LangChain SynData RAG Eval
1.0.0
이 저장소는 Langchain, Llama2-Chat 및 Zero-ands-Shot 프롬프트 엔지니어링을 보여주고 정보 검색 (IR) 및 검색 증강 생성 (RAG) 평가를위한 합성 데이터 생성을 가능하게합니다.
소개 • 하이라이트 • 예제 노트북 • 배경 • 메트릭 • 혜택 • 프롬프트 템플릿 • 문제 • Todos
LLMS (Largin Language Models)는 복잡한 쿼리를 이해하여 정보 검색 (IR)을 변환하고 검색했습니다. 이 저장소는 IR 및 검색 증강 생성 (RAG) 평가를위한 정교한 합성 데이터 세트를 생성하는 데 사용할 수있는 개념과 패키지를 보여줍니다.
생성 된 합성 데이터는 주어진 컨텍스트에 대한 쿼리 및 답변입니다. 합성 적으로 생성 된 컨텍스트-쿼리 응답의 예는 다음과 같습니다.
Provided Context (usually split from documents / text sources):
Pure TalkUSA is an American mobile virtual network operator headquartered in Covington, Georgia, United States.
It is most notable for an industry-first offering of rollover data in their data add-on packages, which has since been discontinued.
Pure TalkUSA is a subsidiary of Telrite Corporation. Bring Your Own Phone!
Synthetically Generated Query:
What was the outstanding service offered by Pure TalkUSA?
Synthetically Generated Answer:
The outstanding service from Pure TalkUSA was its industry-first offering of rollover data.
IR 또는 RAG 시스템을 구축 할 때는 컨텍스트, 쿼리 및 답변의 데이터 세트가 시스템 성능을 평가하는 데 필수적입니다. 인간이 주석화 된 데이터 세트는 우수한 근거 진실을 제공하지만 비싸고 얻기가 어려울 수 있습니다. 따라서 LLM을 사용하여 생성 된 합성 데이터 세트는 매력적인 솔루션 및 보충제입니다.
LLM 프롬프트 엔지니어링을 사용함으로써 다양한 합성 쿼리 및 답변을 생성하여 강력한 검증 데이터 세트를 형성 할 수 있습니다. 이 저장소는 합성 데이터를 생성하는 프로세스를 보여 주면서 사용자 정의 가능한 합성 데이터 세트를 생성하기위한 제로 및 소수의 프롬프트를 강조합니다. 그림 1 은이 저장소에서 보여지는 합성 데이터 세트 생성 프로세스를 간략하게 설명합니다.
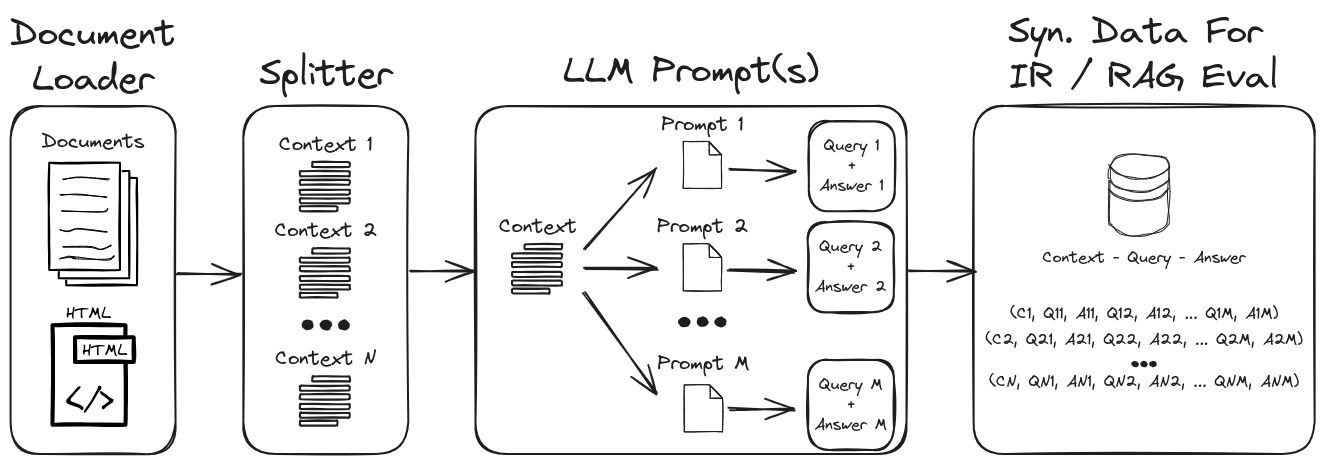
그림 1 : IR 및 RAG 평가를위한 합성 데이터 생성
참고 : IR, Rag 및 이러한 시스템을 평가하는 방법에 대한 배경 및 메트릭 섹션을 참조하십시오.
저장소의 주요 하이라이트 중 일부는 다음과 같습니다.
1.) 구조화 된 데이터 출력을위한 맞춤형 프롬프트 및 출력 파서가있는 Langchain : 합성 컨텍스트 -Query-ANSWER 데이터 생성의 예는 Gen-Question-Answer-Query.ipynb를 참조하십시오. 이 노트의 주요 측면은 다음과 같습니다.
1.) Langchain Custom Llama2-Chat 프롬프트 : 컨텍스트 쿼리 생성을위한 Langchain 사용자 정의 프롬프트 템플릿을 구축하는 방법에 대한 예는 QA-Gen-Query-Langchain.ipynb를 참조하십시오. 이 노트에 표시된 몇 가지 랑 체인 기능은 다음과 같습니다.
1.) 제로 및 소수의 프롬프트 엔지니어링 : 사용자 정의 데이터 세트에 대한 합성 컨텍스트-쿼리 데이터 생성의 예는 Qa-Gen-Query.ipynb를 참조하십시오. 여기에 제시된 주요 기능은 다음과 같습니다.
zero- and few-shot annotations 사용하여 LLM을 제기합니다.2.) 문맥 방향 : 인수 검색 작업에 대한 합성 컨텍스트 쿼리 데이터의 예는 Argument-Gen-Query.ipynb를 참조하십시오. 정보 검색의 맥락에서 이러한 작업은 문서와 같은 다양한 소스에서 관련 인수를 검색하도록 설계되었습니다. 논쟁을 검색 할 때 목표는 사용자에게 설득력 있고 신뢰할 수있는 정보를 제공하여 자신의 주장을 뒷받침하거나 정보에 입각 한 결정을 내리는 것입니다.
쿼리 특정 생성 모델 (예 : BeIR/query-gen-msmarco-t5-base-v1 )의 다른 예는 온라인에서 쉽게 찾을 수 있습니다 (BEIR 질문 생성 참조).
IR 시스템의 주요 기능은 검색이며, 이는 사용자의 쿼리와 검색 할 컨텐츠 간의 관련성을 결정하는 것을 목표로합니다. IR 또는 RAG 시스템을 구현하려면 사용자 별 문서가 필요합니다. 그러나 사용자 정의 데이터 세트 용 주석이없는 데이터 세트가 부족하여 시스템 평가를 방해합니다. 그림 2는 질문 응답 시스템에 대한 일반적인 헝겊 프로세스에 대한 개요를 제공합니다.
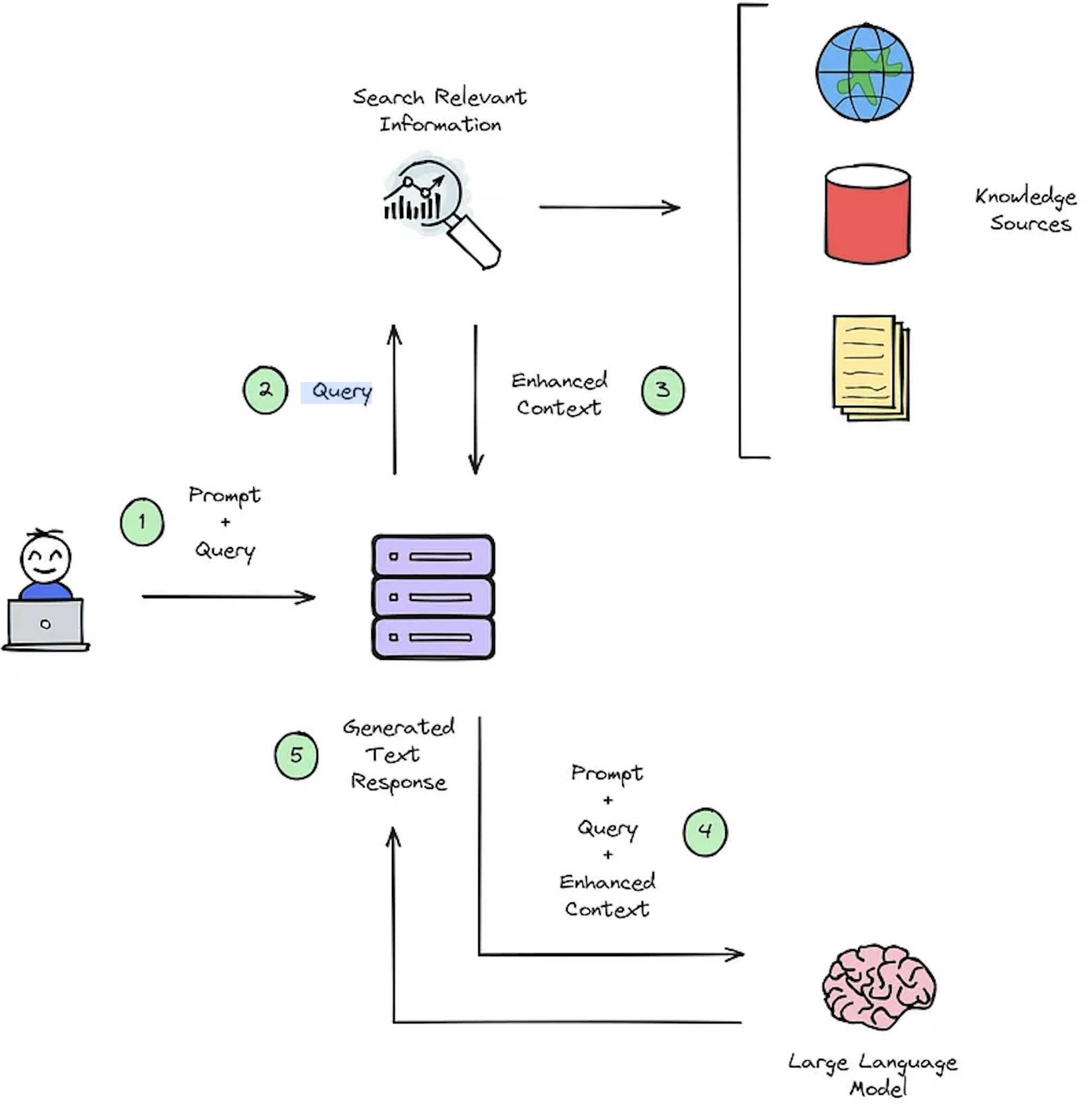
그림 2 : RAG 프로세스 개요 [출처].
이 합성 컨텍스트 - 쿼리 - 응답 데이터 세트는 다음을 평가하는 데 중요합니다. 1) 그림 2- 단계 #3 및 2)에 도시 된 바와 같이 향상된 컨텍스트를 선택하는 IR 시스템 기능은 그림 2- 단계 #5에 도시 된 바와 같이 RAG의 생성 된 응답. 오프라인 평가를 허용함으로써 속도와 정확도 사이의 시스템의 균형을 철저히 분석하여 필요한 개정을 알리고 챔피언 시스템 설계를 선택할 수 있습니다.
IR 및 래그 시스템의 설계는 그림 3에서 언급 된 바와 같이 더욱 복잡해지고 있습니다.
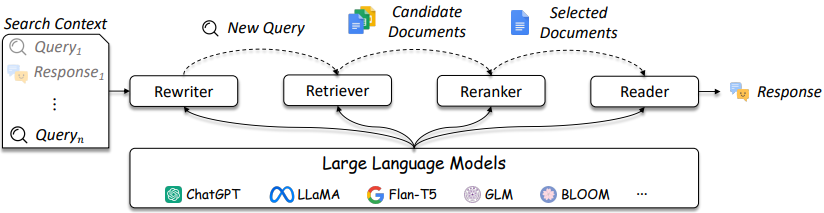
그림 3 : LLMS는 쿼리 리 작가, 리트리버, 재 ranker 및 reader에서 사용될 수 있습니다 [출처]
IR / 래그 설계에서 몇 가지 고려 사항이 있음과 솔루션은 전통적인 방법 (예 : 용어 기반 스파스 방법)에서 신경 기반 방법 (예 : 임베딩 및 LLM)에 이르기까지 복잡성이 다양 할 수 있습니다. 이러한 시스템의 평가는 정보가 잘 알려진 설계 결정을 내리는 데 중요합니다. 검색에서 권장 사항에 이르기까지 평가 조치는 검색에서 작동하지 않는 것이 무엇인지 이해하는 것보다 가장 중요합니다.
질문 응답 (QA) 시스템 (예 : Rag 시스템)에는 두 가지 구성 요소가 있습니다.
QA 시스템을 평가할 때는 전체 시스템 점수를 얻으려면 두 구성 요소를 별도로 및 함께 평가해야합니다.
헝겊 응용 프로그램에 대한 질문이있을 때마다 다음 객체를 고려할 수 있습니다 [출처].
메트릭 선택은 메트릭이 응용 프로그램 의존적이기 때문에이 저장소의 주요 초점이 아닙니다. 그러나 편의를 위해 참조 기사와 정보가 제공됩니다.
그림 4는 IR에 대한 일반적인 평가 메트릭과 그림 1의 Dataset 그림 4에 표시된 Offline Metrics 에 사용될 수 있습니다.
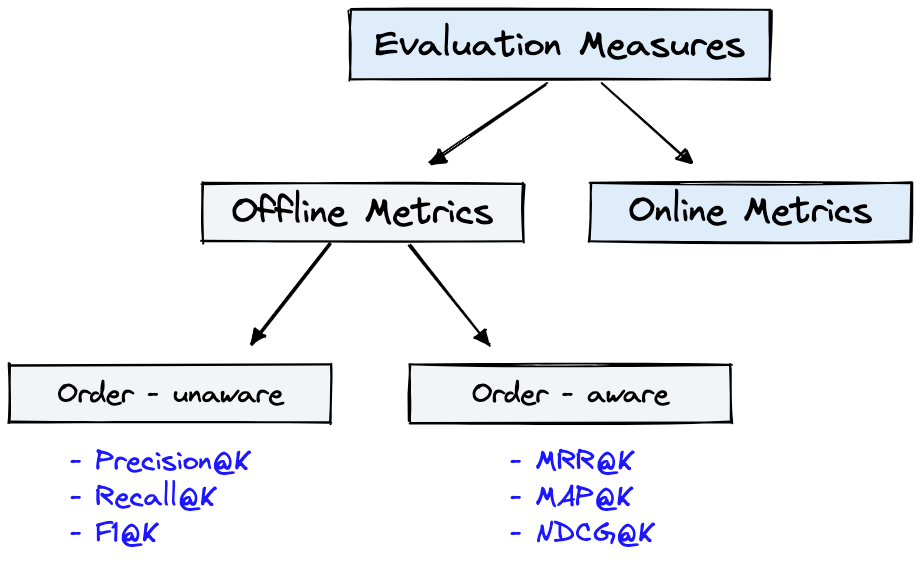
그림 4 : 순위 평가 측정 항목 [출처]
Offline metrics 새로운 IR 시스템을 배포하기 전에 격리 된 환경에서 측정됩니다. 이들은 시스템으로 항목을 검색 할 때 특정 관련 결과 세트가 반환되는지 여부를 살펴 봅니다 [출처].
Generator Metrics에 대한 간단한 검토는 메트릭 복잡성의 몇 계층을 보여줄 것입니다. 생성기를 평가할 때 선택된 답변 구절이 정답이나 답변과 일치하는지 또는 어느 정도까지보십시오.
아래는 가장 복잡한 순서대로 나열된 생성기 메트릭입니다.
Deepset : Metrics를 참조하십시오. 질문 응답 시스템을 평가하고 이러한 메트릭에 대해 자세히 설명하는 Ragas + Langsmith를 사용하여 Rag Pipelines를 평가하십시오.
LLM 프롬프트 엔지니어링을 사용한 합성 데이터 생성의 몇 가지 주요 이점은 다음과 같습니다.
Customized IR Task Query Generation : 프롬프트 LLM은 생성 할 수있는 쿼리 유형에 큰 유연성을 제공합니다. IR 작업은 응용 프로그램이 다르기 때문에 도움이됩니다. 예를 들어, 벤치마킹 -IR (BEIR)은 질문-응답, 인수 또는 카운터 인수 검색, 사실 점검 등과 같은 다양한 IR 작업을 포함하는 이기종 벤치 마크입니다. IR 작업의 다양성으로 인해 LLM 프롬프트의 이점이 IR 작업에 합성 데이터를 생성하는 데 맞는 프롬프트가 우수 할 수 있기 때문에 우수성이 우수합니다. 그림 5는 BEIR의 다양한 IR 작업 및 데이터 세트에 대한 개요를 보여줍니다. NLP 기반 검색 모델의 성능을 보려면 BEIR 리더 보드를 참조하십시오. 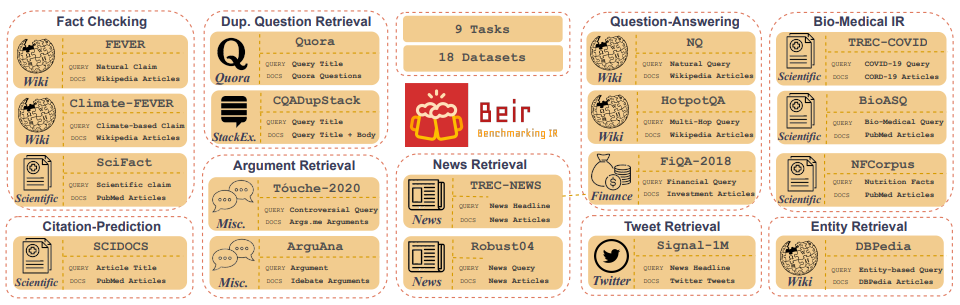
그림 5 : BEIR 벤치 마크 데이터 세트 및 IR 작업 이미지 [출처]
Zero or Few-Shot Annotations : 0 또는 소수의 샷 프롬프트라고하는 기술에서 개발자는 LLM에 도메인 별 예제 쿼리를 제공하여 쿼리 생성을 크게 향상시킬 수 있습니다. 이 접근법은 종종 소수의 주석이 달린 샘플 만 필요합니다.Longer Context Length : LLAMA2와 같은 GPT 기반 LLM 모델은 Bert의 512 토큰에 비해 최대 4,096 개의 토큰을 확장합니다. 이 긴 컨텍스트는 문서 구문 분석 및 쿼리 생성 제어를 향상시킵니다.LLAMA2는이 저장소에서 소비자 등급 GPU에서 로컬로 운영 될 수 있기 때문에 합성 쿼리를 생성하는 데 사용됩니다. 아래는 LLAMA2 채팅의 프롬프트 템플릿으로 대화 및 교육 응용 프로그램을 위해 미세 조정되었습니다.
<s>[INST] <<SYS>>
{your_system_message}
<</SYS>>
{user_message_1} [/INST]
<<SYS>> 는 개방형 액세스 모델의 불가사의 한 장점 중 하나입니다. 채팅 애플리케이션에서 시스템 프롬프트를 완전히 제어 할 수 있다는 것입니다. 이것은 채팅 어시스턴트의 동작을 지정하는 데 필수적이며 심지어 성격을 부여하는 것도 마찬가지입니다.기본 LLAMA2 모델은 원시 비 강조 조정 모델이기 때문에 신속한 구조가 없습니다 [출처].
프롬프트 기술 및 기본 사항에 도움이되는 추가 리소스 및 참조 :
Prompt Engineering 및 Consistency Filtering 에 대한 자세한 내용은 디렉토리 노트 참조를 참조하십시오.이 저장소는 유지하기 위해 최선을 다할 것입니다. 문제에 직면하거나 개선하려면 문제를 제기하거나 풀 요청을 제출하십시오. ?


