image_search
1.0.0
أحدث ظهور الإنترنت ثورة في طريقة الوصول إلى المعلومات من خلال محركات البحث القوية مثل Google و Bing و Yandex. مع بعض الكلمات الرئيسية ، يمكننا تحديد موقع صفحات الويب بسرعة ذات الصلة باستعلاماتنا. نظرًا لأن التكنولوجيا ، وخاصة الذكاء الاصطناعي ، تتقدم ، فإن العديد من محركات البحث تسهل الآن عمليات البحث عن الصور عبر الإنترنت.
ظهرت تقنيات مختلفة للبحث عن الصور ، بما في ذلك:
في هذا المشروع ، سوف نستخدم شبكة عصبية تلافيفية تدرب مسبقًا (CNN) لاستخراج ميزات قيمة من الصور. توفر هذه المنهجية ، وهي مكون رئيسي للبحث عن الصور المستند إلى المحتوى ، الفوائد التالية:
باختصار ، في هذه الدراسة ، نرغب في الإجابة على السؤال التالي: هل لا تزال صورتان متشابهتان مرتبطتان التضمين متشابهين؟
لهذا المشروع ، استخدمنا CIFAR-10. إنها مجموعة بيانات متوفرة مجانًا تضم 60،000 صورة ملونة ، تبلغ مساحتها 32 × 32 بكسل . تنتمي هذه الصور إلى 10 فئات مميزة: الطائرة ، السيارات ، الطيور ، القط ، الغزلان ، الكلب ، الضفدع ، الحصان ، السفينة ، والشاحنة. للحصول على تضميناتها المقابلة ، طبقنا نموذج CNN الذي تم تدريبه مسبقًا ، وتحديداً VGG-16 ، لاستخراج الميزات الأساسية. المتجه الناتج هو 512 الأبعاد . داخل Pinecone ، أنشأنا فهرسًا يسمى "صور" بأبعاد قدره 512 ، حيث سيتم تخزين جميع هذه المتجهات.
تتمثل الفكرة وراء هذا المشروع في العثور على ما إذا كانت الصور المماثلة للطيور على سبيل المثال لها تضمينات مماثلة. للقيام بذلك ، قمنا بتحميل 50000 من إجمالي 60،000 صورة مرتبطة بالتضمين إلى مؤشر Pinecone. تم تقديم هذا القسم لضمان أن لدينا صورًا جديدة ومميزة تمامًا مقارنةً بتلك المخزنة بالفعل كمتجهات في Pinecone. لاحظ أيضًا أن هذا الطيران يتم بالفعل بواسطة مجموعة بيانات CIFAR-10 في مجموعات القطار والاختبار التي تمثل الإصدارات التسلسلية من صفائف الصور الأصلية.
تصف picutre أدناه العملية بأكملها لتخزين التضمينات إلى مؤشر pinecone. من الخطوة الأولى لقراءة الصور ، بتطبيق شبكة عصبية VGG16 المدربة مسبقًا لإنشاء 512 أبعادًا تم تمييزًا بعد ذلك (أي تخزين) في فهرس Pinecone. 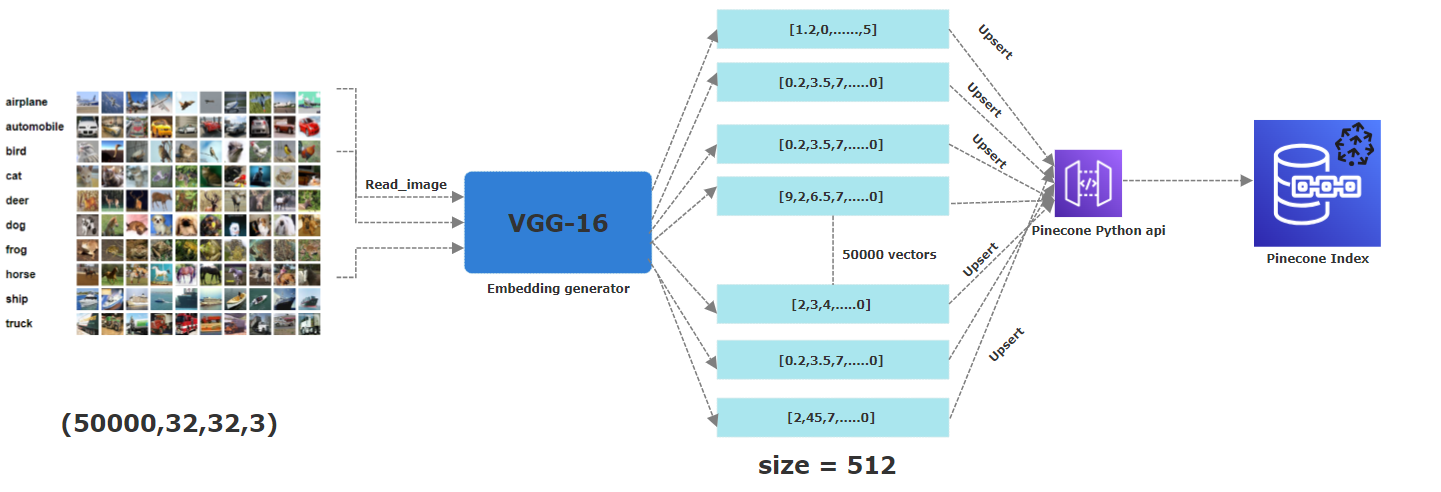
في هذا المشروع ، نتعامل مع 50 ألف صورة ، والتي تشكل بعض التحديات من حيث التجميع وخاصة عند قراءة الصور ، إلغاء تحديدها (قمنا بتنظيف الإصدار المسلسل CIFAR-10 Dataset) لها وميزات الاستخراج عبر CNN. حاولنا الاستفادة من قوة الحوسبة المتوازية عند تشغيل الكود لدينا بحيث يتم تشغيل كل شيء بأسرع وقت ممكن على نوى وحدة المعالجة المركزية المتعددة عبر MultiTReading.
ملاحظة: إن أمكن ، قم بتشغيل هذا المشروع على بيئة مدعوم من GPU بإجراء حسابات أسرع.
إنشاء حساب pinecone مجانا هنا.
احصل على مفتاح API والبيئة المرتبطة بحساب Pinecone الخاص بك
استنساخ هذا الريبو (للمساعدة في رؤية هذا البرنامج التعليمي).
قم بإنشاء بيئة افتراضية في مجلد المشروع (للمساعدة في رؤية هذا البرنامج التعليمي).
قم بتشغيل الأمر التالي لتثبيت الحزم اللازمة.
pip3 install -r requirements.txt
pip install -r requirements.txt
python insert_data.py -key <API_KEY> -env <ENV> -metric <METRIC>
استبدل <ece> و <api_key> بالقيم التي تحصل عليها من حساب pinecone الخاص بك. انتظر حتى يتم البرنامج النصي. 7. قم بتشغيل التطبيق باستخدام ما يلي.
streamlit run app.py -- -key <API_KEY> -env <ENV>
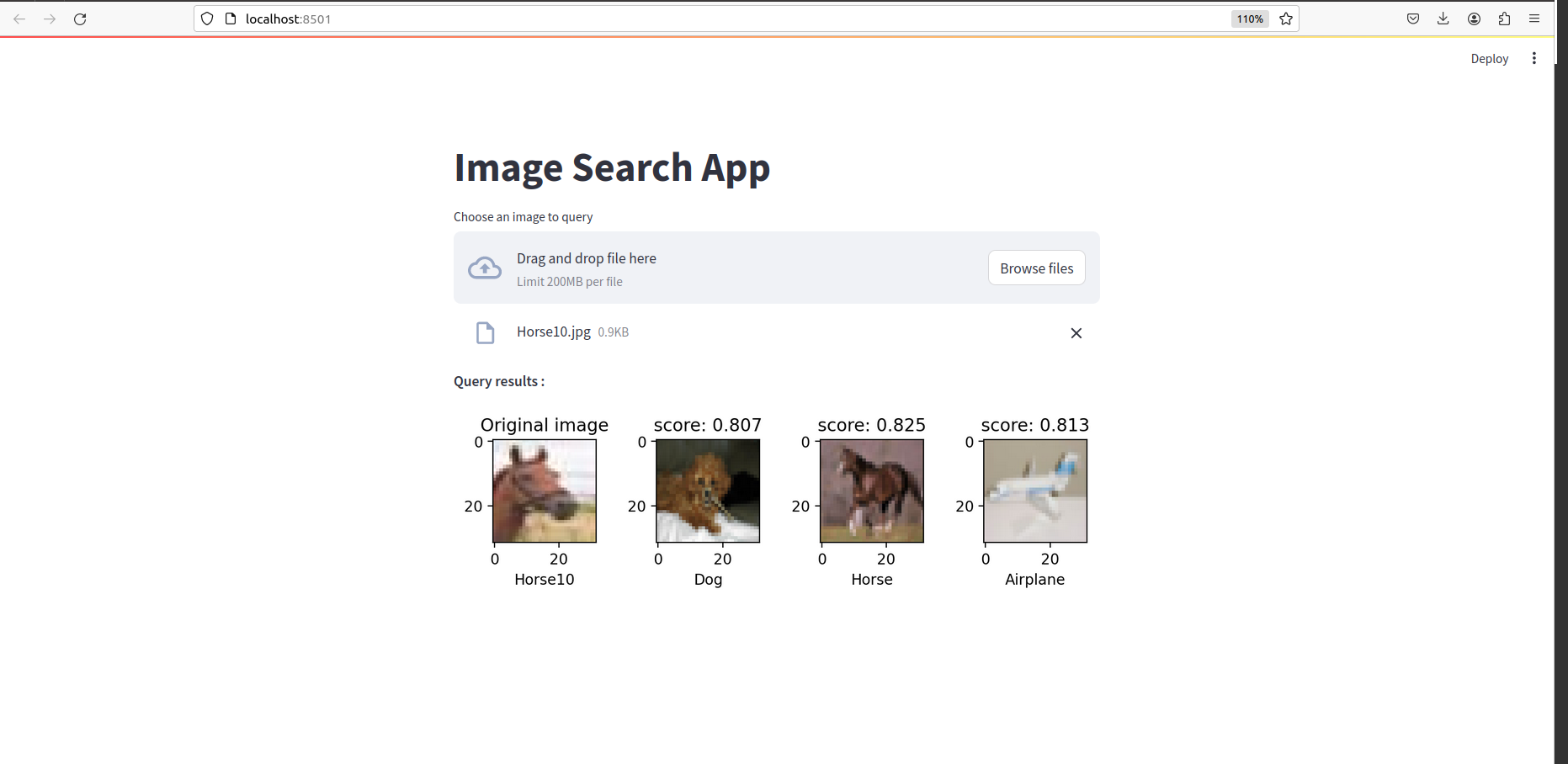
بمجرد الانتهاء من كل شيء ، يجب أن ترى شيئًا كهذا: