использованием LLMS, являются привлекательным решением и дополнением.
Используя инженерную инженерию LLM, можно создать разнообразный диапазон синтетических запросов и ответов, чтобы сформировать надежный набор данных проверки. Этот репозиторий демонстрирует процесс генерации синтетических данных, при этом акцентируя при этом побуждение с нулевыми и небольшими выстрелами для создания высоко настраиваемых синтетических наборов данных. На рисунке 1 изложены процесс генерации синтетических наборов данных, продемонстрированный в этом репозитории.
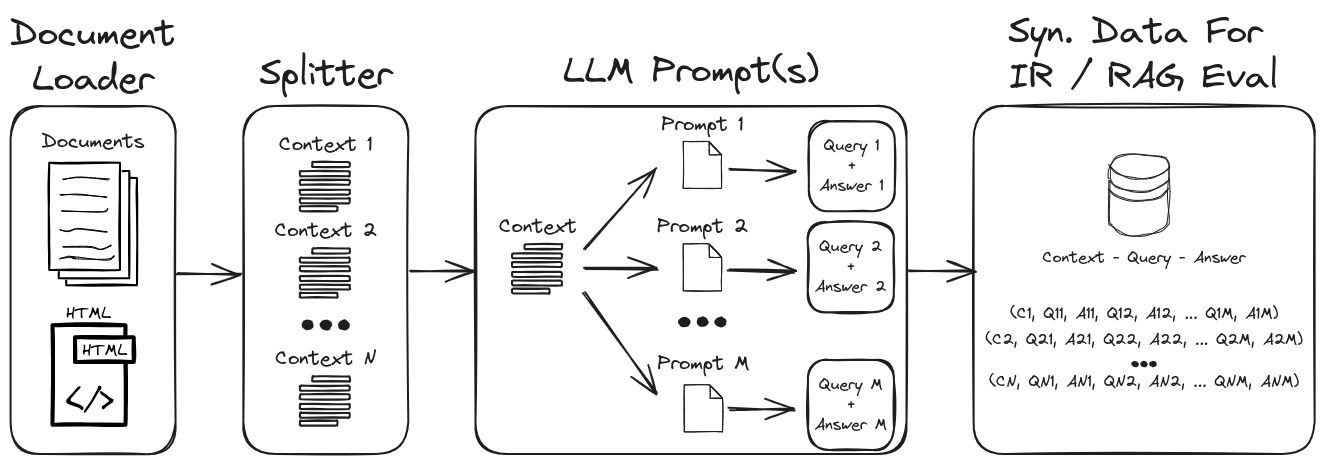
Рисунок 1: Синтетические данные для оценки ИК и RAG
ПРИМЕЧАНИЕ . Обратитесь к разделам фон и метрик для более глубокого погружения на IR, RAG и как оценить эти системы.
Несколько ключевых основных моментов в репозитории:
1.) Langchain с пользовательскими подсказками и анализаторами вывода для структурированных данных : см. Gen-Question-Asswer-Query.ipynb для примера генерации данных синтетического контекста-кверика-ответа. Ключевые аспекты этого ноутбука:
1.) Langchain Custom Llama2-чат подсказка : см. QA-Gen-Query-Langchain.ipynb для примера того, как построить шаблоны на заказ Langchain Custom для поколения контекстных Query. Несколько функций Langchain, показанные в этой записной книжке:
1.) Инженерная инженерия с нулевым и несколькими выстрелами : см. QE-Gen-Query.ipynb для примера генерации синтетических контекстных данных для пользовательских наборов данных. Ключевые функции представлены здесь:
zero- and few-shot annotations в наборе данных QUADV2.2.) Контекст-обработка : см. В контексте поиска информации эти задачи предназначены для извлечения соответствующих аргументов из различных источников, таких как документы. При поиске аргументов цель состоит в том, чтобы предоставить пользователям убедительную и заслуживающую доверия информацию для поддержки их аргументов или принятия обоснованных решений.
Другие примеры моделей генерации, специфичных для запросов (например, BeIR/query-gen-msmarco-t5-base-v1 ) можно легко найти в Интернете (см. Генерацию вопросов BEIR).
Основной функцией IR -системы является поиск, целью которого является определение актуальности между запросом пользователей и контентом, который будет получен. Внедрение системы ИК или RAG требует конкретных документов. Тем не менее, отсутствие аннотированных наборов данных для пользовательских наборов данных застегивает оценку системы. На рисунке 2 представлен обзор типичного процесса тряпки для системы ответа вопросам.
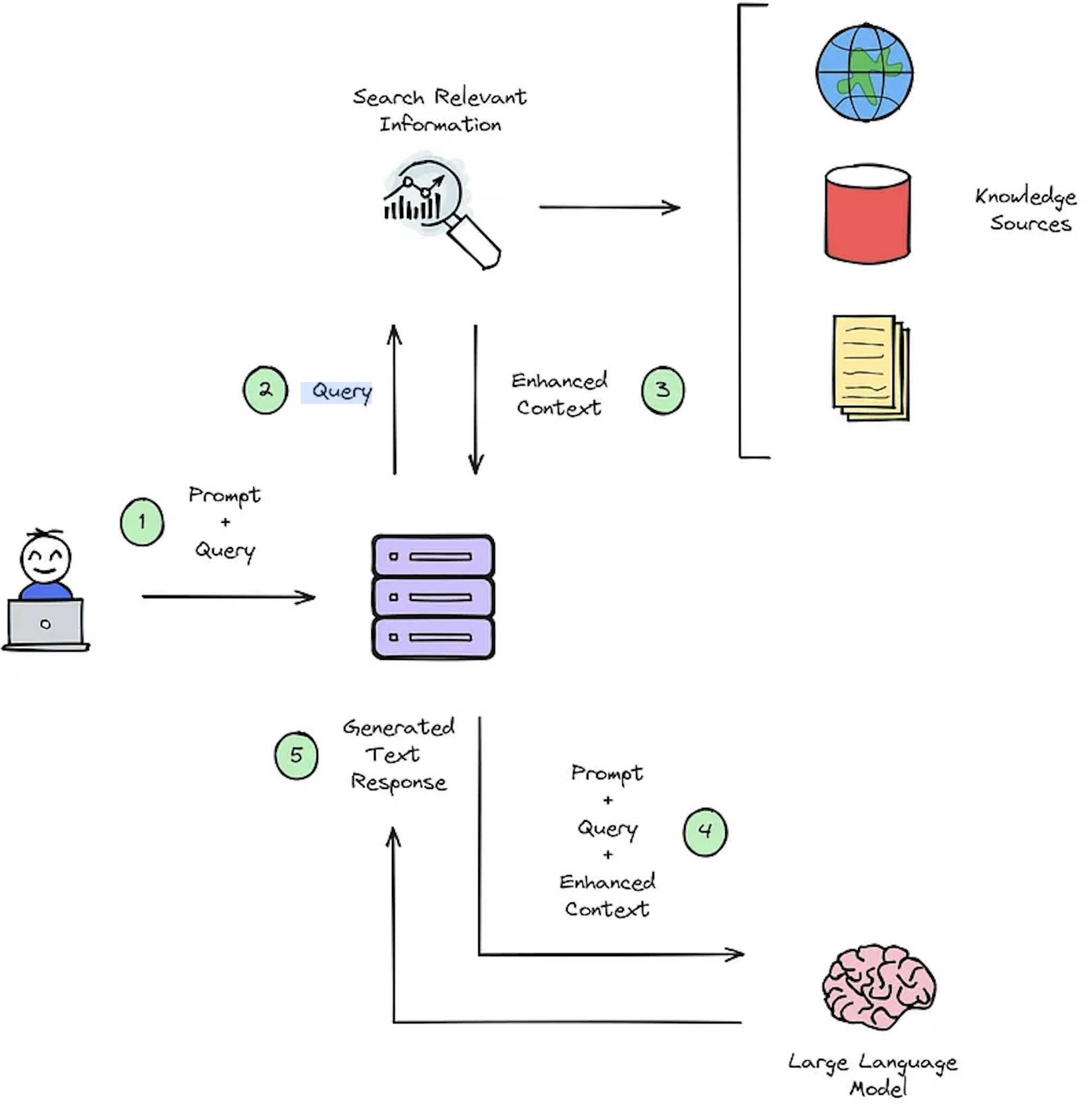
Рисунок 2: Обзор процесса RAG [источник].
Эти наборы данных о синтетическом контекстно -контекстном ответе имеют решающее значение для оценки: 1) способность систем IR выбирать усиленный контекст, как показано на рисунке 2 - Шаг № 3, и 2) сгенерированный ответ RAG, как показано на рисунке 2 - Шаг № 5. Разреская офлайн -оценку, это обеспечивает тщательный анализ баланса системы между скоростью и точностью, информируя необходимые изменения и выбирая проекты системы чемпиона.
Дизайн IR и RAG Systems становится все более сложным, как указано на рисунке 3.
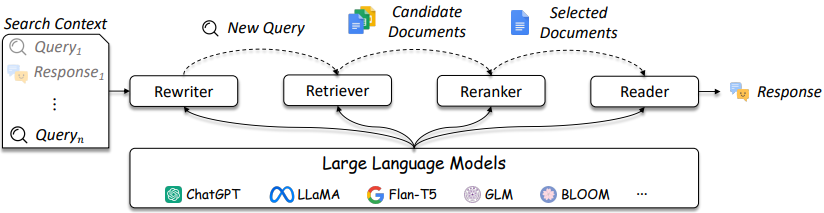
Рисунок 3: LLMS можно использовать в перезаписи запроса, ретривера, реранкера и читателя [источник]
Как показано, их являются несколько соображений в дизайне ИК / RAG, а решения могут варьироваться в сложности от традиционных методов (например, разрешенные методы на основе терминов) до нейронных методов (например, Encemddings и LLMS). Оценка этих систем имеет решающее значение для принятия хорошо информированных проектных решений. От поиска до рекомендаций меры оценки имеют первостепенное значение для понимания того, что делает и не работает при поиске.
Системы с ответом на вопрос (QA) (например, Rag System) имеют два компонента:
При оценке системы QA оба компонента должны быть оценены отдельно и вместе, чтобы получить общий балл системы.
Всякий раз, когда задается вопрос в приложении Rag, можно рассмотреть следующие объекты [Source]:
Выбор метрик не является основным направлением этого репозитория, поскольку метрики зависят от приложения; Однако справочные статьи и информация предоставляются для удобства.
На рисунке 4 показаны общие показатели оценки для ИК, и Dataset на рисунке 1 можно использовать для Offline Metrics показанных на рисунке 4.
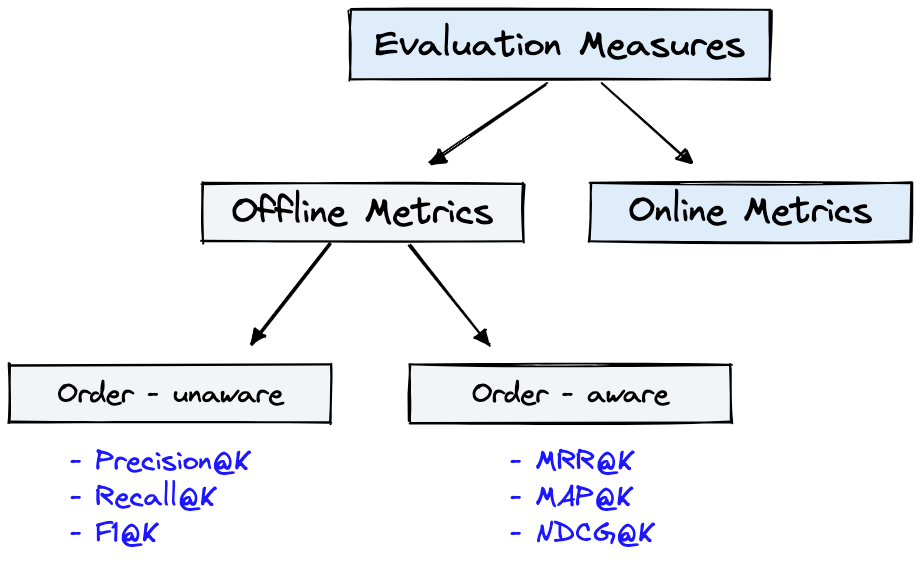
Рисунок 4: Метрики оценки ранжирования [источник]
Offline metrics измеряются в изолированной среде перед развертыванием новой ИК -системы. Они смотрят на то, возвращается ли определенный набор соответствующих результатов при получении элементов с системой [источником].
Краткий обзор метрик генератора продемонстрирует несколько уровней метрической сложности. При оценке генератора посмотрите, соответствуют ли выбранные отрывки ответов, выбранные отрывки ответа или ответы.
Ниже приведены показатели генератора, перечисленные в порядке наименьшего до наиболее сложного.
Пожалуйста, обратитесь к статье Deepset: метрики, чтобы оценить систему ответов на вопросы и оценки Rag Tipines с Ragas + Langsmith, которые подробно рассмотрены этими показателями.
Несколько ключевых преимуществ генерации синтетических данных с помощью LLM -инженерии:
Customized IR Task Query Generation : побуждение LLM предлагает большую гибкость в типах запросов, которые могут быть сгенерированы. Это полезно, потому что ИК -задачи различаются в их применении. Например, Benchmarking-IR (BEIR) представляет собой гетерогенный эталон, содержащий разнообразные ИК-задачи, такие как вопрос о ответе на вопросы, аргумент или контр-аргумент, проверка фактов и т. Д. Из-за разнообразия в ИК-задачах. Это то, где преимущества подсказки LLM могут превосходить, потому что подсказка может быть адаптирована для создания синтетических данных к задаче IR. На рисунке 5 показан обзор разнообразных ИК -задач и наборов данных в BEIR. Обратитесь к таблице лидеров BEIR, чтобы увидеть производительность моделей поиска NLP. 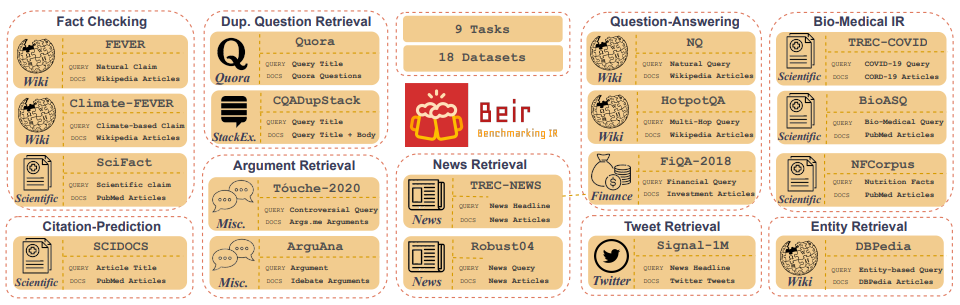
Рисунок 5: Наборы данных BEIR и ИК -задачи изображение, взятое из [Источник]
Zero or Few-Shot Annotations : в технике, называемом подсказкой нуля или нескольких выстрелов, разработчики могут предоставить примеры, специфичные для домена, для LLMS, значительно улучшая генерацию запросов. Этот подход часто требует лишь нескольких аннотированных образцов.Longer Context Length : модели LLM на основе GPT, такие как Llama2, обеспечивают расширенную длину контекста, до 4096 токенов по сравнению с 512 токенами Bert. Этот более длинный контекст усиливает контроль подбора документов и управление генерацией запросов.LLAMA2 будет использоваться в этом репозитории для создания синтетических запросов, потому что его можно использовать локально на графических процессорах потребительского уровня. Ниже показан шаблон быстрого чата Llama2, который был настраирован на приложения для диалога и инструкции.
<s>[INST] <<SYS>>
{your_system_message}
<</SYS>>
{user_message_1} [/INST]
<<SYS>> является одним из незамеченных преимуществ открытых моделей, заключается в том, что вы имеете полный контроль над подсказкой системы в приложениях чата. Это важно, чтобы указать поведение вашего ассистента в чате - и даже наполнить его некоторой личностью - но оно недоступно в моделях, обслуживаемых за API [источник].Обратите внимание, что базовые модели LLAMA2 не имеют быстрой структуры, потому что они являются необработанными моделями, не настроенными на инструкцию [Source].
Дополнительные ресурсы и ссылки на помощь с методами подсказки и оснований:
Prompt Engineering и Consistency Filtering .Этот репозиторий сделает все возможное, чтобы сохранить. Если вы столкнетесь с какой -либо проблемой или хотите сделать улучшения, поднимите проблему или отправьте запрос на привлечение. ?


