LangChain SynData RAG Eval
1.0.0
Este repositorio demuestra Langchain, LLAMA2-Chat e ingeniería rápida y pocas disparos para permitir la generación de datos sintéticos para la evaluación de recuperación de información (IR) y de generación aumentada de recuperación (RAG).
INTRODUCCIÓN • Destacados • Notebooks de ejemplo • Antecedentes • Métricas • Beneficios • Plantillas de inmediato • Problemas • TODOS
Los modelos de idiomas grandes (LLM) han transformado la recuperación de información (IR) y la búsqueda al comprender las consultas complejas. Este repositorio muestra conceptos y paquetes que pueden usarse para generar conjuntos de datos sintéticos sofisticados para la evaluación de generación aumentada (RAG) IR y recuperación.
Los datos sintéticos generados son una consulta y respuesta para un contexto dado. A continuación se muestra un ejemplo de una respuesta de contexto generada sintéticamente:
Provided Context (usually split from documents / text sources):
Pure TalkUSA is an American mobile virtual network operator headquartered in Covington, Georgia, United States.
It is most notable for an industry-first offering of rollover data in their data add-on packages, which has since been discontinued.
Pure TalkUSA is a subsidiary of Telrite Corporation. Bring Your Own Phone!
Synthetically Generated Query:
What was the outstanding service offered by Pure TalkUSA?
Synthetically Generated Answer:
The outstanding service from Pure TalkUSA was its industry-first offering of rollover data.
Al construir un sistema IR o RAG, un conjunto de datos de contexto, consultas y respuestas es vital para evaluar el rendimiento del sistema. Los conjuntos de datos anotados por los humanos ofrecen excelentes verdades terrestres, pero pueden ser costosos y difíciles de obtener; Por lo tanto, los conjuntos de datos sintéticos generados usando LLM es una solución y un suplemento atractivos.
Al emplear la ingeniería rápida de LLM, se puede generar una amplia gama de consultas y respuestas sintéticas para formar un conjunto de datos de validación robusto. Este repositorio muestra un proceso para generar datos sintéticos al tiempo que enfatiza la solicitud de cero y pocos disparos para crear conjuntos de datos sintéticos altamente personalizables. La Figura 1 describe el proceso de generación de conjuntos de datos sintéticos demostrado en este repositorio.
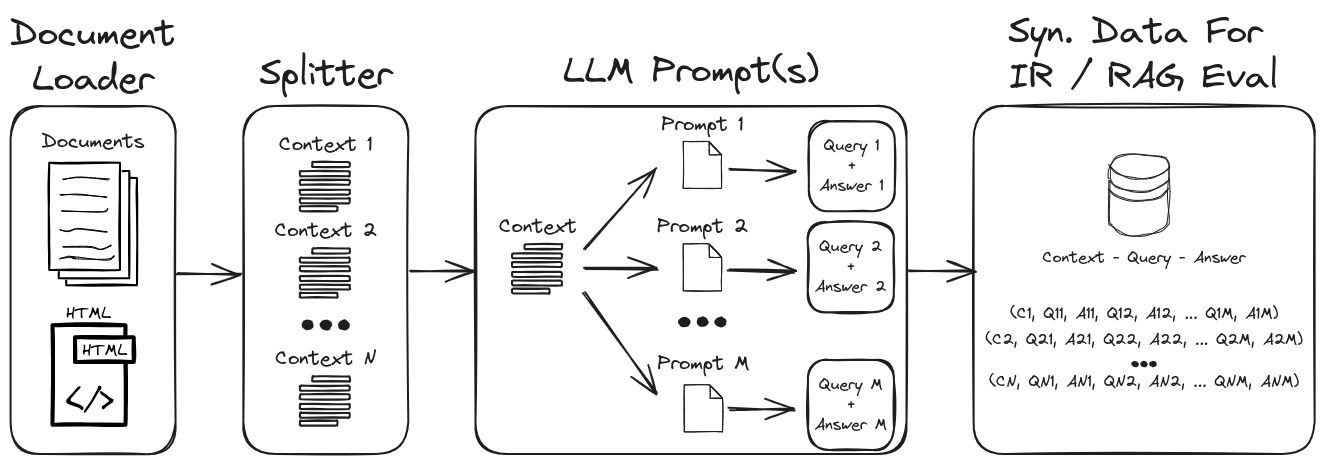
Figura 1: Generación de datos sintéticos para la evaluación de IR y RAG
Nota : Consulte las secciones de antecedentes y métricas para obtener una inmersión más profunda en IR, RAG y cómo evaluar estos sistemas.
Algunos de los aspectos más destacados en el repositorio son:
1.) Langchain con indicadores personalizados y analizadores de salida para la salida de datos estructurados : consulte Gen-Question-RespSwer-Query.ipynb para un ejemplo de generación de datos sintética de contexto-cuidera-respuesta. Los aspectos clave de este cuaderno son:
1.) Langchain Custom Llama2-Chat Involucrar : consulte QA-Gen-Query-Langchain.ipynb para un ejemplo de cómo construir plantillas de solicitud personalizadas de Langchain para la generación de cuidias de contexto. Algunas de las características de Langchain que se muestran en este cuaderno son:
1.) Ingeniería rápida de cero y pocos disparos : consulte QA-Gen-Query.ipynb para un ejemplo de generación de datos de Cuidera de contexto sintético para conjuntos de datos personalizados. Las características clave presentadas aquí son:
zero- and few-shot annotations en el conjunto de datos de preguntas sobre la pregunta Squadv2.2.) Argumento de contexto : ver argumento-Gen-Query.ipynb Para ejemplos de datos sintéticos de cuidante de contexto para tareas de recuperación de argumentos. En el contexto de la recuperación de la información, estas tareas están diseñadas para recuperar argumentos relevantes de varias fuentes, como documentos. En la recuperación de argumentos, el objetivo es proporcionar a los usuarios información persuasiva y creíble para respaldar sus argumentos o tomar decisiones informadas.
Otros ejemplos de modelos de generación específicos de consultas (p. Ej., BeIR/query-gen-msmarco-t5-base-v1 ) se pueden encontrar fácilmente en línea (ver Generación de preguntas de Beir).
La función principal de un sistema IR es la recuperación, cuyo objetivo es determinar la relevancia entre la consulta de los usuarios y el contenido a recuperar. La implementación de un sistema IR o RAG exige documentos específicos del usuario. Sin embargo, la falta de datos de datos anotados para conjuntos de datos personalizados cuestiona la evaluación del sistema. La Figura 2 proporciona una descripción general de un proceso de trapo típico para un sistema de preguntas y respuestas.
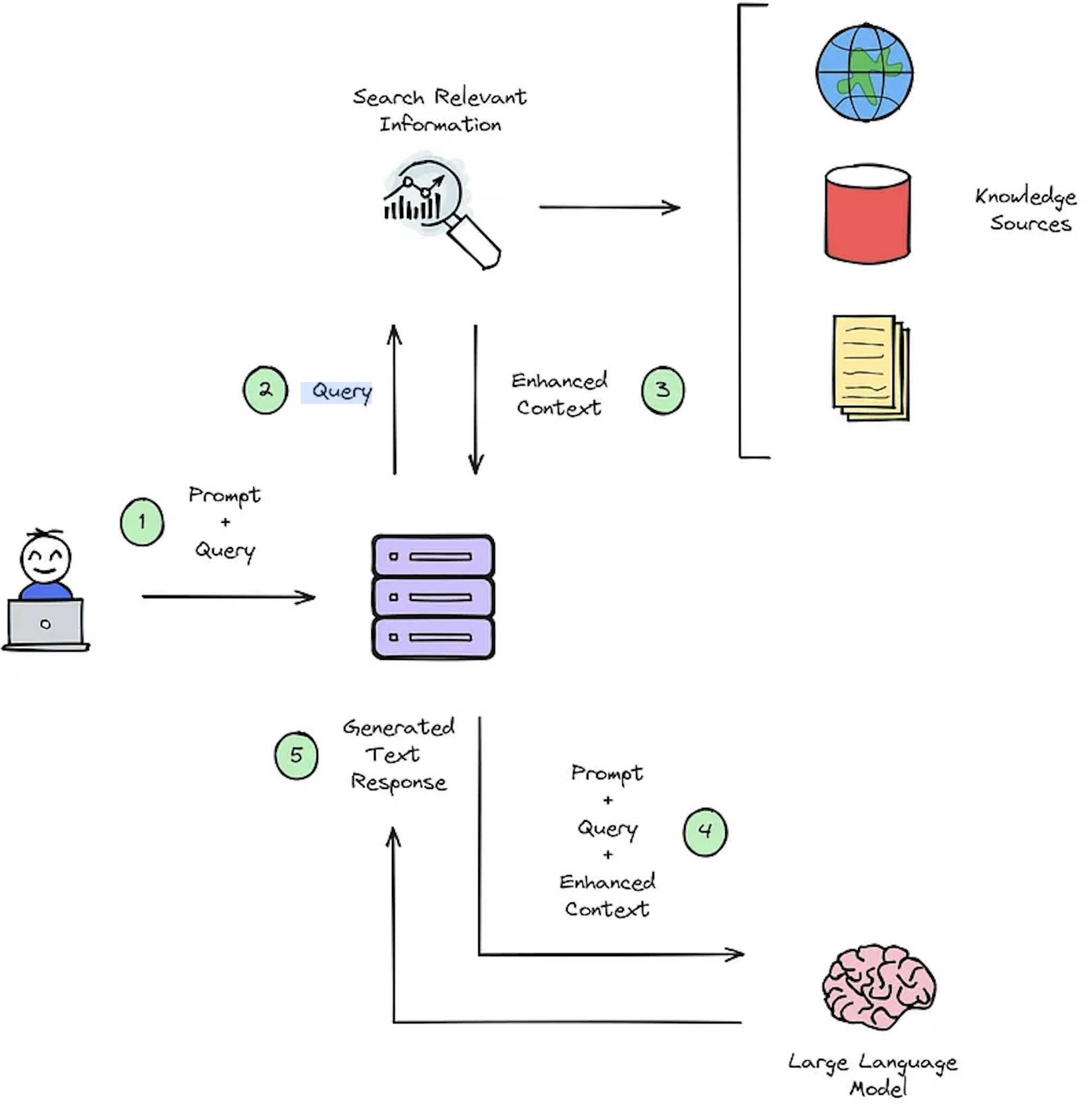
Figura 2: Descripción general del proceso de RAG [fuente].
Estos conjuntos de datos sintéticos de contexto de respuesta -respuesta son cruciales para evaluar: 1) La capacidad de los sistemas de IR para seleccionar el contexto mejorado como se ilustra en la Figura 2 - Paso #3 y 2) La respuesta generada del RAG como se muestra en la Figura 2 - Paso #5. Al permitir la evaluación fuera de línea, permite un análisis exhaustivo del equilibrio del sistema entre velocidad y precisión, informando las revisiones necesarias y seleccionando diseños de sistemas de campeones.
El diseño de los sistemas IR y RAG se está volviendo más complicado como se hace referencia en la Figura 3.
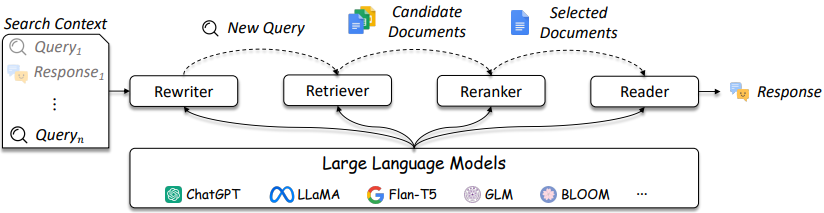
Figura 3: LLMS se puede usar en Consuly Rewriter, Retriever, Reranker y Reader [fuente]
Como se muestra, hay varias consideraciones en el diseño y las soluciones IR / RAG pueden variar en la complejidad de los métodos tradicionales (por ejemplo, métodos dispersos basados en términos) hasta métodos neurales (por ejemplo, incrustaciones y LLM). La evaluación de estos sistemas es fundamental para tomar decisiones de diseño bien informadas. Desde la búsqueda hasta las recomendaciones, las medidas de evaluación son primordiales para comprender lo que funciona y no funciona en la recuperación.
Los sistemas de respuesta a la pregunta (QA) (por ejemplo, sistema RAG) tienen dos componentes:
Al evaluar un sistema de control de calidad, ambos componentes deben evaluarse por separado y juntos para obtener una puntuación general del sistema.
Cada vez que se hace una pregunta a una aplicación RAG, los siguientes objetos pueden considerarse [fuente]:
La selección de métricas no es un foco principal de este repositorio, ya que las métricas dependen de la aplicación; Sin embargo, los artículos de referencia e información se proporcionan por conveniencia.
La Figura 4 muestra métricas de evaluación comunes para IR y el Dataset de la Figura 1 se puede utilizar para las Offline Metrics que se muestran en la Figura 4.
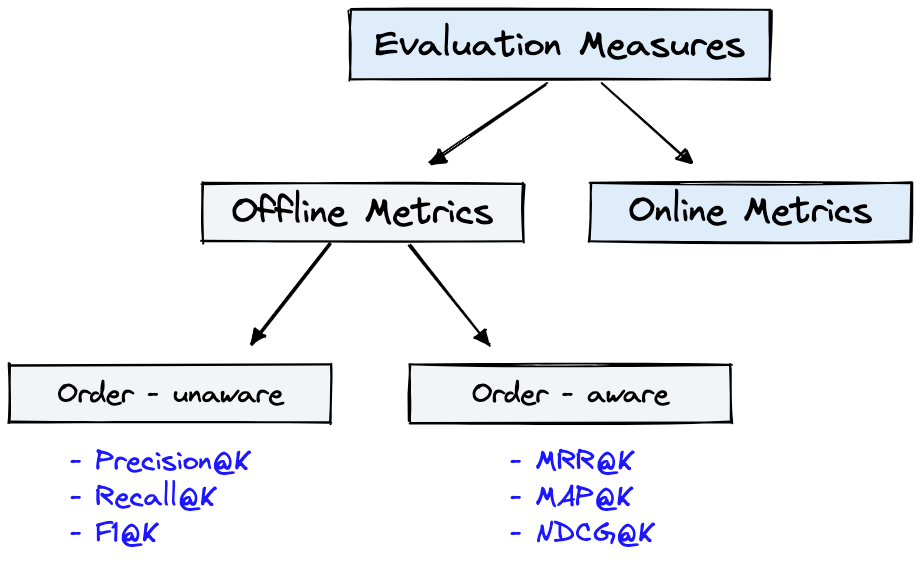
Figura 4: Métricas de evaluación de clasificación [fuente]
Offline metrics se miden en un entorno aislado antes de implementar un nuevo sistema IR. Estos observan si se devuelve un conjunto particular de resultados relevantes al recuperar elementos con el sistema [fuente].
Una breve revisión de las métricas del generador mostrará algunos niveles de complejidad métrica. Al evaluar el generador, mire si, o en qué medida, los pasajes de respuesta seleccionados coinciden con las respuestas o respuestas correctas.
A continuación se proporcionan métricas del generador enumeradas en orden de menos a la más compleja.
Consulte el artículo DeepSet: Métricas para evaluar un sistema de respuesta de preguntas y evaluar las tuberías de RAG con ragas + langsmith que elaboran estas métricas.
Algunos beneficios clave de la generación de datos sintéticos con la ingeniería rápida de LLM son:
Customized IR Task Query Generation : la solicitud de LLM ofrece una gran flexibilidad en los tipos de consultas que se pueden generar. Esto es útil porque las tareas IR varían en su aplicación. Por ejemplo, Benchmarking-IR (Beir) es un punto de referencia heterogéneo que contiene diversas tareas IR, como la respuesta de pregunta, la recuperación de argumentos o contra el contratación, la verificación de hechos, etc. debido a la diversidad en las tareas IR, es donde los beneficios de la provisión de LLM pueden ser excelentes porque se puede adaptar el aviso para generar datos sintéticos a la tarea IR. La Figura 5 muestra una descripción general de las diversas tareas y conjuntos de datos IR en Beir. Consulte la tabla de clasificación de Beir para ver el rendimiento de los modelos de recuperación basados en PNL. 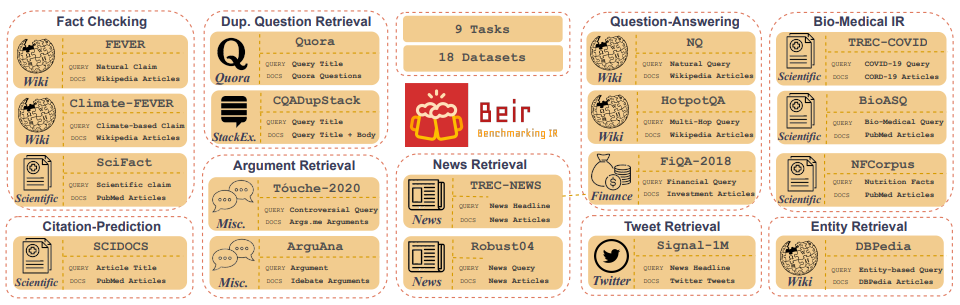
Figura 5: imagen de datos de referencia de Beir y tareas IR Imagen tomada de [Fuente]
Zero or Few-Shot Annotations : en una técnica denominada indicación cero o de pocos disparos, los desarrolladores pueden proporcionar consultas de ejemplo específicas de dominio a LLM, mejorando en gran medida la generación de consultas. Este enfoque a menudo requiere solo un puñado de muestras anotadas.Longer Context Length : los modelos LLM basados en GPT, como LLAMA2, proporcionan longitudes de contexto extendidas, hasta 4,096 tokens en comparación con los 512 tokens de Bert. Este contexto más largo mejora el análisis de documentos y el control de la generación de consultas.LLAMA2 se utilizará en este repositorio para generar consultas sintéticas porque se puede ejecutar localmente en GPU de grado de consumo. A continuación se muestra la plantilla de inmediato para el chat LLAMA2 que fue ajustado para las aplicaciones de diálogo e instrucciones.
<s>[INST] <<SYS>>
{your_system_message}
<</SYS>>
{user_message_1} [/INST]
<<SYS>> es una de las ventajas no reconocidas de los modelos de acceso abierto es que tiene control total sobre la solicitud del sistema en las aplicaciones de chat. Esto es esencial para especificar el comportamiento de su asistente de chat, e incluso imbuirlo con cierta personalidad, pero es inalcanzable en los modelos servidos detrás de API [fuente].Tenga en cuenta que los modelos Base LLAMA2 no tienen una estructura rápida porque son modelos sinstructos sinstuctos en bruto [fuente].
Recursos y referencias adicionales para ayudar con las técnicas y conceptos básicos de incorporación:
Prompt Engineering y Consistency Filtering .Este repositorio hará todo lo posible para mantenerse. Si enfrenta algún problema o desea realizar mejoras, plantee un problema o envíe una solicitud de extracción. ?


