LangChain SynData RAG Eval
1.0.0
Este repositório demonstra a engenharia de Langchain, LLAMA2-CAT e zero e poucos anos para permitir a geração de dados sintéticos para recuperação de informações (IR) e avaliação de geração aumentada (RAG).
Introdução • Destaques • Exemplo de notebooks • Antecedentes • Métricas • Benefícios • Modelos de promotos • Problemas • Todos
Os grandes modelos de idiomas (LLMs) transformaram a recuperação de informações (IR) e a pesquisa compreendendo consultas complexas. Este repositório mostra conceitos e pacotes que podem ser usados para gerar conjuntos de dados sintéticos sofisticados para avaliação de geração Aumentada por IR e recuperação (RAG).
Os dados sintéticos gerados é uma consulta e resposta para um determinado contexto. Um exemplo de uma resposta de contexto gerado sinteticamente é mostrado abaixo:
Provided Context (usually split from documents / text sources):
Pure TalkUSA is an American mobile virtual network operator headquartered in Covington, Georgia, United States.
It is most notable for an industry-first offering of rollover data in their data add-on packages, which has since been discontinued.
Pure TalkUSA is a subsidiary of Telrite Corporation. Bring Your Own Phone!
Synthetically Generated Query:
What was the outstanding service offered by Pure TalkUSA?
Synthetically Generated Answer:
The outstanding service from Pure TalkUSA was its industry-first offering of rollover data.
Ao criar um sistema de RI ou RAG, um conjunto de dados de contexto, consultas e respostas é vital para avaliar o desempenho do sistema. Os conjuntos de dados indicados pelo homem oferecem excelentes verdades fundamentais, mas podem ser caros e desafiadores de obter; Portanto, conjuntos de dados sintéticos gerados usando LLMS é uma solução e suplemento atraentes.
Ao empregar engenharia prompt de LLM, uma gama diversificada de consultas e respostas sintéticas pode ser gerada para formar um conjunto de dados de validação robusto. Este repositório mostra um processo para gerar dados sintéticos, enfatizando o processo de zero e poucas fotos para criar conjuntos de dados sintéticos altamente personalizáveis. A Figura 1 descreve o processo de geração de conjunto de dados sintético demonstrado neste repositório.
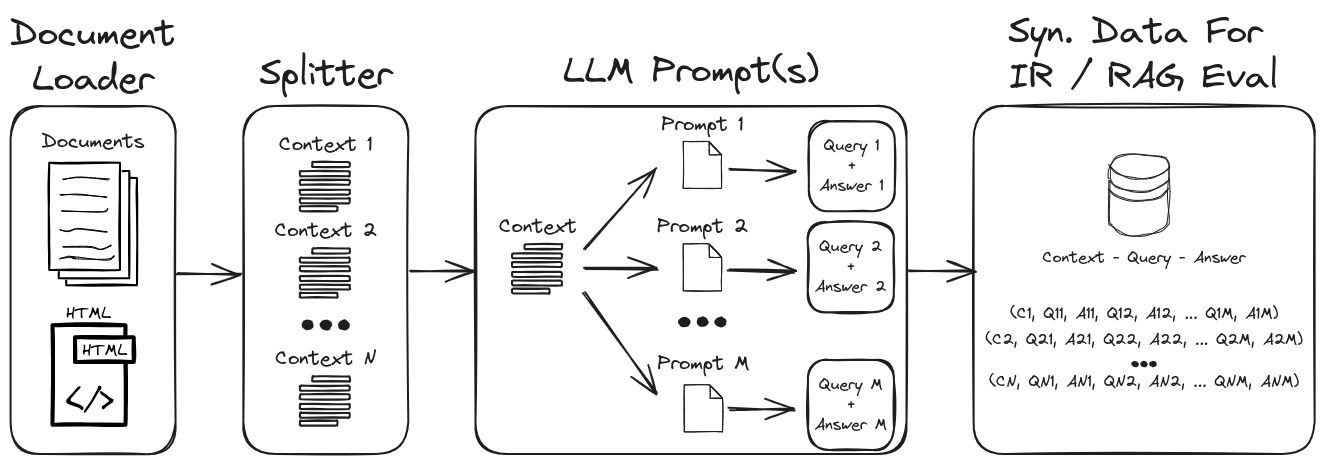
Figura 1: Geração de dados sintéticos para avaliação de IR e RAG
Nota : Consulte as seções de segundo plano e métricas para um mergulho mais profundo no IR, RAG e como avaliar esses sistemas.
Alguns dos principais destaques do repositório são:
1.) Langchain com avisos personalizados e analisadores de saída para saída de dados estruturados : consulte Gen-question-Answer-Query.ipynb para obter um exemplo de geração de dados sintética de contexto-flor-resposta. Os principais aspectos deste caderno são:
1.) Langchain personalizado llama2-chat solicitando : consulte o QA-GEN-QUERY-LANGCHAIN.IPYNB para um exemplo de como criar modelos de prompt personalizados Langchain para geração de contexto. Alguns dos recursos de Langchain mostrados neste caderno são:
1.) Engenharia de prompt de zero e poucos tiro : consulte a geração de dados de QA-Gen-Query.ipynb para obter um exemplo de geração de dados de margem sintética para conjuntos de dados personalizados. Os principais recursos apresentados aqui são:
zero- and few-shot annotations no conjunto de dados de resposta a perguntas do esquadrão.2.) Argumentação do Contexto : consulte Argument-Gen-Query.ipynb para obter exemplos de dados sintéticos de margem de contexto para tarefas de recuperação de argumentos. No contexto da recuperação de informações, essas tarefas são projetadas para recuperar argumentos relevantes de várias fontes, como documentos. Na recuperação de argumentos, o objetivo é fornecer aos usuários informações persuasivas e credíveis para apoiar seus argumentos ou tomar decisões informadas.
Outros exemplos de modelos de geração específica de consulta (por exemplo, BeIR/query-gen-msmarco-t5-base-v1 ) podem ser facilmente encontrados online (ver geração de perguntas da Beir).
A principal função de um sistema de IR é a recuperação, que visa determinar a relevância entre a consulta de um usuário e o conteúdo a ser recuperado. A implementação de um sistema IR ou RAG exige documentos específicos do usuário. No entanto, falta de conjuntos de dados anotados para conjuntos de dados personalizados HAMPERS SYSTEM Avaliação. A Figura 2 fornece uma visão geral de um processo típico de RAG para um sistema de resposta a perguntas.
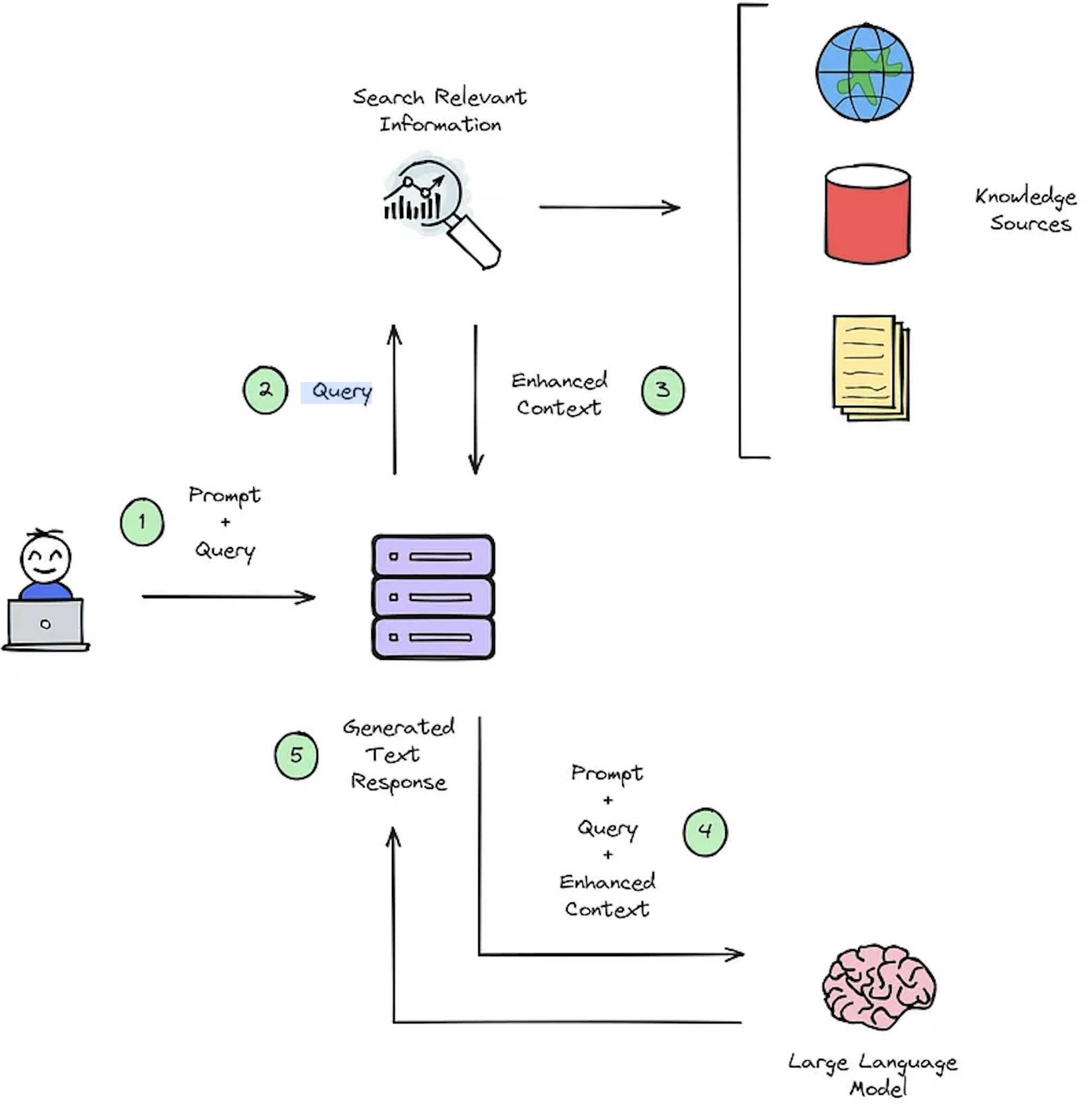
Figura 2: Visão geral do processo do RAG [Fonte].
Esses conjuntos de dados sintéticos de respostas ao contexto de contexto são cruciais para avaliar: 1) a capacidade dos sistemas do IR de selecionar o contexto aprimorado, conforme ilustrado na Figura 2 - Etapa 3 e 2) a resposta gerada pelo RAG, como mostrado na Figura 2 - Etapa #5. Ao permitir a avaliação offline, ele permite uma análise completa do equilíbrio do sistema entre velocidade e precisão, informando as revisões necessárias e selecionando os projetos de sistemas campeões.
O design dos sistemas de RI e RAG está se tornando mais complicado, conforme referenciado na Figura 3.
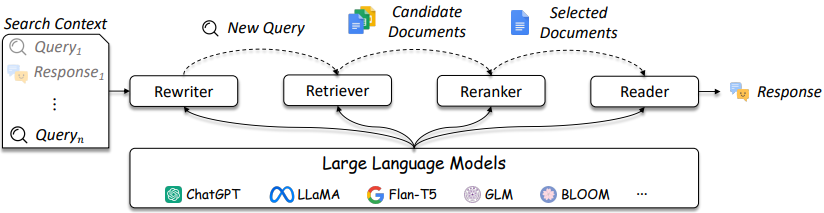
Figura 3: Os LLMs podem ser usados no Rewriter, Retriever, Reranker e Leitor [fonte]
Como mostrado, são várias considerações no design e soluções de IR / RAG podem variar em complexidade dos métodos tradicionais (por exemplo, métodos esparsos baseados em termos) a métodos baseados em neurais (por exemplo, incorporação e LLMS). A avaliação desses sistemas é fundamental para tomar decisões de design bem informadas. Da pesquisa às recomendações, as medidas de avaliação são fundamentais para entender o que faz e não funcionam na recuperação.
Os sistemas de resposta à pergunta (controle de qualidade) (por exemplo, sistema de pano) têm dois componentes:
Ao avaliar um sistema de controle de qualidade, ambos os componentes precisam ser avaliados separadamente e juntos para obter uma pontuação geral do sistema.
Sempre que uma pergunta é feita para um aplicativo RAG, os seguintes objetos podem ser considerados [fonte]:
A seleção de métricas não é o foco principal deste repositório, uma vez que as métricas são dependentes de aplicação; No entanto, artigos e informações de referência são fornecidos para conveniência.
A Figura 4 mostra métricas de avaliação comuns para IR e o Dataset da Figura 1 podem ser usados para as Offline Metrics mostradas na Figura 4.
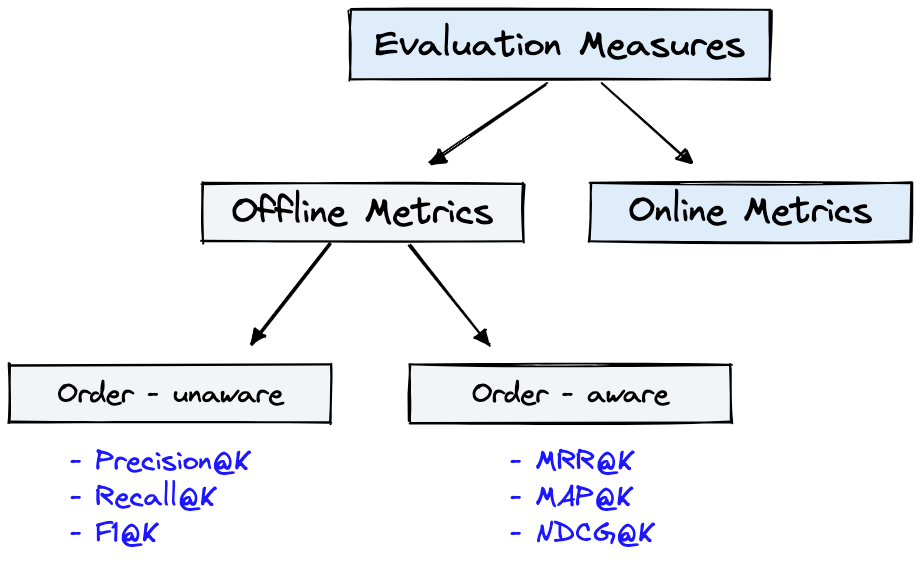
Figura 4: Métricas de avaliação de classificação [fonte]
Offline metrics são medidas em um ambiente isolado antes de implantar um novo sistema de IR. Eles analisam se um conjunto específico de resultados relevantes é retornado ao recuperar itens com o sistema [fonte].
Uma breve revisão das métricas do gerador mostrará alguns níveis de complexidade métrica. Ao avaliar o gerador, observe se, ou até que ponto, as passagens de resposta selecionadas correspondem à resposta ou resposta correta.
Abaixo estão as métricas do gerador listadas em ordem de menos para o mais complexo.
Consulte o artigo DeepSet: Métricas para avaliar um sistema de resposta a perguntas e avaliar os pipelines RAG com Ragas + Langsmith que elaboram essas métricas.
Alguns benefícios importantes da geração de dados sintéticos com a engenharia prompt de LLM são:
Customized IR Task Query Generation : A Prompting LLMS oferece grande flexibilidade nos tipos de consultas que podem ser geradas. Isso é útil porque as tarefas de RI variam em sua aplicação. Por exemplo, o benchmarking-IR (Beir) é um benchmark heterogêneo que contém diversas tarefas de RI, como resposta a perguntas, argumento ou recuperação de argumentos, verificação de fatos, etc. Devido à diversidade nas tarefas de RI, é onde os benefícios do LLM solicitam a excelência porque a prompt pode ser atendida para gerar os dados sintéticos para o Synthetic para o IRT para o IRM para o SIMT para o IR. A Figura 5 mostra uma visão geral das diversas tarefas de IR e conjuntos de dados em Beir. Consulte a tabela de classificação da Beir para ver o desempenho dos modelos de recuperação baseados em PNL. 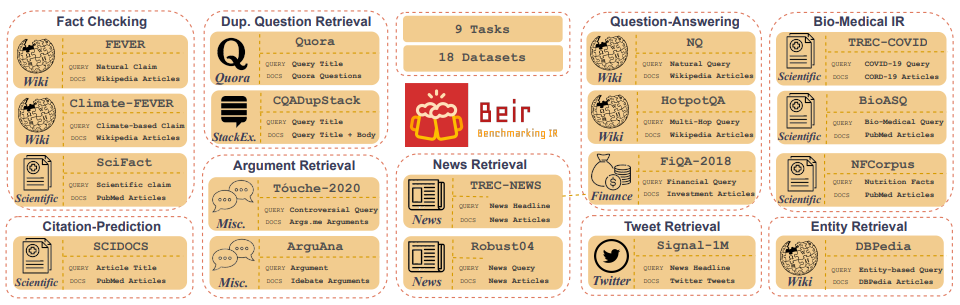
Figura 5: BEIR BENCHMARK DATASETS E TAREFAS IR ETAÇÃO RETIRADA DE [ORIGEM]
Zero or Few-Shot Annotations : em uma técnica conhecida como zero ou pouca tiro, os desenvolvedores podem fornecer consultas de exemplo específicas de domínio ao LLMS, aprimorando bastante a geração de consultas. Essa abordagem geralmente requer apenas um punhado de amostras anotadas.Longer Context Length : os modelos LLM baseados em GPT, como o LLAMA2, fornecem comprimentos de contexto estendidos, até 4.096 tokens em comparação com os 512 tokens de Bert. Esse contexto mais longo aprimora a análise de documentos e o controle de geração de consultas.O LLAMA2 será usado neste repositório para gerar consultas sintéticas, pois pode ser executado localmente nas GPUs de grau de consumo. Abaixo, é mostrado o modelo rápido do bate-papo llama2, que foi ajustado para aplicativos de diálogo e instrução.
<s>[INST] <<SYS>>
{your_system_message}
<</SYS>>
{user_message_1} [/INST]
<<SYS>> é uma das vantagens não-fiscais dos modelos de acesso aberto é que você tem controle total sobre o prompt do sistema nos aplicativos de bate-papo. Isso é essencial para especificar o comportamento do seu assistente de bate -papo - e até imbuir -o com alguma personalidade -, mas é inacessível nos modelos servidos atrás das APIs [fonte].Observe que os modelos Base LLAMA2 não possuem estrutura imediata porque são modelos brutos de não estrutura de instrução [fonte].
Recursos e referências adicionais para ajudar com técnicas e conceitos básicos:
Prompt Engineering e Consistency Filtering .Este repositório é que fará o possível para ser mantido. Se você enfrentar algum problema ou deseja fazer melhorias, aumente um problema ou envie uma solicitação de tração. ?


