LangChain SynData RAG Eval
1.0.0
该存储库展示了Langchain,Llama2-Chat和零和少数及时的及时工程,以实现信息检索(IR)和检索增强生成(RAG)评估的合成数据生成。
简介•亮点•示例笔记本•背景•指标•好处•提示模板•问题•todos
大型语言模型(LLM)通过理解复杂的查询来改变信息检索(IR)和搜索。该存储库展示了可用于生成IR和检索增强生成(RAG)评估的复杂合成数据集的概念和软件包。
生成的合成数据是给定上下文的查询和答案。合成生成的上下文Query-Asswer的一个示例如下:
Provided Context (usually split from documents / text sources):
Pure TalkUSA is an American mobile virtual network operator headquartered in Covington, Georgia, United States.
It is most notable for an industry-first offering of rollover data in their data add-on packages, which has since been discontinued.
Pure TalkUSA is a subsidiary of Telrite Corporation. Bring Your Own Phone!
Synthetically Generated Query:
What was the outstanding service offered by Pure TalkUSA?
Synthetically Generated Answer:
The outstanding service from Pure TalkUSA was its industry-first offering of rollover data.
构建IR或抹布系统时,上下文,查询和答案的数据集对于评估系统性能至关重要。人类宣布的数据集提供了出色的基础真理,但可以获得昂贵且具有挑战性。因此,使用LLMS生成的合成数据集是一种有吸引力的解决方案和补充。
通过采用LLM提示工程,可以生成各种综合查询和答案,以形成可靠的验证数据集。该存储库展示了一个生成合成数据的过程,同时强调零和少量弹出,以创建高度可自定义的合成数据集。图1概述了此存储库中所示的合成数据集生成过程。
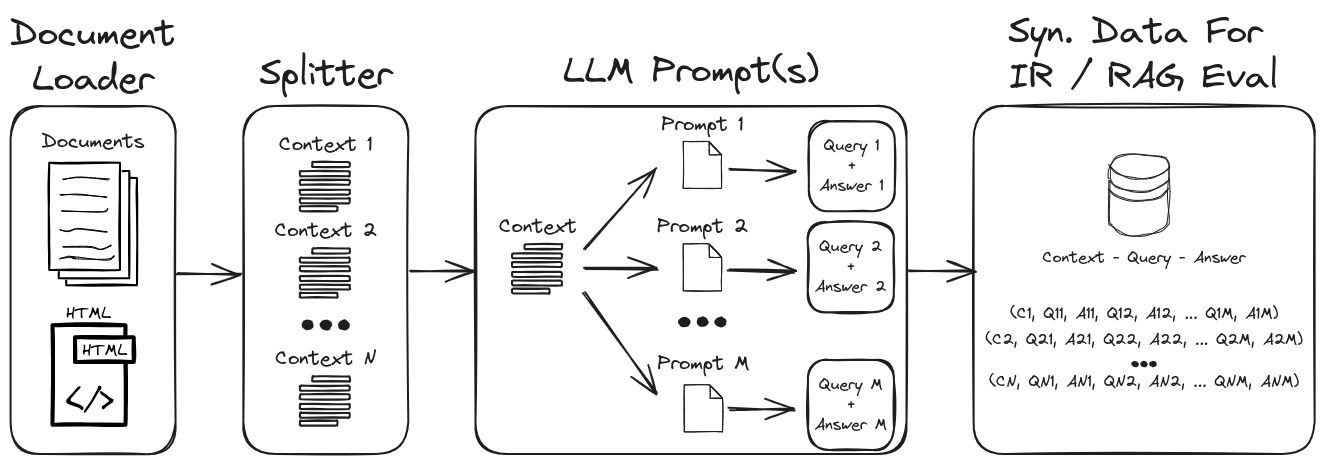
图1:IR和抹布评估的合成数据生成
注意:请参阅背景和指标部分,以更深入地了解IR,抹布以及如何评估这些系统。
存储库中的一些关键亮点是:
1.)带有自定义提示和输出解析器的Langchain,用于结构化数据输出:有关合成上下文 - 问题 - Query-Asswer数据生成的示例,请参见Gen-Question-Question-asswer-query.ipynb。该笔记本的关键方面是:
1.) Langchain自定义LLAMA2-CHAT提示:有关如何构建Langchain自定义提示模板的示例,请参见QA-Gen-Query-langchain.ipynb。本笔记本中显示的一些兰链功能是:
1.)零和少量弹药提示工程:有关自定义数据集的合成上下文查询数据生成的示例,请参见QA-gen-Query.ipynb。这里介绍的关键功能是:
zero- and few-shot annotations LLMS。2.)上下文保护:有关参数检索任务的综合上下文查询数据的示例,请参见参数 - Query.ipynb。在信息检索的背景下,这些任务旨在从文档等各种来源中检索相关参数。在参数检索中,目标是为用户提供有说服力和可信的信息,以支持他们的论点或做出明智的决定。
可以很容易地在网上找到查询特定生成模型的其他示例(例如, BeIR/query-gen-msmarco-t5-base-v1 )(请参阅Beir问题生成)。
IR系统的主要功能是检索,该功能旨在确定用户查询与要检索的内容之间的相关性。实施IR或破布系统需要特定于用户的文档。但是,缺乏自定义数据集的注释数据集篮板系统评估。图2概述了提问系统的典型抹布过程。
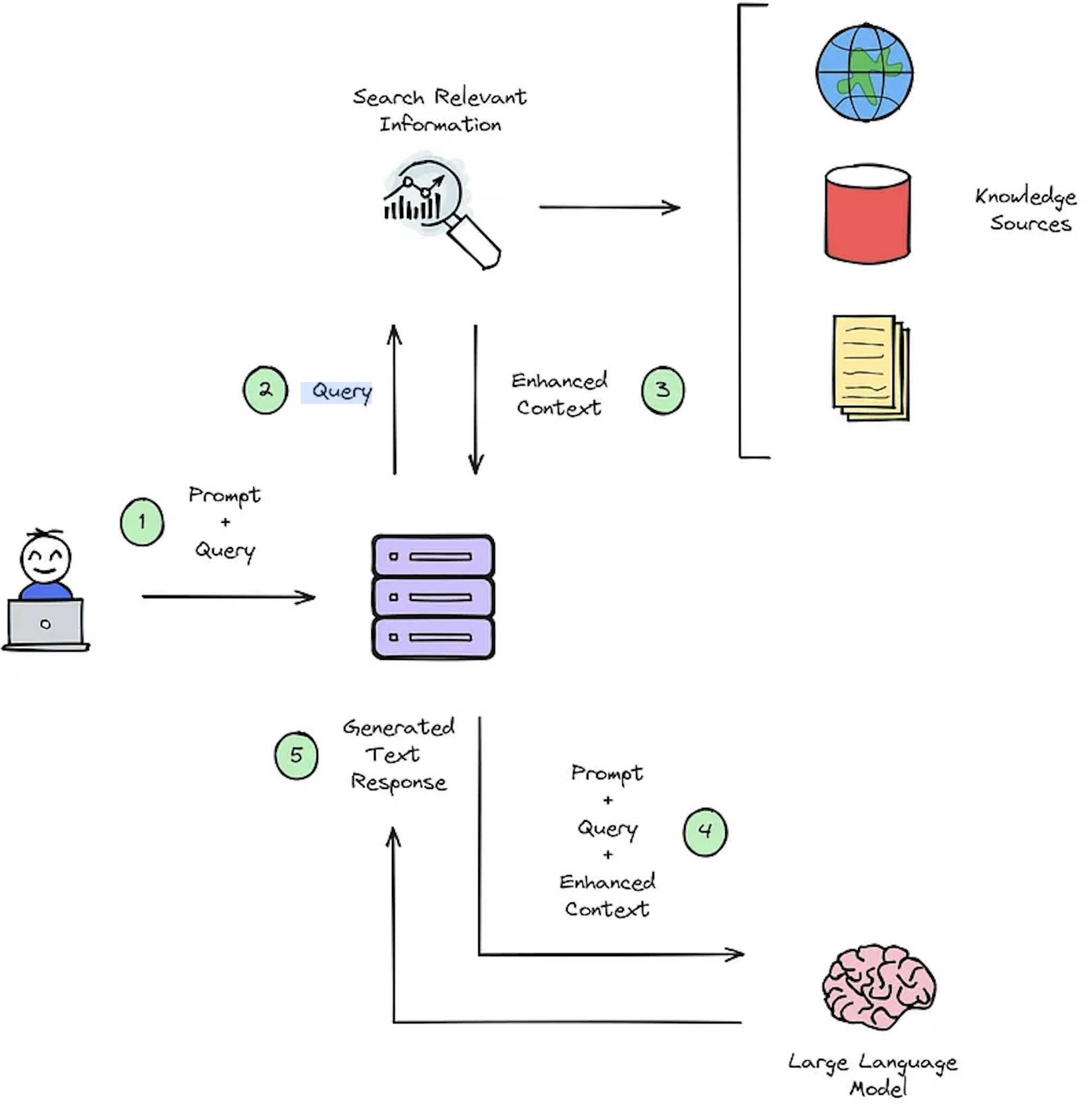
图2:抹布过程概述[源]。
此合成上下文广播数据集对于评估至关重要:1)IR的系统能够选择增强的上下文的能力,如图2-步骤#3和2)所示,如图2-步骤#5所示,抹布的生成响应。通过允许离线评估,它可以对系统之间的速度和准确性之间的平衡进行详尽的分析,告知必要的修订并选择冠军系统设计。
如图3所述,IR和抹布系统的设计变得越来越复杂。
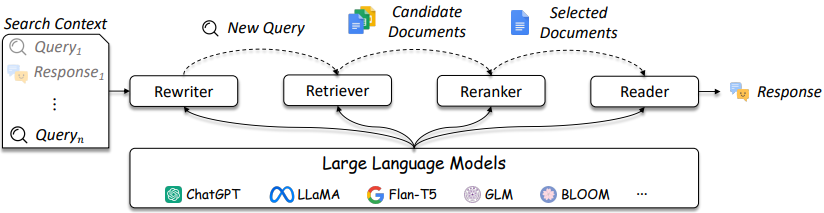
图3:LLM可以在查询重写器,猎犬,Reranker和Reader [source]中使用
如图所示,它们是IR /抹布设计中的几个考虑因素,解决方案的复杂性范围从传统方法(例如,基于项的稀疏方法)到基于神经的方法(例如,嵌入式和LLM)。对这些系统的评估对于做出完善的设计决策至关重要。从搜索到建议,评估措施对于了解在检索中有效和不起作用至关重要。
提问(QA)系统(例如,抹布系统)有两个组成部分:
在评估质量检查系统时,两个组件都需要分别评估并共同评估以获得整体系统得分。
每当向抹布应用程序提出问题时,都可以考虑以下对象[来源]:
指标的选择不是该存储库的主要重点,因为指标取决于应用程序。但是,为方便起见提供参考文章和信息。
图4显示了IR的常见评估指标,图1中的Dataset可用于图4所示的Offline Metrics 。
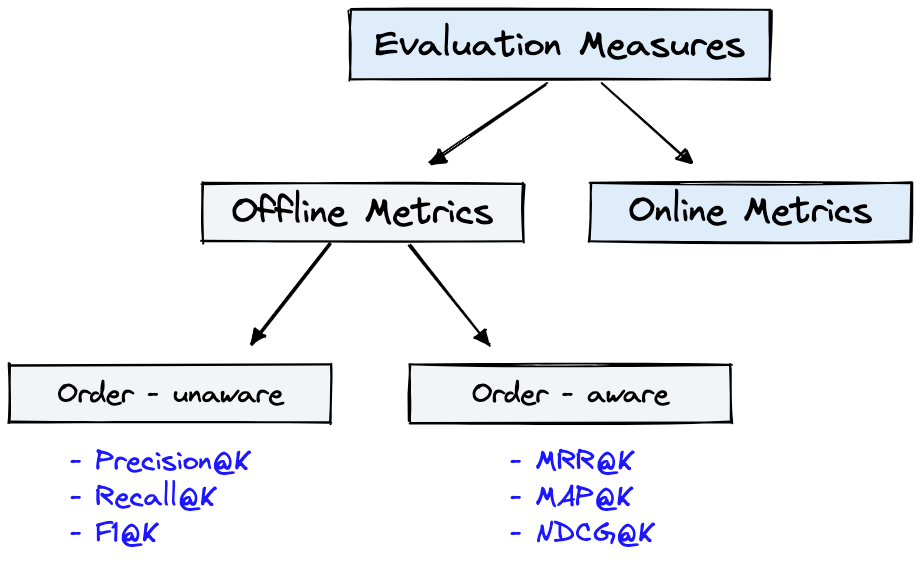
图4:排名评估指标[来源]
Offline metrics在部署新的IR系统之前在孤立的环境中进行测量。这些查看使用系统检索项目时是否返回一组特定的相关结果[源]。
对发电机指标的简要回顾将展示一些度量复杂性。评估发电机时,查看所选答案段落是否与正确的答案或答案相匹配。
下面提供的是最少列出的生成器指标。
请参阅文章《深刻:评估问题回答系统的指标》,并使用ragas + langsmith评估详细介绍这些指标的抹布管道。
LLM及时工程的合成数据生成的一些关键好处是:
Customized IR Task Query Generation :提示LLMS在可以生成的查询类型的类型中提供了极大的灵活性。这很有帮助,因为IR任务在其应用中有所不同。例如,基准测试-IR(BEIR)是一个异质基准,其中包含不同的IR任务,例如提问,论证或反论点检索,事实检查等。由于IR任务中的多样性,这是LLM提示的好处,因为可以在其中启用LLM提示的好处,因为该提示可以为您量身定制,以生成IR IR任务的合成数据。图5显示了Beir中不同IR任务和数据集的概述。请参阅Beir排行榜以查看基于NLP的检索模型的性能。 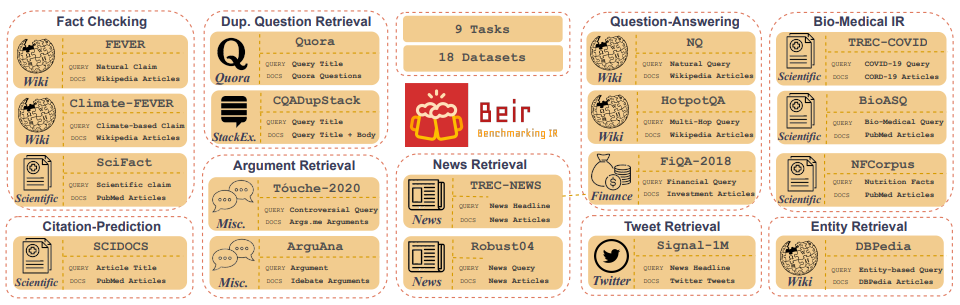
图5:从[源]获取的贝尔基准数据集和IR任务图像
Zero or Few-Shot Annotations :在称为零或几次提示的技术中,开发人员可以向LLMS提供特定于域的示例查询,从而大大增强查询生成。这种方法通常只需要少数带注释的样品。Longer Context Length :基于GPT的LLM模型(如Llama2)提供了扩展的上下文长度,与Bert的512代币相比,高达4,096个令牌。这种较长的上下文增强了文档解析和查询生成控制。Llama2将在此存储库中用于生成合成查询,因为它可以在消费级GPU上本地运行。下面显示的是Llama2聊天的及时模板,该模板是对话和指导应用程序的微调。
<s>[INST] <<SYS>>
{your_system_message}
<</SYS>>
{user_message_1} [/INST]
<<SYS>>是开放访问模型的无名优势之一,是您对聊天应用程序中的系统提示完全控制。这对于指定聊天助手的行为至关重要 - 甚至使它具有某些个性 - 但它在APIS后面使用的模型中是无法实现的[来源]。请注意,基本Llama2模型没有及时的结构,因为它们是原始的非教学调谐模型[源]。
其他资源和参考,以帮助提示技术和基础知识:
Prompt Engineering和Consistency Filtering的更多详细信息。该存储库将竭尽所能维护。如果您面临任何问题或想进行改进,请提出问题或提交拉动请求。 ?


