image_search
1.0.0
互聯網的出現徹底改變了我們通過Google,Bing和Yandex等有效搜索引擎訪問信息的方式。只有幾個關鍵字,我們可以迅速找到與我們的查詢有關的網頁。隨著技術,尤其是AI的進步,許多搜索引擎現在促進了在線圖像搜索。
出現了各種圖像搜索技術,包括:
在這個項目中,我們將使用預訓練的捲積神經網絡(CNN)從圖像中提取有價值的特徵。此方法是基於內容的圖像搜索的關鍵組成部分,它提供了以下好處:
總而言之,在這項研究中,我們想回答以下問題:相關嵌入的兩個類似圖像是否仍然相似?
對於這個項目,我們使用了CIFAR-10。它是一個免費可用的數據集,其中包括60,000個顏色圖像,每個圖像的尺寸為32x32像素。這些圖像屬於10個不同的類別:飛機,汽車,鳥,貓,鹿,狗,青蛙,馬,船和卡車。為了獲得其相應的嵌入,我們應用了預先訓練的CNN模型,特別是VGG-16 ,以提取基本特徵。結果矢量為512維。在Pinecone中,我們創建了一個名為“圖像”的索引,其尺寸為512,其中所有這些向量都將存儲。
該項目背後的想法是找到例如類似的鳥類圖像是否具有相似的嵌入。為此,我們已經在與Pinecone指數相關的60,000張圖像中上傳了50,000張。與已經存儲在Pinecone中的向量的圖像相比,該分區是為了確保我們擁有全新的圖像。另請注意,這種分析已經由CIFAR-10數據集完成到火車上,並代表代表原始圖像陣列的序列化版本的測試批次。
下面的PICUTRE描述了將嵌入到Pinecone索引的整個過程。從讀取圖像的第一步開始,應用預先訓練的VGG16神經網絡生成512個維嵌入,然後將其上述(即存儲)在Pinecone索引中。 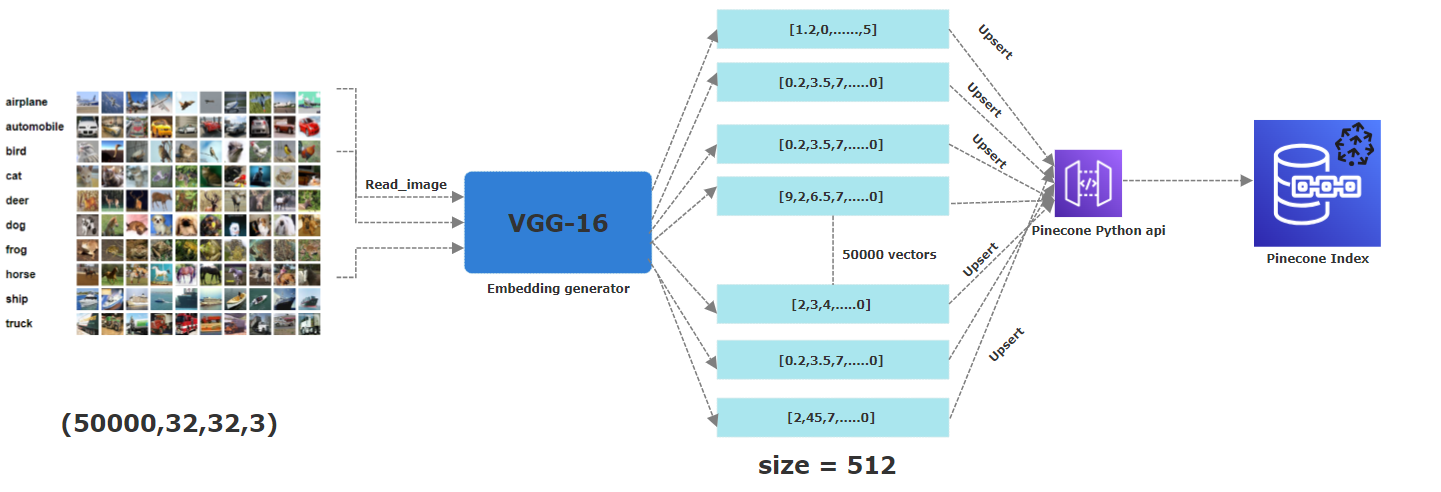
在這個項目中,我們正在處理5萬張圖像,這在兼容方面構成了一些挑戰,尤其是在閱讀圖像時(我們已經將CIFAR-10數據集序列化版本)刪除並通過CNN提取功能。我們試圖在運行代碼時利用帕拉利計算的功能,以便通過多線程在多個CPU內核上盡可能快地運行。
注意:如果可能的話,請在GPU驅動的環境上運行此項目,以進行更快的計算。
在此處免費創建Pinecone帳戶。
獲取與Pinecone帳戶相關的API密鑰和環境
克隆此存儲庫(有關幫助,請參閱本教程)。
在項目文件夾中創建虛擬環境(有關幫助請參見本教程)。
運行以下命令安裝必要的軟件包。
pip3 install -r requirements.txt
pip install -r requirements.txt
python insert_data.py -key <API_KEY> -env <ENV> -metric <METRIC>
將<env>和<API_KEY>替換為您從Pinecone帳戶中獲得的值。等待腳本完成。 7。使用以下內容啟動該應用程序。
streamlit run app.py -- -key <API_KEY> -env <ENV>
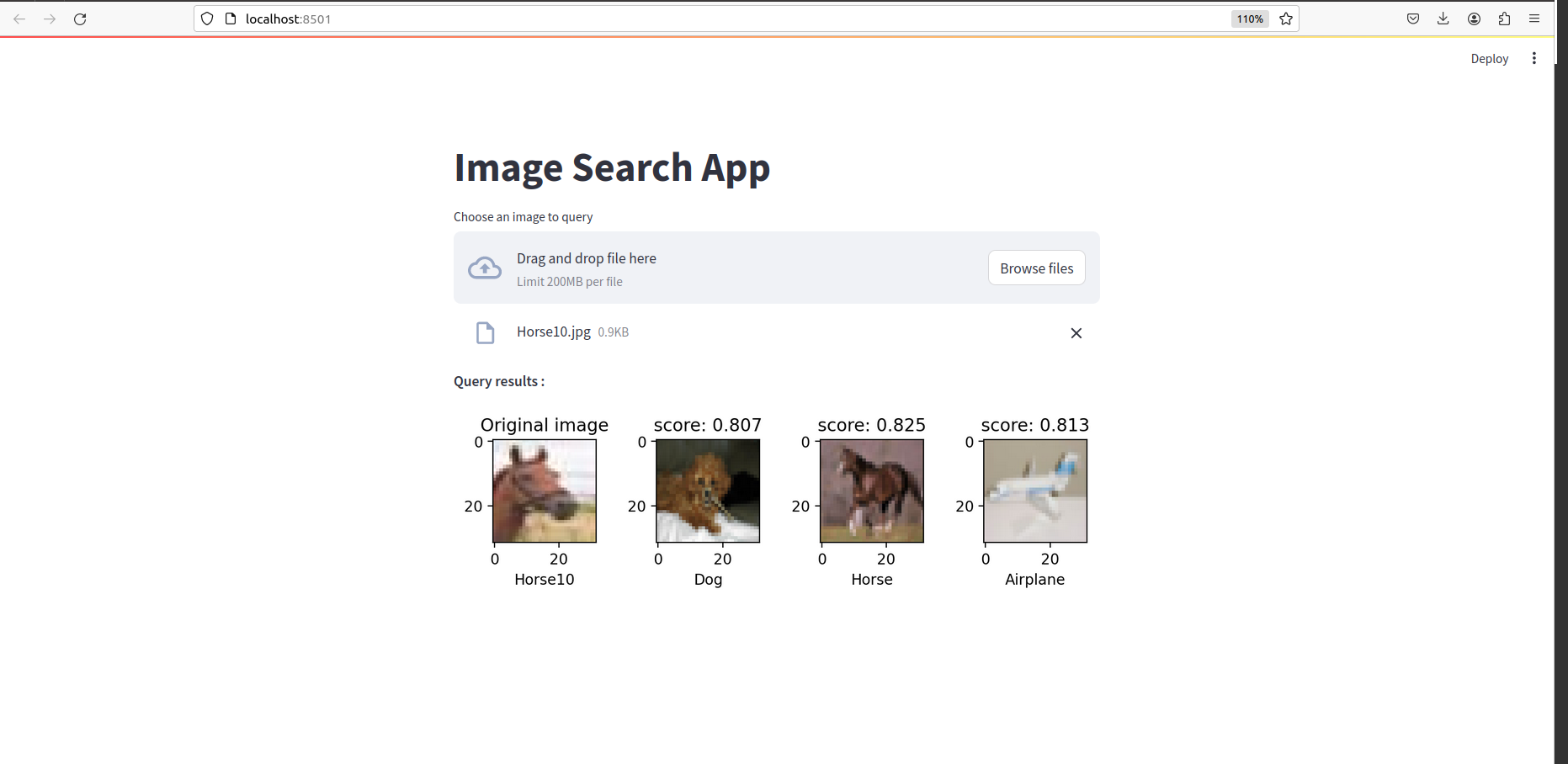
一旦完成了一切,您就應該看到這樣的東西: