LangChain SynData RAG Eval
1.0.0
พื้นที่เก็บข้อมูลนี้แสดงให้เห็นถึง Langchain, Llama2-Chat และวิศวกรรมที่รวดเร็วและไม่กี่ตัวเพื่อเปิดใช้งานการสร้างข้อมูลสังเคราะห์สำหรับการดึงข้อมูล (IR) และการประเมินผลการเพิ่ม (RAG) การดึงข้อมูล (RAG)
บทนำ•ไฮไลท์•สมุดบันทึกตัวอย่าง•พื้นหลัง•ตัวชี้วัด•ประโยชน์•เทมเพลตที่รวดเร็ว•ปัญหา• Todos
โมเดลภาษาขนาดใหญ่ (LLMS) ได้เปลี่ยนการดึงข้อมูล (IR) และค้นหาโดยการทำความสะอาดแบบสอบถามที่ซับซ้อน พื้นที่เก็บข้อมูลนี้นำเสนอแนวคิดและแพ็คเกจที่สามารถใช้ในการสร้างชุดข้อมูลสังเคราะห์ที่ซับซ้อนสำหรับการประเมินผลการสร้าง Augmented Generation (RAG)
ข้อมูลสังเคราะห์ที่สร้างขึ้นเป็นแบบสอบถามและคำตอบสำหรับบริบทที่กำหนด ตัวอย่างของคำตอบบริบทที่สร้างขึ้นแบบสังเคราะห์แสดงไว้ด้านล่าง:
Provided Context (usually split from documents / text sources):
Pure TalkUSA is an American mobile virtual network operator headquartered in Covington, Georgia, United States.
It is most notable for an industry-first offering of rollover data in their data add-on packages, which has since been discontinued.
Pure TalkUSA is a subsidiary of Telrite Corporation. Bring Your Own Phone!
Synthetically Generated Query:
What was the outstanding service offered by Pure TalkUSA?
Synthetically Generated Answer:
The outstanding service from Pure TalkUSA was its industry-first offering of rollover data.
เมื่อสร้างระบบ IR หรือ RAG ชุดข้อมูลของบริบทการสืบค้นและคำตอบมีความสำคัญสำหรับการประเมินประสิทธิภาพของระบบ ชุดข้อมูลที่มีคำอธิบายประกอบของมนุษย์นำเสนอความจริงพื้นฐานที่ยอดเยี่ยม แต่อาจมีราคาแพงและท้าทายที่จะได้รับ ดังนั้นชุดข้อมูลสังเคราะห์ที่สร้างขึ้นโดยใช้ LLMs จึงเป็นโซลูชันและอาหารเสริมที่น่าสนใจ
ด้วยการใช้งานวิศวกรรมที่รวดเร็วของ LLM สามารถสร้างแบบสอบถามและคำตอบสังเคราะห์ที่หลากหลายเพื่อสร้างชุดข้อมูลการตรวจสอบที่แข็งแกร่ง พื้นที่เก็บข้อมูลนี้แสดงกระบวนการในการสร้างข้อมูลสังเคราะห์ในขณะที่เน้นการแจ้งเตือนแบบศูนย์และไม่กี่ครั้งสำหรับการสร้างชุดข้อมูลสังเคราะห์ที่ปรับแต่งได้สูง รูปที่ 1 สรุปกระบวนการสร้างชุดข้อมูลสังเคราะห์ที่แสดงในที่เก็บนี้
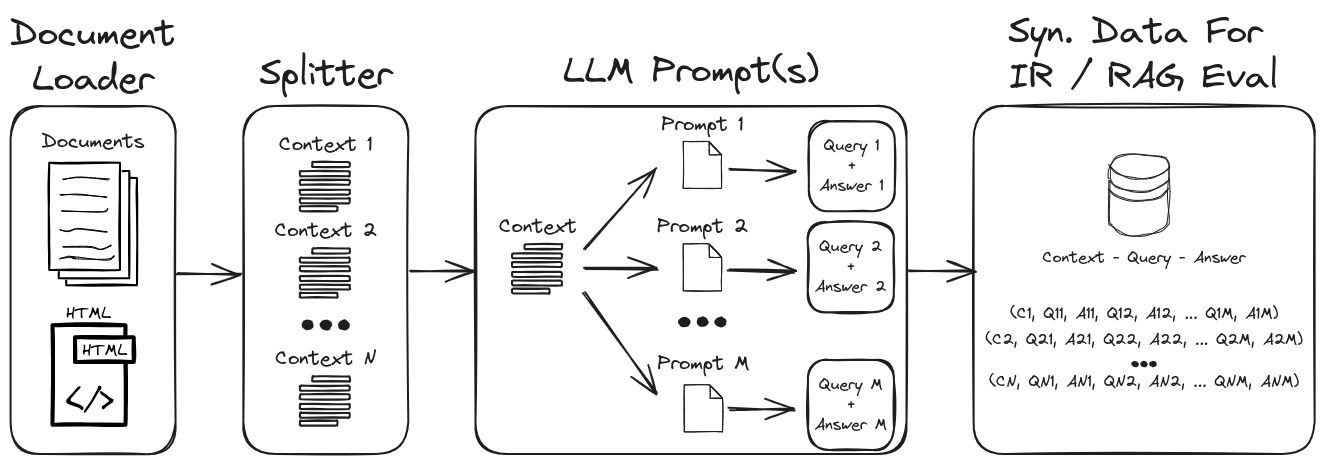
รูปที่ 1: การสร้างข้อมูลสังเคราะห์สำหรับการประเมิน IR และ RAG
หมายเหตุ : อ้างถึงส่วนพื้นหลังและส่วนตัวชี้วัดสำหรับการดำน้ำลึกลงไปใน IR, RAG และวิธีการประเมินระบบเหล่านี้
ไฮไลท์สำคัญบางประการในที่เก็บคือ:
1. ) Langchain ที่มีพรอมต์ที่กำหนดเองและตัวแยกวิเคราะห์เอาท์พุทสำหรับเอาต์พุตข้อมูลที่มีโครงสร้าง : ดู gen-question-answer-query.ipynb สำหรับตัวอย่างของการสร้างคำตอบบริบทบริบทสังเคราะห์ ประเด็นสำคัญของสมุดบันทึกนี้คือ:
1. ) การแจ้งเตือน Llama2-Chat ที่กำหนดเอง Langchain : ดู Qa-gen-gen-query-langchain.ipynb สำหรับตัวอย่างของวิธีการสร้างเทมเพลตพรอมต์แบบกำหนดเองของ Langchain สำหรับการสร้างบริบท ฟีเจอร์ Langchain บางส่วนที่แสดงในสมุดบันทึกนี้คือ:
1. ) วิศวกรรมพรอมต์แบบศูนย์และไม่กี่ : ดู QA-Gen-Query.IPYNB สำหรับตัวอย่างของการสร้างข้อมูลบริบท-การสร้างคำถามสำหรับชุดข้อมูลที่กำหนดเอง คุณสมบัติที่สำคัญที่นำเสนอที่นี่คือ:
zero- and few-shot annotations ในชุดข้อมูลการตอบคำถาม Squadd22. ) บริบท-arugment : ดูอาร์กิวเมนต์-gen-query.ipynb สำหรับตัวอย่างของข้อมูลคำถามบริบทสังเคราะห์สำหรับงานดึงอาร์กิวเมนต์ ในบริบทของการดึงข้อมูลงานเหล่านี้ได้รับการออกแบบมาเพื่อดึงข้อโต้แย้งที่เกี่ยวข้องจากแหล่งต่าง ๆ เช่นเอกสาร ในการเรียกร้องการโต้เถียงเป้าหมายคือการให้ข้อมูลที่โน้มน้าวใจและน่าเชื่อถือแก่ผู้ใช้เพื่อสนับสนุนข้อโต้แย้งของพวกเขาหรือตัดสินใจอย่างชาญฉลาด
ตัวอย่างอื่น ๆ ของแบบสอบถามแบบสอบถามเฉพาะรุ่น (เช่น BeIR/query-gen-msmarco-t5-base-v1 ) สามารถพบได้อย่างง่ายดายทางออนไลน์ (ดูการสร้างคำถาม Beir)
ฟังก์ชั่นหลักของระบบ IR คือการดึงข้อมูลซึ่งมีวัตถุประสงค์เพื่อกำหนดความเกี่ยวข้องระหว่างการสืบค้นของผู้ใช้และเนื้อหาที่จะเรียกคืน การใช้ระบบ IR หรือ RAG ต้องการเอกสารเฉพาะผู้ใช้ อย่างไรก็ตามการขาดชุดข้อมูลที่มีคำอธิบายประกอบสำหรับชุดข้อมูลที่กำหนดเองการประเมินระบบ Hampers รูปที่ 2 แสดงภาพรวมของกระบวนการ RAG ทั่วไปสำหรับระบบการตอบคำถาม
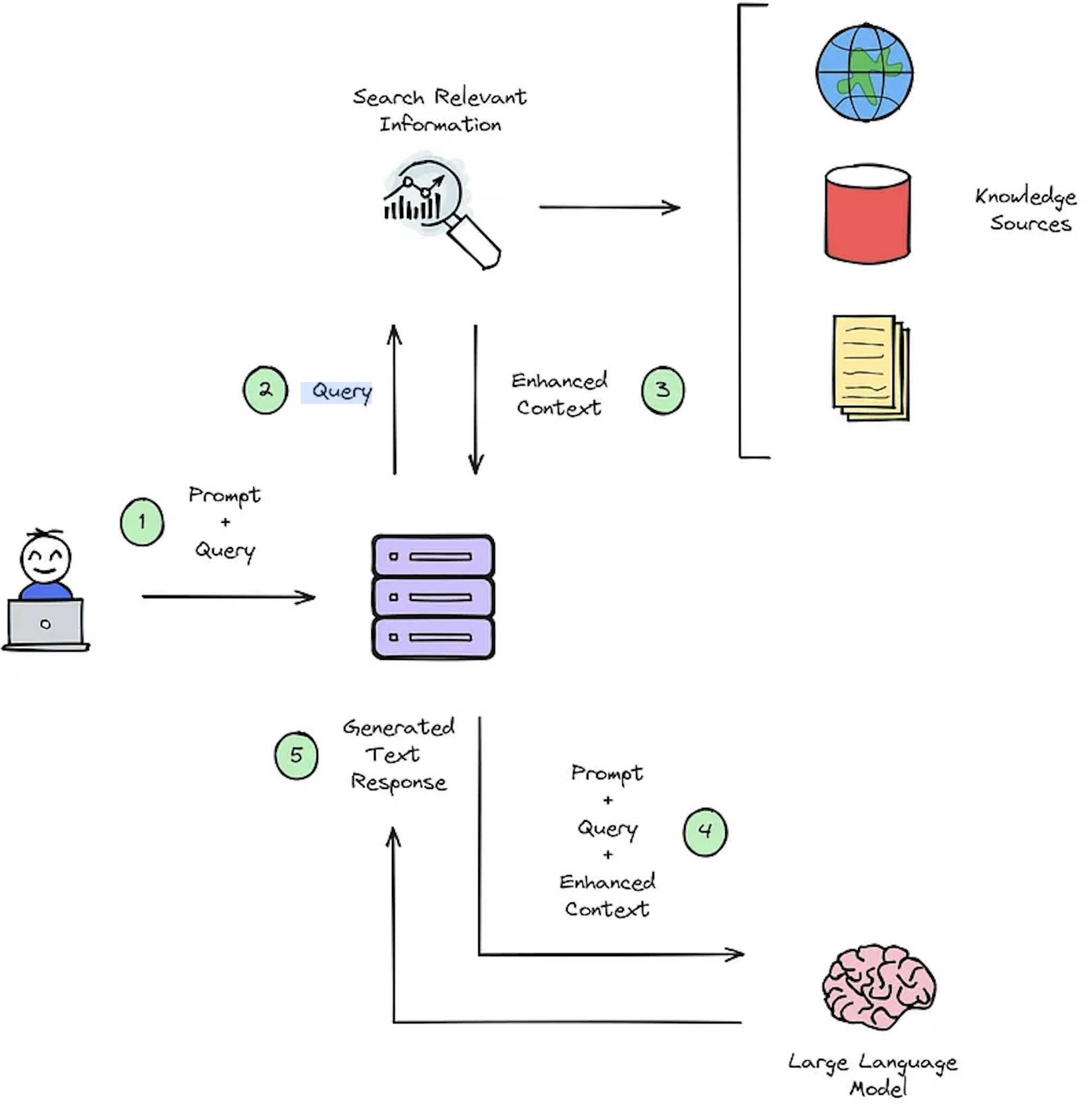
รูปที่ 2: ภาพรวมกระบวนการ RAG [แหล่งที่มา]
ชุดข้อมูลการตอบคำถามบริบทสังเคราะห์นี้มีความสำคัญสำหรับการประเมิน: 1) ความสามารถของระบบของ IR ในการเลือกบริบทที่ปรับปรุงแล้วดังแสดงในรูปที่ 2 - ขั้นตอนที่ #3 และ 2) การตอบสนองที่สร้างขึ้นของ RAG ดังแสดงในรูปที่ 2 - ขั้นตอนที่ #5 โดยการอนุญาตให้มีการประเมินแบบออฟไลน์ทำให้สามารถวิเคราะห์ความสมดุลของระบบอย่างละเอียดระหว่างความเร็วและความแม่นยำแจ้งการแก้ไขที่จำเป็นและเลือกการออกแบบระบบแชมป์
การออกแบบระบบ IR และ RAG มีความซับซ้อนมากขึ้นตามที่อ้างอิงในรูปที่ 3
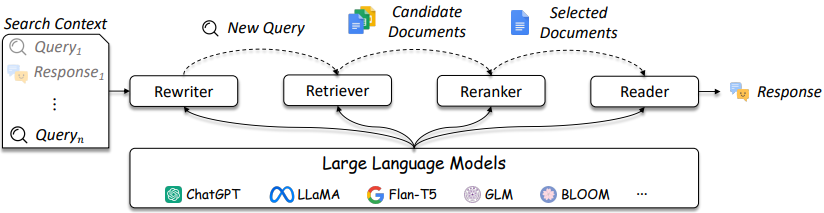
รูปที่ 3: LLM สามารถใช้ในการสืบค้น rewriter, retriever, reranker และ reader [แหล่งที่มา]
ดังที่แสดงให้เห็นว่าพวกเขามีข้อควรพิจารณาหลายประการในการออกแบบและการแก้ปัญหา IR / RAG สามารถมีความซับซ้อนจากวิธีการดั้งเดิม (เช่นวิธีการกระจัดกระจายตามคำศัพท์) ไปจนถึงวิธีการที่ใช้ระบบประสาท (เช่น Embeddings และ LLMs) การประเมินระบบเหล่านี้มีความสำคัญอย่างยิ่งต่อการตัดสินใจออกแบบที่ดี จากการค้นหาไปจนถึงคำแนะนำมาตรการการประเมินเป็นสิ่งสำคัญยิ่งในการทำความเข้าใจสิ่งที่ทำและไม่ทำงานในการดึงข้อมูล
ระบบตอบคำถาม (QA) (เช่นระบบ RAG) มีสององค์ประกอบ:
เมื่อประเมินระบบ QA ทั้งสองส่วนประกอบจำเป็นต้องได้รับการประเมินแยกต่างหากและรวมกันเพื่อให้ได้คะแนนระบบโดยรวม
เมื่อใดก็ตามที่มีการถามคำถามไปยังแอปพลิเคชัน RAG วัตถุต่อไปนี้สามารถพิจารณาได้ [แหล่งที่มา]:
การเลือกตัวชี้วัดไม่ได้เป็นจุดสนใจหลักของที่เก็บนี้เนื่องจากตัวชี้วัดขึ้นอยู่กับแอปพลิเคชัน อย่างไรก็ตามบทความอ้างอิงและข้อมูลมีให้เพื่อความสะดวก
รูปที่ 4 แสดงตัวชี้วัดการประเมินทั่วไปสำหรับ IR และ Dataset จากรูปที่ 1 สามารถใช้สำหรับ Offline Metrics ที่แสดงในรูปที่ 4
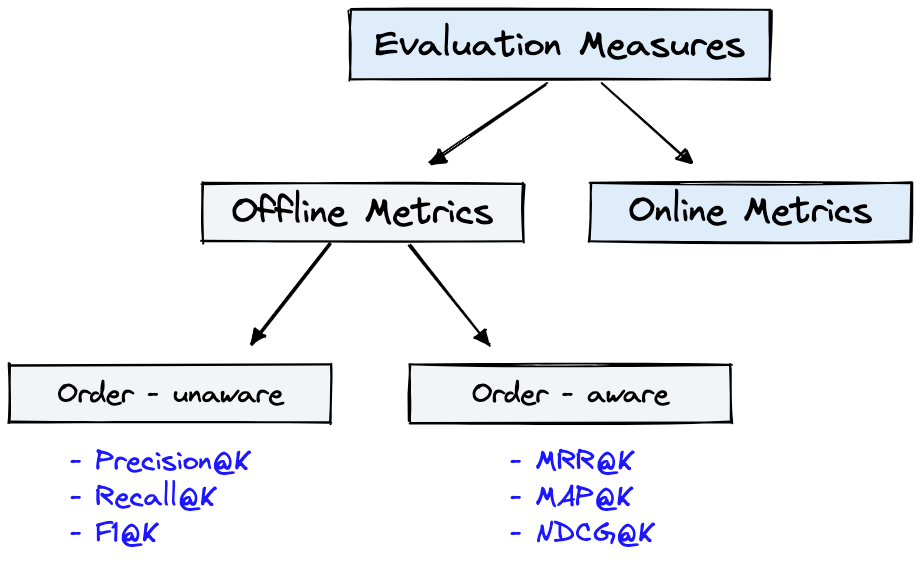
รูปที่ 4: การจัดอันดับตัวชี้วัดการประเมินผล [แหล่งที่มา]
Offline metrics ถูกวัดในสภาพแวดล้อมที่แยกได้ก่อนที่จะปรับใช้ระบบ IR ใหม่ เหล่านี้ดูว่าชุดของผลลัพธ์ที่เกี่ยวข้องจะถูกส่งคืนเมื่อดึงรายการด้วยระบบ [แหล่งที่มา] หรือไม่
การทบทวนสั้น ๆ เกี่ยวกับตัวชี้วัดเครื่องกำเนิดไฟฟ้าจะแสดงความซับซ้อนของการวัดสองสามระดับ เมื่อประเมินเครื่องกำเนิดไฟฟ้าให้ดูว่าหรือในระดับใดข้อความคำตอบที่เลือกจะตรงกับคำตอบหรือคำตอบที่ถูกต้อง
ที่ให้ไว้ด้านล่างนี้เป็นตัวชี้วัดเครื่องกำเนิดที่ระบุไว้อย่างน้อยถึงซับซ้อนที่สุด
โปรดดูบทความ Deepset: ตัวชี้วัดเพื่อประเมินระบบตอบคำถามและประเมินท่อส่งผ้าขี้ริ้วด้วย Ragas + Langsmith ที่อธิบายรายละเอียดเกี่ยวกับตัวชี้วัดเหล่านี้
ประโยชน์ที่สำคัญบางประการของการสร้างข้อมูลสังเคราะห์ด้วยวิศวกรรมพรอมต์ LLM คือ:
Customized IR Task Query Generation : การแจ้งเตือน LLMS มีความยืดหยุ่นอย่างมากในประเภทของการสืบค้นที่สามารถสร้างได้ สิ่งนี้มีประโยชน์เพราะงาน IR แตกต่างกันไปในแอปพลิเคชันของพวกเขา ตัวอย่างเช่นการเปรียบเทียบ-IR (bEIR) เป็นเกณฑ์มาตรฐานที่แตกต่างกันซึ่งมีงาน IR ที่หลากหลายเช่นการตอบคำถามการโต้แย้งหรือการดึงการโต้เถียงการโต้เถียงการตรวจสอบข้อเท็จจริง ฯลฯ เนื่องจากความหลากหลายในงาน IR นี่คือประโยชน์ของการแจ้งเตือน LLM รูปที่ 5 แสดงภาพรวมของงาน IR และชุดข้อมูลที่หลากหลายใน Beir อ้างถึงกระดานผู้นำ Beir เพื่อดูประสิทธิภาพของโมเดลการดึงข้อมูลที่ใช้ NLP 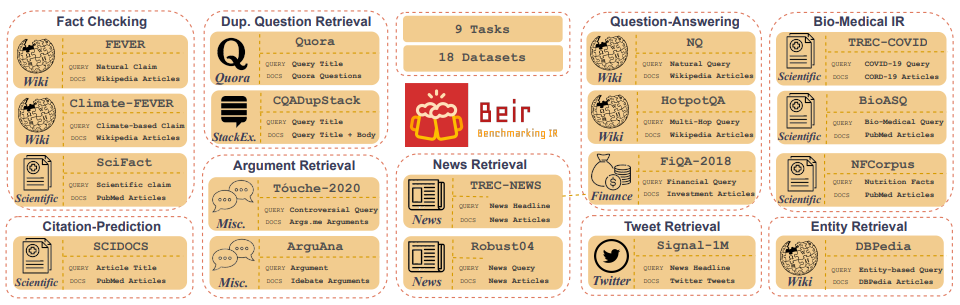
รูปที่ 5: ชุดข้อมูลเบนช์มาร์ก Beir และภาพงาน IR ที่นำมาจาก [แหล่งที่มา]
Zero or Few-Shot Annotations : ในเทคนิคที่เรียกว่าเป็นศูนย์หรือไม่กี่การกระตุ้นการยิงนักพัฒนาสามารถให้ตัวอย่างแบบสอบถามเฉพาะโดเมนให้กับ LLMS เพิ่มการสร้างแบบสอบถามอย่างมาก วิธีการนี้มักจะต้องใช้ตัวอย่างที่มีคำอธิบายประกอบเพียงไม่กี่ตัวอย่างเท่านั้นLonger Context Length : รุ่น LLM ที่ใช้ GPT เช่น LLAMA2 ให้ความยาวบริบทที่ขยายได้สูงถึง 4,096 โทเค็นเมื่อเทียบกับโทเค็น 512 ของ Bert บริบทที่ยาวขึ้นนี้ช่วยเพิ่มการแยกวิเคราะห์เอกสารและการควบคุมการสร้างแบบสอบถามLLAMA2 จะถูกใช้ในที่เก็บนี้สำหรับการสร้างแบบสอบถามสังเคราะห์เพราะสามารถวิ่งได้ในท้องถิ่นบน GPU เกรดผู้บริโภค แสดงด้านล่างเป็นเทมเพลตพรอมต์สำหรับการแชท Llama2 ซึ่งได้รับการปรับแต่งอย่างละเอียดสำหรับแอปพลิเคชันการสนทนาและคำสั่ง
<s>[INST] <<SYS>>
{your_system_message}
<</SYS>>
{user_message_1} [/INST]
<<SYS>> เป็นหนึ่งในข้อได้เปรียบที่ไม่ได้รับการคัดเลือกของโมเดลการเข้าถึงแบบเปิดคือคุณสามารถควบคุมได้อย่างเต็มรูปแบบในการแจ้งเตือนระบบในแอปพลิเคชันแชท นี่เป็นสิ่งสำคัญในการระบุพฤติกรรมของผู้ช่วยแชทของคุณ - และแม้กระทั่งดูดซับมันด้วยบุคลิกบางอย่าง - แต่มันไม่สามารถเข้าถึงได้ในแบบจำลองที่ให้บริการเบื้องหลัง APIs [แหล่งที่มา]โปรดทราบว่าโมเดลพื้นฐาน LLAMA2 ไม่มีโครงสร้างที่รวดเร็วเนื่องจากเป็นรุ่นที่ไม่ได้รับการปรับแต่งแบบดิบ [แหล่งที่มา]
ทรัพยากรเพิ่มเติมและการอ้างอิงเพื่อช่วยในการแจ้งเทคนิคและพื้นฐาน:
Prompt Engineering และ Consistency Filteringที่เก็บนี้จะพยายามอย่างเต็มที่ที่จะได้รับการดูแลรักษา หากคุณประสบปัญหาใด ๆ หรือต้องการทำการปรับปรุงโปรดเพิ่มปัญหาหรือส่งคำขอดึง -


