LangChain SynData RAG Eval
1.0.0
Dieses Repository demonstriert Langchain, LLAMA2-CHAT und Null- und wenige Eingabeaufforderungstechnik, um die synthetische Datenerzeugung für das Abrufen von Informationsabruf (IR) und die Bewertung der Augmented-Generation (Abruf Augmented Generation) zu ermöglichen.
Einführung • Highlights • Beispiel Notizbücher • Hintergrund • Metriken • Vorteile • Eingabeaufforderung Vorlagen • Probleme • TODOS
Großsprachige Modelle (LLMs) haben das Abrufen von Informationen (IR) und die Suche durch das Verständnis komplexer Abfragen transformiert. Dieses Repository zeigt Konzepte und Pakete, mit denen ausgefeilte synthetische Datensätze für die Bewertung der IR- und Abruf Augmented Generation (RAG) generiert werden können.
Die generierten synthetischen Daten sind eine Abfrage und Antwort für einen bestimmten Kontext. Ein Beispiel für ein synthetisch generiertes Kontext-Query-Antworten ist unten gezeigt:
Provided Context (usually split from documents / text sources):
Pure TalkUSA is an American mobile virtual network operator headquartered in Covington, Georgia, United States.
It is most notable for an industry-first offering of rollover data in their data add-on packages, which has since been discontinued.
Pure TalkUSA is a subsidiary of Telrite Corporation. Bring Your Own Phone!
Synthetically Generated Query:
What was the outstanding service offered by Pure TalkUSA?
Synthetically Generated Answer:
The outstanding service from Pure TalkUSA was its industry-first offering of rollover data.
Beim Erstellen eines IR- oder Lappensystems ist ein Datensatz mit Kontext, Abfragen und Antworten für die Bewertung der Systemleistung von entscheidender Bedeutung. Menschenanbieter-Datensätze bieten hervorragende Grundwahrheiten, können aber teuer und herausfordernd sein, um zu erhalten. Daher sind synthetische Datensätze, die mit LLMs erzeugt werden, eine attraktive Lösung und Ergänzung.
Durch die Verwendung von LLM -prompt -Engineering kann eine Vielzahl synthetischer Abfragen und Antworten generiert werden, um einen robusten Validierungsdatensatz zu bilden. Dieses Repository zeigt einen Prozess, um synthetische Daten zu generieren und gleichzeitig die Aufforderung zu null und wenigen Schüssen zum Erstellen von hochpassbaren synthetischen Datensätzen hervorzuheben. Abbildung 1 beschreibt den in diesem Repository demonstrierten synthetischen Datensatzgenerierungsprozess.
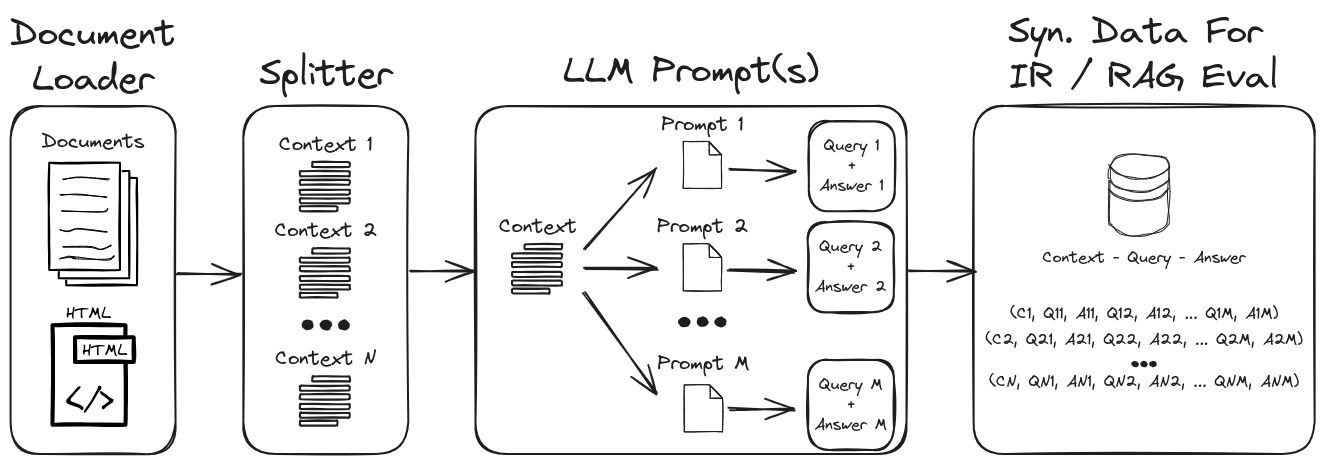
Abbildung 1: Synthetische Datenerzeugung für die IR- und Lag -Bewertung
HINWEIS : Weitere Informationen finden Sie in den Abschnitten Hintergrund- und Metriken für einen tieferen Tauchgang auf IR, Lag und wie diese Systeme bewertet werden.
Einige der wichtigsten Highlights im Repository sind:
1.) Langchain mit benutzerdefinierten Eingabeaufforderungen und Ausgangsparsers für die strukturierte Datenausgabe : Siehe Gen-Qustion-Antworten-Query.IPynb für ein Beispiel für synthetische Kontext-Query-Antworten-Datenerzeugung. Wichtige Aspekte dieses Notizbuchs sind:
1.) Langchain Custom LLAMA2-CHAT-Aufforderung : Siehe QA-General-Query-Langchain.ipynb für ein Beispiel für die Erstellung von Langchain-benutzerdefinierten Eingabeaufforderung für die Kontext-Queritätserzeugung. Einige der in diesem Notizbuch gezeigten Langchain -Funktionen sind:
1.) Null- und wenige Eingabeaufforderungsingenieurwesen : Siehe QA-General-Query.IPYNB für ein Beispiel für synthetische Kontextdatenerzeugung für benutzerdefinierte Datensätze. Die hier vorgestellten wichtigsten Funktionen sind:
zero- and few-shot annotations im Squadv2-Fragen-Answer-Datensatz.2.) Kontext-Arugment : Beispiele für synthetische Kontextdaten für Argumentenabrufaufgaben siehe Argument-General-Query.ipynb. Im Zusammenhang mit dem Abrufen von Informationen sollen diese Aufgaben relevante Argumente aus verschiedenen Quellen wie Dokumenten abrufen. Im Abrufen von Argumenten ist es das Ziel, den Benutzern überzeugende und glaubwürdige Informationen zu geben, um ihre Argumente zu unterstützen oder fundierte Entscheidungen zu treffen.
Weitere Beispiele für Abfrage-Modelle für Abfragenspezifische Generationen (z. B. BeIR/query-gen-msmarco-t5-base-v1 ) können online leicht gefunden werden (siehe Ber-Frage-Erzeugung).
Die Hauptfunktion eines IR -Systems ist das Abrufen, das die Relevanz zwischen der Abfrage einer Benutzer und dem abgerufenen Inhalt bestimmen soll. Durch die Implementierung eines IR- oder Lag-Systems sind benutzerspezifische Dokumente erforderlich. Fehlen nicht kommentierter Datensätze für benutzerdefinierte Datensätze beherrschen die Systembewertung. Abbildung 2 bietet einen Überblick über einen typischen Lag-Prozess für ein Fragen-Beantwortungssystem.
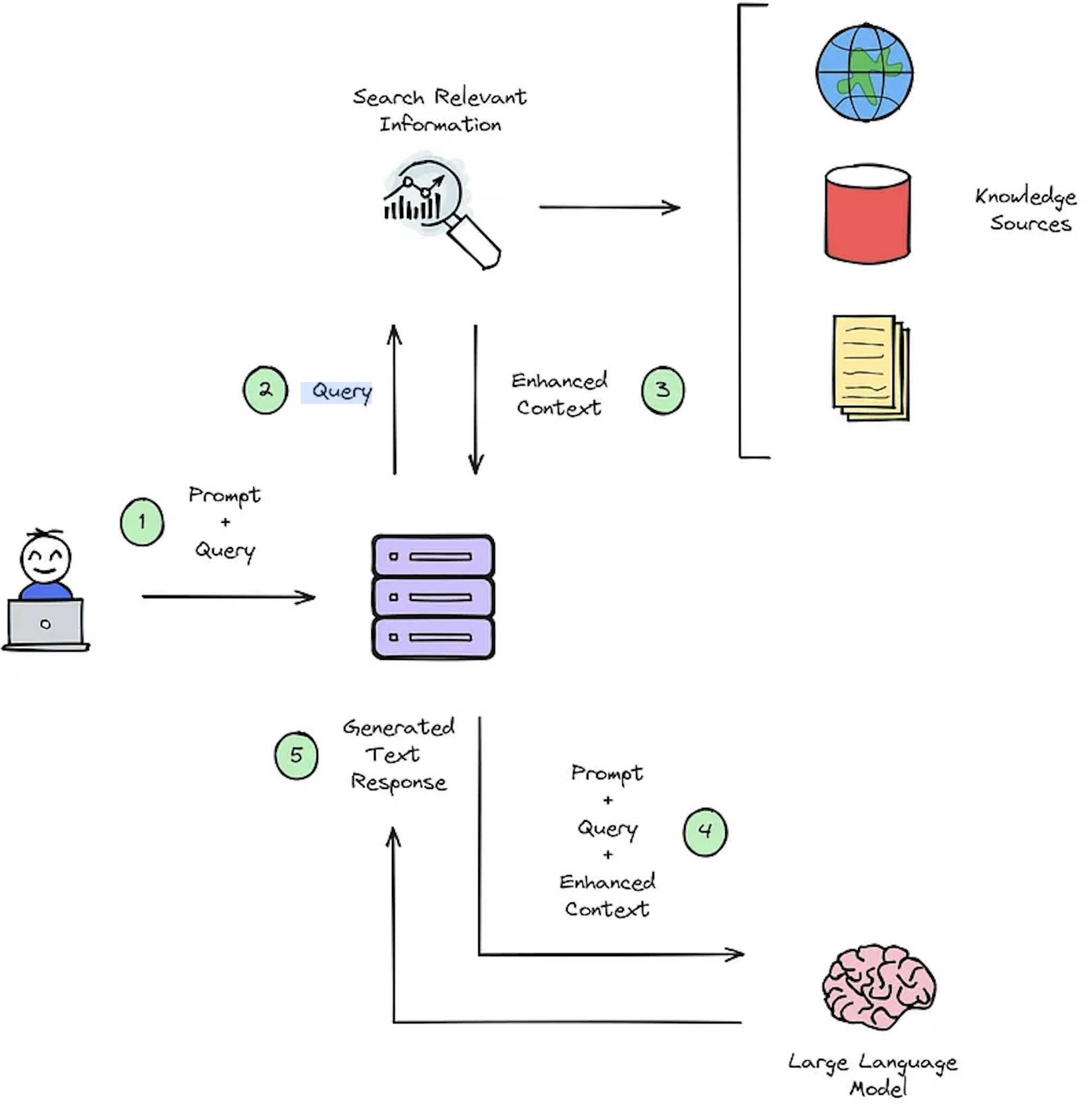
Abbildung 2: Überblick über Lag -Prozess [Quelle].
Diese synthetischen Kontext -Query -Antworten -Datensätze sind für die Bewertung von entscheidender Bedeutung: 1) Die Fähigkeit des IR -Systems, den erweiterten Kontext auszuwählen, wie in Abbildung 2 - Schritt 3 und 2) die erzeugte Antwort des Lags wie in Abbildung 2 - Schritt 5 gezeigt dargestellt. Durch die Ermöglichung der Offline -Bewertung ermöglicht es eine gründliche Analyse des Gleichgewichts des Systems zwischen Geschwindigkeit und Genauigkeit, der Information über die erforderlichen Überarbeitungen und die Auswahl von Champion -Systemdesigns.
Das Design von IR- und Lag -Systemen wird komplizierter, wie in Abbildung 3 angegeben.
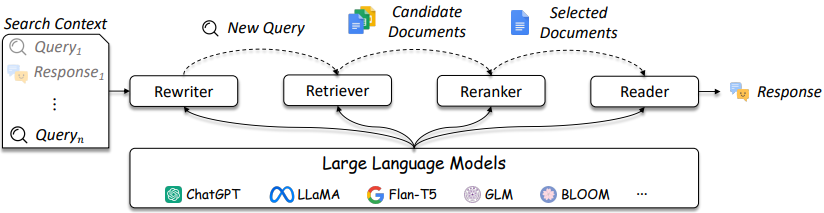
Abbildung 3: LLMs können im Abfrage -Rewriter, Retriever, Reranker und Leser [Quelle] verwendet werden.
Wie gezeigt, dass sie einige Überlegungen im IR / RAG-Design und -Lösungen sind, können sich die Komplexität von herkömmlichen Methoden (z. B. mit Term-basierte spärliche Methoden) bis hin zu neuronalen Methoden (z. B. Einbettungen und LLMs) befinden. Die Bewertung dieser Systeme ist entscheidend für gut informierte Designentscheidungen. Von der Suche bis zu Empfehlungen sind Bewertungsmaßnahmen von größter Bedeutung, um zu verstehen, was beim Abrufen funktioniert und was nicht.
Fragen-Answere (QA) -Systeme (z. B. RAG-System) haben zwei Komponenten:
Bei der Bewertung eines QA -Systems müssen beide Komponenten separat und zusammen bewertet werden, um einen Gesamtsystem Score zu erhalten.
Immer wenn eine Frage an eine Lag -Anwendung gestellt wird, können die folgenden Objekte in Betracht gezogen werden [Quelle]:
Die Auswahl der Metriken ist kein Hauptaugenmerk dieses Repositorys, da Metriken anwendungsabhängig sind. Referenzartikel und Informationen werden jedoch zur Bequemlichkeit bereitgestellt.
Abbildung 4 zeigt gemeinsame Bewertungsmetriken für IR und der Dataset aus Abbildung 1 kann für die in Abbildung 4 gezeigten Offline Metrics verwendet werden.
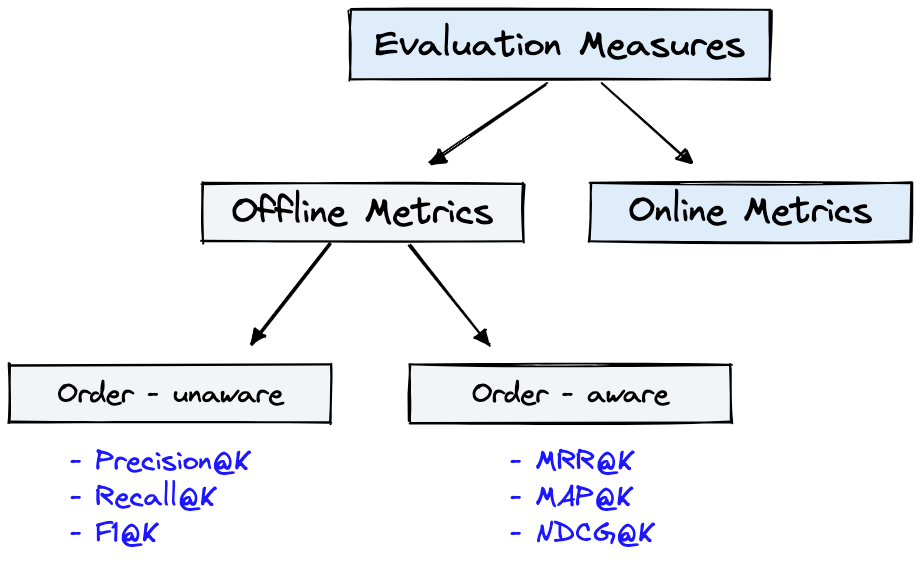
Abbildung 4: Ranking -Bewertungsmetriken [Quelle]
Offline metrics werden in einer isolierten Umgebung gemessen, bevor ein neues IR -System bereitgestellt wird. Diese sehen, ob ein bestimmter Satz relevanter Ergebnisse beim Abrufen von Elementen mit dem System [Quelle] zurückgegeben wird.
Eine kurze Übersicht über Generatormetriken zeigt einige Stufen der metrischen Komplexität. Betrachten Sie bei der Bewertung des Generators, ob oder in welchem Umfang die ausgewählten Antwortpassagen mit der richtigen Antwort oder den richtigen Antworten übereinstimmen.
Im Folgenden finden Sie Generatormetriken, die in der Reihenfolge von am wenigsten bis zum Komplexen aufgeführt sind.
Weitere Informationen zum Beantwortungssystem finden Sie im Artikel DeepSet: Metriken, um ein Fragenbeantwortungssystem zu bewerten und Rag -Pipelines mit Ragas + Langsmith zu bewerten, die diese Metriken näher erläutern.
Einige wichtige Vorteile der Erzeugung der synthetischen Daten mit LLM -prompt -Engineering sind:
Customized IR Task Query Generation : Aufforderung an LLMs bieten große Flexibilität in den Arten von Abfragen, die generiert werden können. Dies ist hilfreich, da IR -Aufgaben in ihrer Anwendung unterschiedlich sind. Zum Beispiel ist Benchmarking-IR (Beir) ein heterogener Benchmark, der verschiedene IR-Aufgaben wie Fragen, Argumente oder Gegenargumentationsabläufe, Faktenprüfung usw. enthält. Aufgrund der Vielfalt der IR-Aufgaben können die Vorteile der LLM-Aufforderung zur Erstellung von Synthetikdaten zu einer Ausgabe von LLM-Aufgaben zugeschnitten werden. Abbildung 5 zeigt einen Überblick über die verschiedenen IR -Aufgaben und Datensätze in Beir. In der Beir-Rangliste finden Sie die Leistung von NLP-basierten Abrufmodellen. 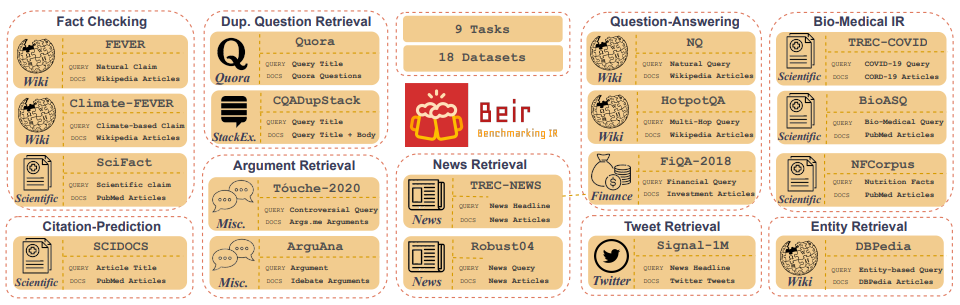
Abbildung 5: BEIR -Benchmark -Datensätze und IR -Aufgaben Bild aus [Quelle]
Zero or Few-Shot Annotations : In einer Technik, die als Null- oder wenige Schussanforderungen bezeichnet wird, können Entwickler domänenspezifische Beispielabfragen für LLMs liefern und die Abfragerzeugung erheblich verbessern. Dieser Ansatz erfordert oft nur eine Handvoll kommentierter Proben.Longer Context Length : GPT-basierte LLM-Modelle wie LLAMA2 bieten erweiterte Kontextlängen von bis zu 4.096 Token im Vergleich zu den 512-Token von Bert. Dieser längere Kontext verbessert die Dokument -Parsing- und Abfragerzeugungskontrolle.LLAMA2 wird in diesem Repository zum Generieren von synthetischen Abfragen verwendet, da es lokal auf GPUs der Verbrauchergrade ausgeführt werden kann. Im Folgenden ist die schnelle Vorlage für den Lama2-Chat gezeigt, der für Dialog- und Anweisungsanwendungen fein abgestimmt war.
<s>[INST] <<SYS>>
{your_system_message}
<</SYS>>
{user_message_1} [/INST]
<<SYS>> ist einer der unbesungenen Vorteile von Open-Access-Modellen besteht darin, dass Sie in Chat-Anwendungen die vollständige Steuerung über die Systemaufforderung haben. Dies ist wichtig, um das Verhalten Ihres Chat -Assistenten anzugeben - und es sogar mit einer Persönlichkeit zu verleihen - aber es ist in Modellen, die hinter APIS [Quelle] serviert werden, nicht erreichbar.Beachten Sie, dass Basis-LLAMA2-Modelle keine schnelle Struktur haben, da es sich um rAW-nicht eingestimmte Modelle [Quelle] handelt.
Zusätzliche Ressourcen und Verweise, um bei der Aufforderung zur Techniken und Grundlagen zu helfen:
Prompt Engineering und Consistency Filtering .Dieses Repository wird sein Bestes tun, um aufrechtzuerhalten. Wenn Sie sich mit Problemen befassen oder Verbesserungen vornehmen möchten, stellen Sie bitte ein Problem auf oder senden Sie eine Pull -Anfrage. ?


