LangChain SynData RAG Eval
1.0.0
このリポジトリは、情報検索(IR)および検索拡張生成(RAG)評価の合成データ生成を可能にするために、Langchain、Llama2-chat、およびゼロおよび少数のショットプロンプトエンジニアリングを示しています。
はじめに•ハイライト•ノートブックの例•背景•メトリック•利点•プロンプトテンプレート•問題•TODO
大規模な言語モデル(LLM)は、情報検索(IR)を変換し、複雑なクエリを理解して検索しました。このリポジトリには、IRおよび検索拡張生成(RAG)評価の洗練された合成データセットを生成するために使用できる概念とパッケージが表示されます。
生成された合成データは、特定のコンテキストのクエリと回答です。合成的に生成されたコンテキスト - クエリ回答の例を以下に示します。
Provided Context (usually split from documents / text sources):
Pure TalkUSA is an American mobile virtual network operator headquartered in Covington, Georgia, United States.
It is most notable for an industry-first offering of rollover data in their data add-on packages, which has since been discontinued.
Pure TalkUSA is a subsidiary of Telrite Corporation. Bring Your Own Phone!
Synthetically Generated Query:
What was the outstanding service offered by Pure TalkUSA?
Synthetically Generated Answer:
The outstanding service from Pure TalkUSA was its industry-first offering of rollover data.
IRまたはRAGシステムを構築する場合、システムのパフォーマンスを評価するには、コンテキスト、クエリ、および回答のデータセットが不可欠です。人間が解決したデータセットは、優れた地上の真理を提供しますが、手に入れるのが高価で挑戦的です。したがって、LLMSを使用して生成された合成データセットは、魅力的なソリューションとサプリメントです。
LLMプロンプトエンジニアリングを採用することにより、多様な合成クエリと回答を生成して、堅牢な検証データセットを形成できます。このリポジトリは、合成データを生成するプロセスを紹介し、高度にカスタマイズ可能な合成データセットを作成するためのゼロおよび数ショットのプロンプトを強調します。図1は、このリポジトリに示されている合成データセット生成プロセスの概要を示しています。
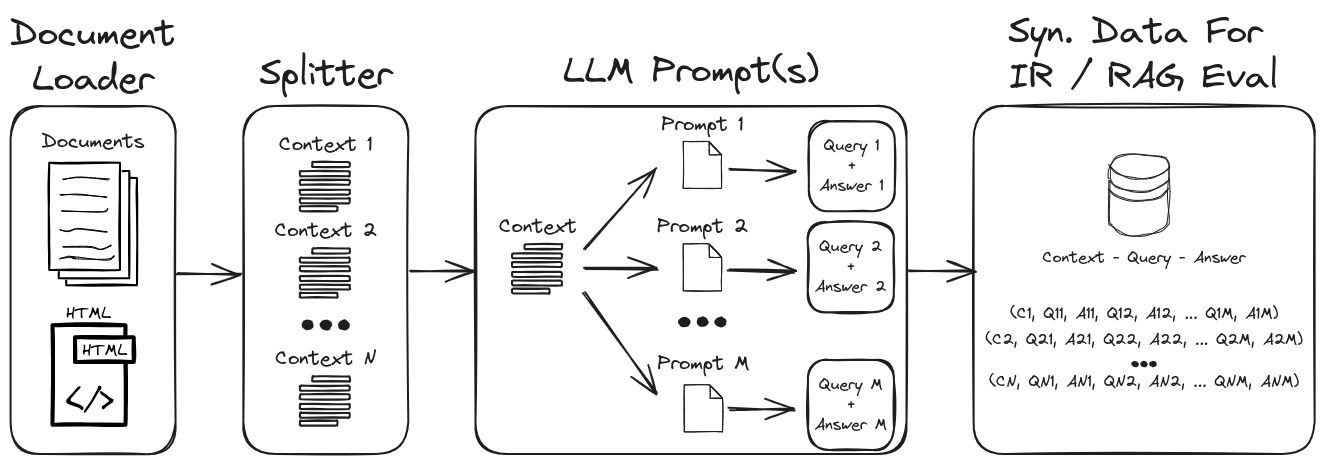
図1:IRおよびRAG評価のための合成データ生成
注:IR、RAG、およびこれらのシステムを評価する方法については、背景および指標セクションを参照してください。
リポジトリの重要なハイライトのいくつかは次のとおりです。
1.)構造化されたデータ出力用のカスタムプロンプトと出力パーサーを備えたLangchain :gen-question-answer-query.ipynbを参照してください。このノートブックの重要な側面は次のとおりです。
1.) langchainカスタムllama2-chatプロンプト:qa-gen-query-langchain.ipynbを参照してください。このノートブックに示されているLangchain機能のいくつかは次のとおりです。
1.)ゼロおよび少数のショットプロンプトエンジニアリング:カスタムデータセットの合成コンテキストクエリデータ生成の例については、QA-Gen-Query.ipynbを参照してください。ここに示されている重要な機能は次のとおりです。
zero- and few-shot annotationsを使用してLLMをプロンプトします。2.) Context-Arugment :引数検索タスクの合成コンテキストクエリデータの例については、Argument-Gen-Query.ipynbを参照してください。情報検索のコンテキストでは、これらのタスクは、ドキュメントなどのさまざまなソースから関連する引数を取得するように設計されています。引数の取得において、目標は、ユーザーに説得力のある信頼できる情報を提供して、議論をサポートするか、情報に基づいた決定を下すことです。
クエリ固有の生成モデル( BeIR/query-gen-msmarco-t5-base-v1など)の他の例は、オンラインで簡単に見つけることができます(Beir質問生成を参照)。
IRシステムの主な機能は検索であり、ユーザーのクエリと取得するコンテンツとの関連性を判断することを目的としています。 IRまたはRAGシステムを実装するには、ユーザー固有のドキュメントが必要です。ただし、カスタムデータセットの注釈付きデータセットがないため、システム評価が妨げられます。図2は、質問回答システムの典型的なRAGプロセスの概要を示しています。
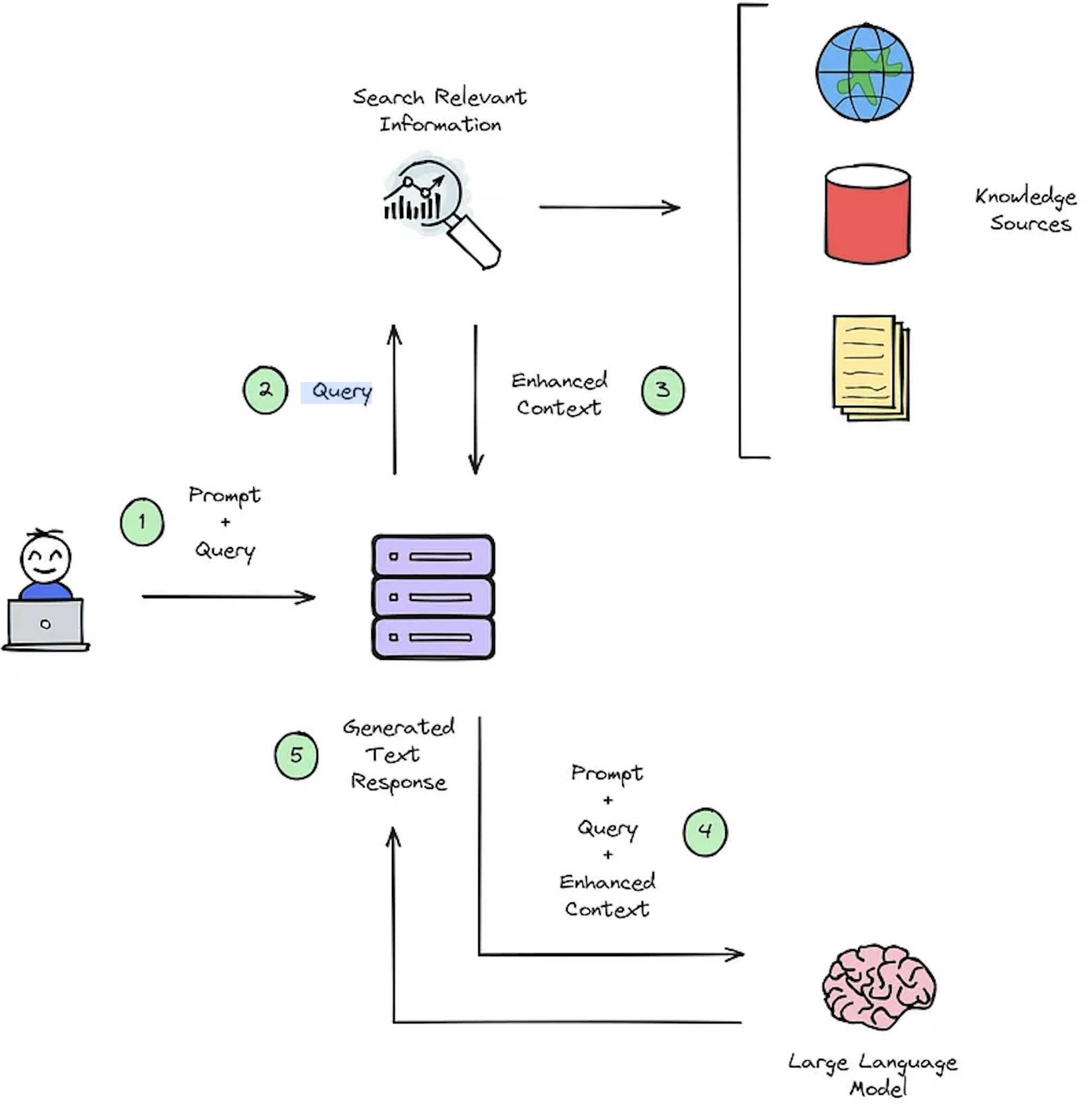
図2:RAGプロセスの概要[ソース]。
この合成コンテキスト - クエリ回答のデータセットは、次の評価に重要です。1)図2-ステップ#3に示すように強化されたコンテキストを選択するIRのシステム能力、および2)図2-ステップ#5に示すようにRAGの生成された応答。オフライン評価を可能にすることにより、速度と精度の間のシステムのバランスを徹底的に分析し、必要な改訂を通知し、チャンピオンシステムの設計を選択できます。
図3で参照されているように、IRおよびRAGシステムの設計はより複雑になっています。
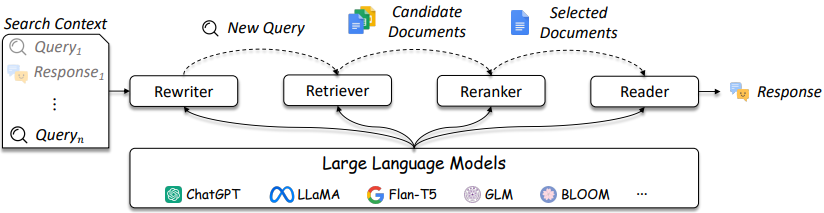
図3:LLMSは、クエリライター、レトリーバー、再審査員、およびリーダー[ソース]で使用できます。
示されているように、それらはIR / RAGの設計におけるいくつかの考慮事項であり、ソリューションは、従来の方法(たとえば、用語ベースのスパースメソッド)から神経ベースの方法(例、埋め込みやLLM)まで複雑になる可能性があります。これらのシステムの評価は、十分な情報に基づいた設計上の決定を下すために重要です。検索から推奨まで、評価措置は、検索で何が機能し、機能しないことを理解するために最も重要です。
質問回答(QA)システム(例えば、RAGシステム)には2つのコンポーネントがあります。
QAシステムを評価する場合、両方のコンポーネントを個別に、一緒に評価して、システム全体のスコアを取得する必要があります。
質問がRAGアプリケーションに求められるたびに、次のオブジェクトを考慮することができます[ソース]:
メトリックはアプリケーションに依存しているため、メトリックの選択はこのリポジトリの主要な焦点ではありません。ただし、参照記事と情報は便利で提供されます。
図4は、図1のIRの一般的な評価メトリックと図1のDataset Offline Metrics図4に示していることを示しています。
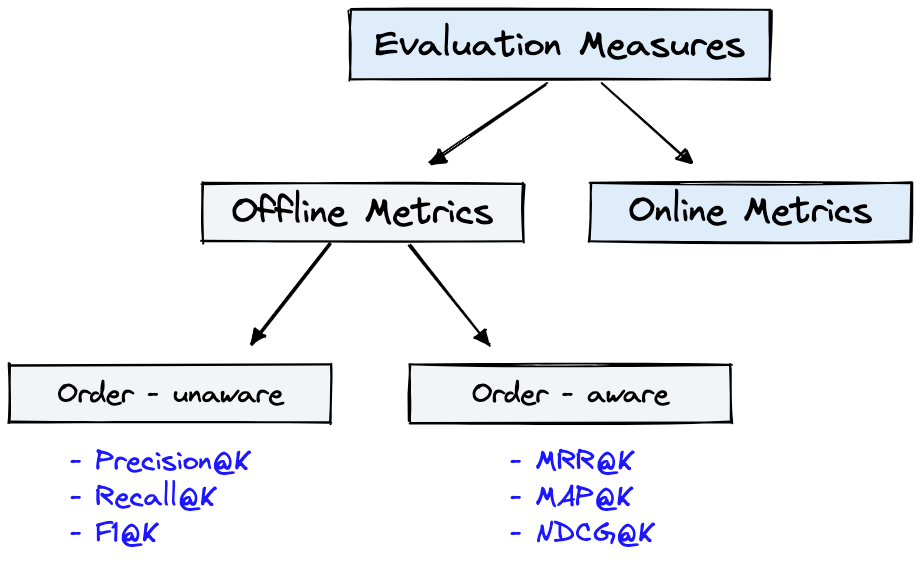
図4:ランキング評価メトリック[ソース]
Offline metricsは、新しいIRシステムを展開する前に、孤立した環境で測定されます。これらは、システム[ソース]を使用してアイテムを取得するときに、関連する結果の特定のセットが返されるかどうかを検討します。
ジェネレーターメトリックの簡単なレビューでは、メトリックの複雑さのいくつかの層を紹介します。ジェネレーターを評価するときは、選択した回答パッセージが正解または回答と一致するかどうか、またはどの程度まで見てください。
以下に提供されているのは、少なくとも最も複雑な順にリストされているジェネレーターメトリックです。
記事Deepset:Metricsを参照して、質問に答えるシステムを評価し、これらのメトリックについて詳しく説明するRagas + Langsmithを使用したRagパイプラインを評価してください。
LLMプロンプトエンジニアリングを使用した合成データ生成のいくつかの重要な利点は次のとおりです。
Customized IR Task Query Generation :プロンプトLLMは、生成できるクエリの種類に大きな柔軟性を提供します。 IRタスクはアプリケーションが異なるため、これは役立ちます。たとえば、ベンチマーク-IR(Beir)は、質問を回答、引数または反論の回収、事実チェックなどの多様なIRタスクを含む不均一なベンチマークです。これは、IRタスクの多様性により、LLMプロンプトの利点が卓越性が可能であるため、IRタスクに合成データを生成するためにプロンプトが合成データを生成するために卓越性があります。図5は、Beirの多様なIRタスクとデータセットの概要を示しています。 NLPベースの検索モデルのパフォーマンスを確認するには、Beir Leaderboardを参照してください。 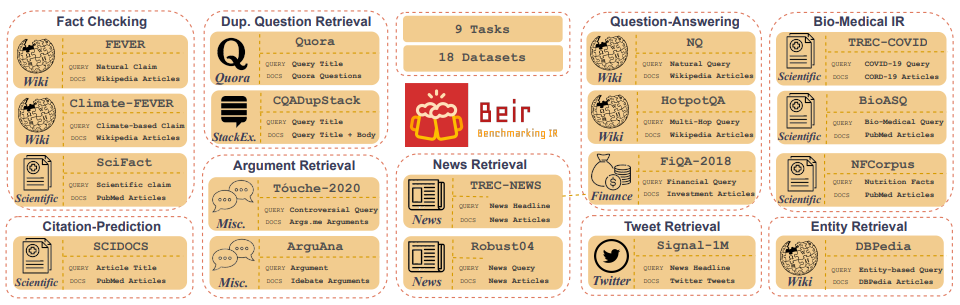
図5:[ソース]から取得したBeirベンチマークデータセットとIRタスク画像
Zero or Few-Shot Annotations :ゼロまたは少数のショットプロンプトと呼ばれる手法では、開発者はLLMSにドメイン固有の例クエリを提供し、クエリ生成を大幅に強化できます。このアプローチでは、多くの場合、一握りの注釈付きサンプルのみが必要です。Longer Context Length :LLAMA2のようなGPTベースのLLMモデルは、Bertの512トークンと比較して、最大4,096トークンまでの拡張コンテキスト長を提供します。この長いコンテキストは、ドキュメントの解析とクエリ生成制御を強化します。LLAMA2は、消費者グレードGPUでローカルに実行できるため、合成クエリを生成するためにこのリポジトリで使用されます。以下に示すのは、対話および指導アプリケーションのために微調整されたLlama2チャットのプロンプトテンプレートです。
<s>[INST] <<SYS>>
{your_system_message}
<</SYS>>
{user_message_1} [/INST]
<<SYS>>は、オープンアクセスモデルの有名な利点の1つは、チャットアプリケーションでシステムプロンプトを完全に制御できることです。これは、チャットアシスタントの動作を指定するために不可欠であり、性格を吹き込むことさえありますが、API [ソース]の背後にあるモデルでは到達できません。基本LLAMA2モデルには、生の非インストラクションチューニングモデル[ソース]であるため、迅速な構造はありません。
プロンプトのテクニックと基本を支援するための追加のリソースと参照:
Prompt EngineeringとConsistency Filteringの詳細については、ディレクトリノートリファレンスを参照してください。このリポジトリは、維持するために最善を尽くします。問題に直面している場合、または改善を行いたい場合は、問題を提起するか、プルリクエストを送信してください。 ?


