LangChain SynData RAG Eval
1.0.0
Ce référentiel démontre Langchain, LLAMA2-CHAT et l'ingénierie rapide et à quelques coups pour permettre une génération de données synthétiques pour la récupération des informations (IR) et l'évaluation de la génération augmentée (RAG).
INTRODUCTION • Faits saillants • Exemple de carnets • Contexte • Mestric
Les modèles de grands langues (LLM) ont transformé la récupération des informations (IR) et la recherche en comprenant des requêtes complexes. Ce référentiel présente des concepts et des packages qui peuvent être utilisés pour générer des ensembles de données synthétiques sophistiqués pour l'évaluation de la génération augmentée IR et de récupération.
Les données synthétiques générées sont une requête et une réponse pour un contexte donné. Un exemple de réponses de contexte de contexte généré synthétiquement est illustré ci-dessous:
Provided Context (usually split from documents / text sources):
Pure TalkUSA is an American mobile virtual network operator headquartered in Covington, Georgia, United States.
It is most notable for an industry-first offering of rollover data in their data add-on packages, which has since been discontinued.
Pure TalkUSA is a subsidiary of Telrite Corporation. Bring Your Own Phone!
Synthetically Generated Query:
What was the outstanding service offered by Pure TalkUSA?
Synthetically Generated Answer:
The outstanding service from Pure TalkUSA was its industry-first offering of rollover data.
Lors de la construction d'un système IR ou RAG, un ensemble de données de contexte, de requêtes et de réponses est essentiel pour évaluer les performances du système. Les ensembles de données annotés par l'homme offrent d'excellentes vérités au sol mais peuvent être coûteuses et difficiles à obtenir; Par conséquent, les ensembles de données synthétiques générés à l'aide de LLMS sont une solution et un supplément attrayants.
En utilisant l'ingénierie rapide de LLM, une gamme diversifiée de requêtes et de réponses synthétiques peut être générée pour former un ensemble de données de validation robuste. Ce référentiel présente un processus pour générer des données synthétiques tout en mettant l'accent sur des invites à zéro et à quelques coups pour créer des ensembles de données synthétiques hautement personnalisables. La figure 1 décrit le processus de génération d'ensemble de données synthétique démontré dans ce référentiel.
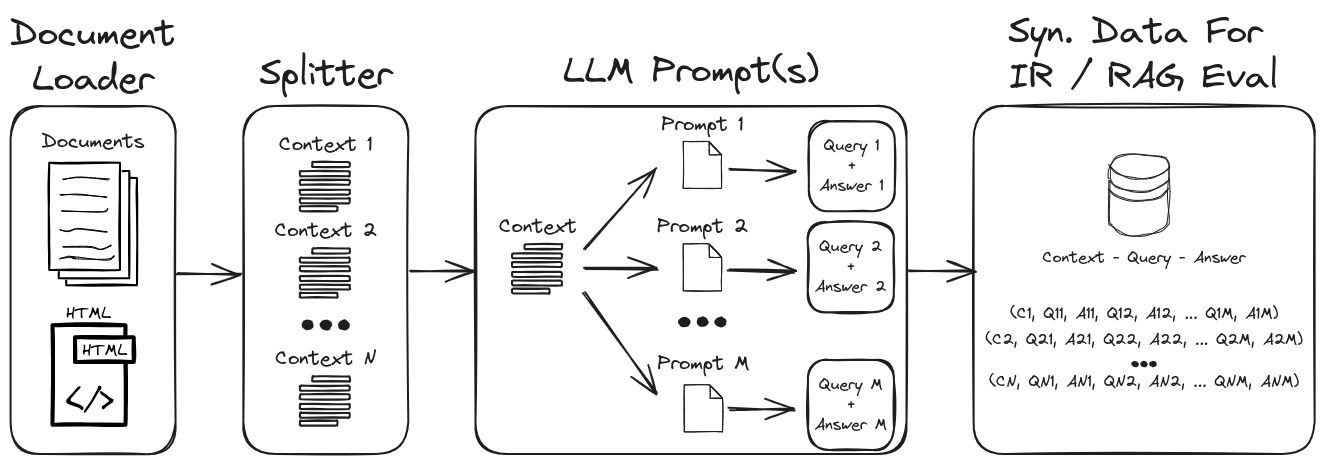
Figure 1: Génération de données synthétiques pour l'évaluation IR et RAG
Remarque : reportez-vous aux sections de fond et de métriques pour une plongée plus profonde sur l'IR, le RAG et comment évaluer ces systèmes.
Quelques-uns des points saillants clés du référentiel sont:
1.) Langchain avec des invites personnalisées et des analyseurs de sortie pour la sortie de données structurées : voir Gen-Question-Answer-query.ipynb pour un exemple de génération de données de contexte de contexte synthétique. Les aspects clés de ce cahier sont:
1.) Langchain Custom Llama2-Chat Invition : Voir QA-Gen-Queery-Langchain.Ipynb pour un exemple de la façon de créer des modèles d'invite personnalisés de Langchain pour la génération de contexte-Querey. Quelques-unes des fonctionnalités de Langchain présentées dans ce cahier sont:
1.) Ingénierie rapide zéro et à quelques coups : voir QA-Gen-query.ipynb pour un exemple de génération de données de contexte synthétique pour les ensembles de données personnalisés. Les caractéristiques clés présentées ici sont:
zero- and few-shot annotations sur l'ensemble de données de réponses de questions SKADV2.2.) Context-Arugment : Voir Argument-Gen-query.Ipynb pour des exemples de données de contexte synthétique-Querey pour les tâches de récupération d'arguments. Dans le contexte de la récupération de l'information, ces tâches sont conçues pour récupérer les arguments pertinents de diverses sources telles que les documents. Dans la récupération d'arguments, l'objectif est de fournir aux utilisateurs des informations persuasives et crédibles pour soutenir leurs arguments ou prendre des décisions éclairées.
D'autres exemples de modèles de génération spécifique à la requête (par exemple, BeIR/query-gen-msmarco-t5-base-v1 ) peuvent être facilement trouvés en ligne (voir la génération de questions de Beir).
La fonction principale d'un système IR est la récupération, qui vise à déterminer la pertinence entre la requête des utilisateurs et le contenu à récupérer. La mise en œuvre d'un système IR ou RAG exige des documents spécifiques à l'utilisateur. Cependant, le manque d'ensembles de données annotés pour les ensembles de données personnalisés entrave l'évaluation du système. La figure 2 donne un aperçu d'un processus de chiffon typique pour un système de réponses aux questions.
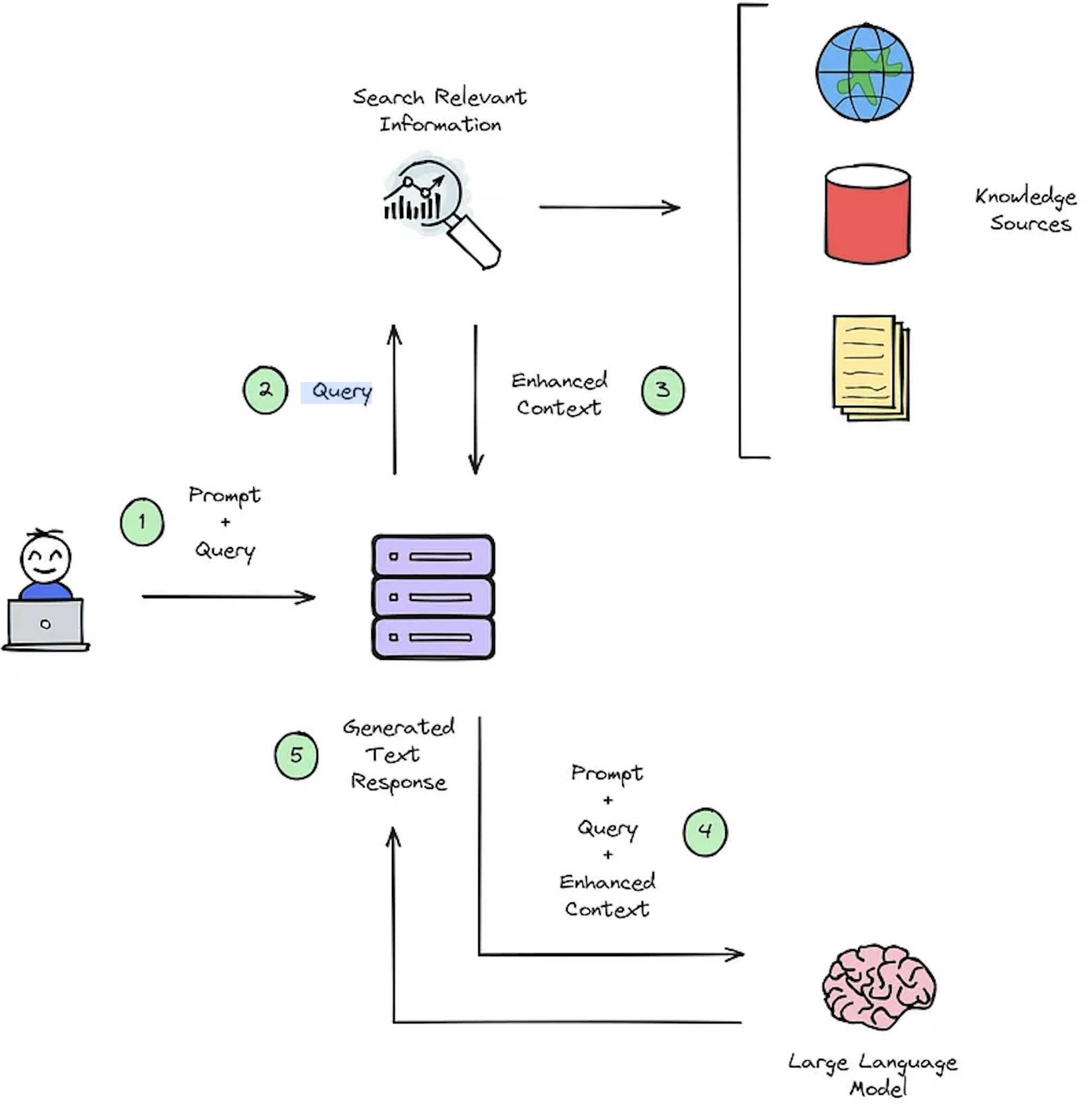
Figure 2: Présentation du processus de chiffon [Source].
Ces ensembles de données synthétiques contextuels-remergers sont cruciaux pour évaluer: 1) la capacité des systèmes de l'IR à sélectionner le contexte amélioré comme illustré à la figure 2 - Étape # 3 et 2) La réponse générée du RAG comme le montre la figure 2 - Étape # 5. En permettant une évaluation hors ligne, il permet une analyse approfondie de l'équilibre du système entre la vitesse et la précision, informant les révisions nécessaires et sélectionnant les conceptions du système champion.
La conception des systèmes IR et RAG devient plus compliquée comme le référencé dans la figure 3.
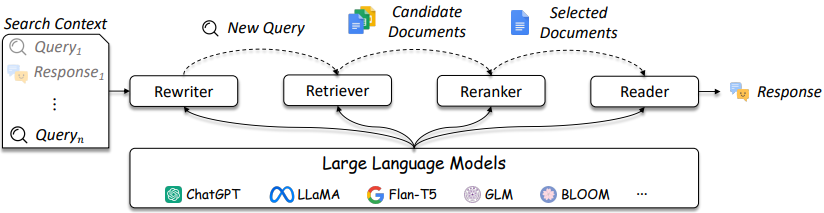
Figure 3: LLMS peut être utilisé dans Rewriter, Retriever, Reranker et Reader [Source]
Comme illustré, il s'agit de plusieurs considérations dans la conception IR / RAG et les solutions peuvent aller en complexité des méthodes traditionnelles (par exemple, méthodes clairsemées à terme) aux méthodes neuronales (par exemple, les intégres et les LLM). L'évaluation de ces systèmes est essentielle pour prendre des décisions de conception bien informées. De la recherche aux recommandations, les mesures d'évaluation sont primordiales pour comprendre ce qui fonctionne et ne fonctionne pas dans la récupération.
Les systèmes de réponses aux questions (QA) (par exemple, système de chiffon) ont deux composants:
Lors de l'évaluation d'un système QA, les deux composants doivent être évalués séparément et ensemble pour obtenir un score du système global.
Chaque fois qu'une question est posée à une application de chiffon, les objets suivants peuvent être pris en compte [source]:
La sélection des mesures n'est pas un objectif principal de ce référentiel car les métriques dépendent de l'application; Cependant, des articles et des informations de référence sont fournis pour la commodité.
La figure 4 montre des mesures d'évaluation courantes pour l'IR et l' Dataset de la figure 1 peut être utilisée pour les Offline Metrics illustrées à la figure 4.
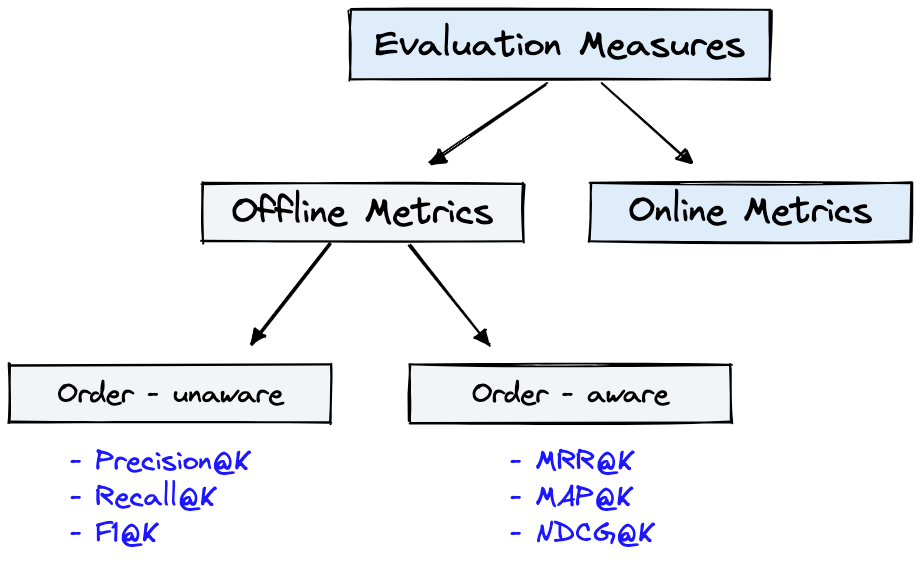
Figure 4: Métriques d'évaluation de classement [Source]
Offline metrics sont mesurées dans un environnement isolé avant de déployer un nouveau système IR. Ceux-ci examinent si un ensemble particulier de résultats pertinents est renvoyé lors de la récupération des éléments avec le système [source].
Un bref examen des métriques des générateurs présentera quelques niveaux de complexité métrique. Lors de l'évaluation du générateur, regardez si, ou dans quelle mesure, les passages de réponse sélectionnés correspondent à la bonne réponse ou aux réponses.
Vous trouverez ci-dessous les métriques des générateurs répertoriées par ordre du moins au plus complexe.
Veuillez vous référer à l'article Deepset: Metrics pour évaluer un système de réponse aux questions et évaluer les pipelines de chiffon avec Ragas + Langsmith qui expliquent ces mesures.
Quelques avantages clés de la génération de données synthétiques avec l'ingénierie rapide LLM sont:
Customized IR Task Query Generation : l'incitation aux LLMS offrent une grande flexibilité dans les types de requêtes qui peuvent être générées. Cela est utile car les tâches IR varient dans leur application. Par exemple, l'analyse comparative-IR (BEIR) est une référence hétérogène contenant diverses tâches IR telles que les questions de questionnement, l'argument ou la récupération de contre-argument, la vérification des faits, etc. En raison de la diversité des tâches IR, ce qui est là que les avantages de la Proboration ILM peuvent être l'excellence car l'invite peut être adaptée à générer des données synthétiques à la tâche IR. La figure 5 montre un aperçu des diverses tâches IR et ensembles de données dans Beir. Reportez-vous au classement Beir pour voir les performances des modèles de récupération basés sur NLP. 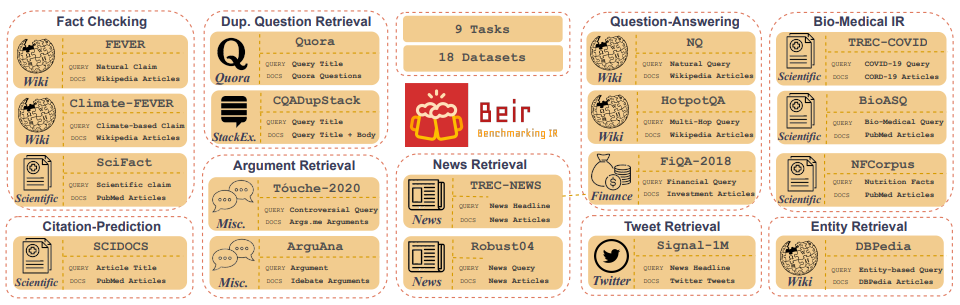
Figure 5: Les ensembles de données de référence Beir et l'image des tâches IR tirées de [Source]
Zero or Few-Shot Annotations : dans une technique appelée invitation nulle ou à quelques coups, les développeurs peuvent fournir des exemples de requêtes spécifiques au domaine aux LLM, améliorant considérablement la génération de requêtes. Cette approche ne nécessite souvent qu'une poignée d'échantillons annotés.Longer Context Length : les modèles LLM basés sur GPT, comme LLAMA2, fournissent des longueurs de contexte étendues, jusqu'à 4 096 jetons par rapport aux 512 jetons de Bert. Ce contexte plus long améliore l'analyse des documents et le contrôle de la génération de requêtes.LLAMA2 sera utilisé dans ce référentiel pour générer des requêtes synthétiques car elle peut être exécutée localement sur les GPU de qualité consommatrice. Ci-dessous, le modèle d'invite pour le chat LLAMA2 qui était affiné pour le dialogue et les applications d'instructions.
<s>[INST] <<SYS>>
{your_system_message}
<</SYS>>
{user_message_1} [/INST]
<<SYS>> est l'un des avantages méconnus des modèles à accès ouvert est que vous avez un contrôle total sur l'invite du système dans les applications de chat. Ceci est essentiel pour spécifier le comportement de votre assistant de chat - et même l'imprégner avec une certaine personnalité, mais il est inaccessible dans les modèles servis derrière les API [source].Notez que les modèles Base LLAMA2 n'ont pas de structure rapide car ce sont des modèles ajustés bruts non instruits [source].
Ressources et références supplémentaires pour aider à inciter les techniques et les bases:
Consistency Filtering Prompt Engineering et la cohérence.Ce référentiel fera de son mieux pour être maintenu. Si vous rencontrez un problème ou si vous souhaitez apporter des améliorations, veuillez soulever un problème ou soumettre une demande de traction. ?


