image_search
1.0.0
インターネットの出現により、Google、Bing、Yandexなどの強力な検索エンジンを介して情報にアクセスする方法に革命をもたらしました。わずか数個のキーワードを使用すると、クエリに関連するWebページを迅速に見つけることができます。テクノロジー、特にAIが進歩するにつれて、多くの検索エンジンがオンライン画像検索を促進するようになりました。
画像検索のさまざまな手法が登場しました。
このプロジェクトでは、事前に訓練された畳み込みニューラルネットワーク(CNN)を使用して、画像から貴重な機能を抽出します。コンテンツベースの画像検索の重要なコンポーネントであるこの方法論は、次の利点を提供します。
要約すると、この研究では、次の質問に答えたいと思います。2つの類似した画像に関連する埋め込みはまだ類似していますか?
このプロジェクトでは、CIFAR-10を使用しました。 60,000個のカラー画像で構成される自由に利用可能なデータセットで、それぞれが32x32ピクセルを測定します。これらの画像は、飛行機、自動車、鳥、猫、鹿、犬、カエル、馬、船、トラックの10の異なるカテゴリに属します。対応する埋め込みを取得するために、事前に訓練されたCNNモデル、特にVGG-16を適用して、重要な機能を抽出しました。結果のベクトルは512次元です。 Pinecone内で、512の寸法を持つ「画像」という名前のインデックスを作成しました。これらのベクトルはすべて保存されます。
このプロジェクトの背後にあるアイデアは、たとえば鳥の類似の画像が同様の埋め込みを持っているかどうかを見つけることです。そのために、埋め込みに関連する合計60,000の画像のうち50,000をPineconeインデックスにアップロードしました。このパーティションは、Pineconeのベクトルとしてすでに保存されている画像と比較して、まったく新しい明確な画像を確保するために作成されました。また、この件は、CIFAR-10データセットによって、元の画像配列のシリアル化されたバージョンを表すテストバッチとテストバッチに既に行われていることに注意してください。
以下のピクトレは、埋め込みを松ぼっくりインデックスに保存するプロセス全体を説明しています。画像を読み取る最初のステップから、事前に訓練されたVGG16ニューラルネットワークを適用して、512の寸法埋め込みを生成し、その後、PineconeインデックスでUpSered(つまり保存されています)。 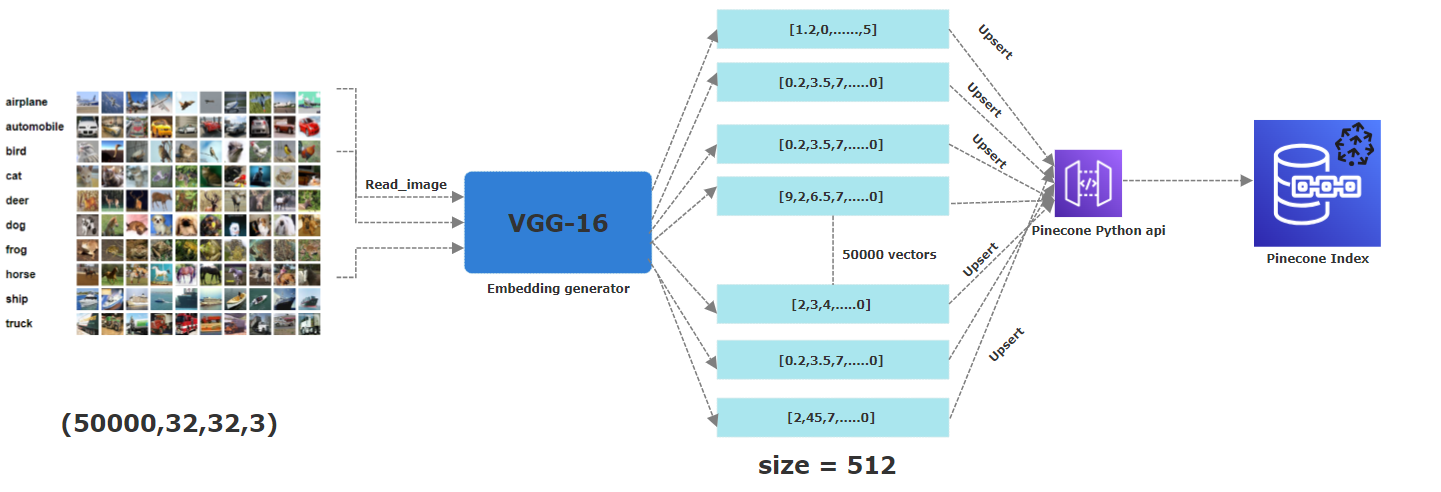
このプロジェクトでは、特に画像を読み取るときに複雑な点でいくつかの課題をもたらす5万枚の画像を処理しています(CIFAR-10データセットシリアル化バージョンをダウンロードしました)。マルチスレッドを介して複数のCPUコアですべてができるだけ速く実行されるように、コードを実行するときに、Parralled Computingのパワーを活用しようとしました。
注:可能であれば、このプロジェクトをGPU駆動環境で実行して、より高速な計算を行います。
ここでは、Pineconeアカウントを無料で無料で作成します。
Pineconeアカウントに関連付けられているAPIキーと環境を取得します
このリポジトリをクローンします(このチュートリアルを参照してください)。
プロジェクトフォルダーに仮想環境を作成します(このチュートリアルを参照してください)。
次のコマンドを実行して、必要なパッケージをインストールします。
pip3 install -r requirements.txt
pip install -r requirements.txt
python insert_data.py -key <API_KEY> -env <ENV> -metric <METRIC>
<Env>および<API_KEY>をPineconeアカウントから取得した値に置き換えます。スクリプトが完了するのを待ちます。 7.以下を使用してアプリを起動します。
streamlit run app.py -- -key <API_KEY> -env <ENV>
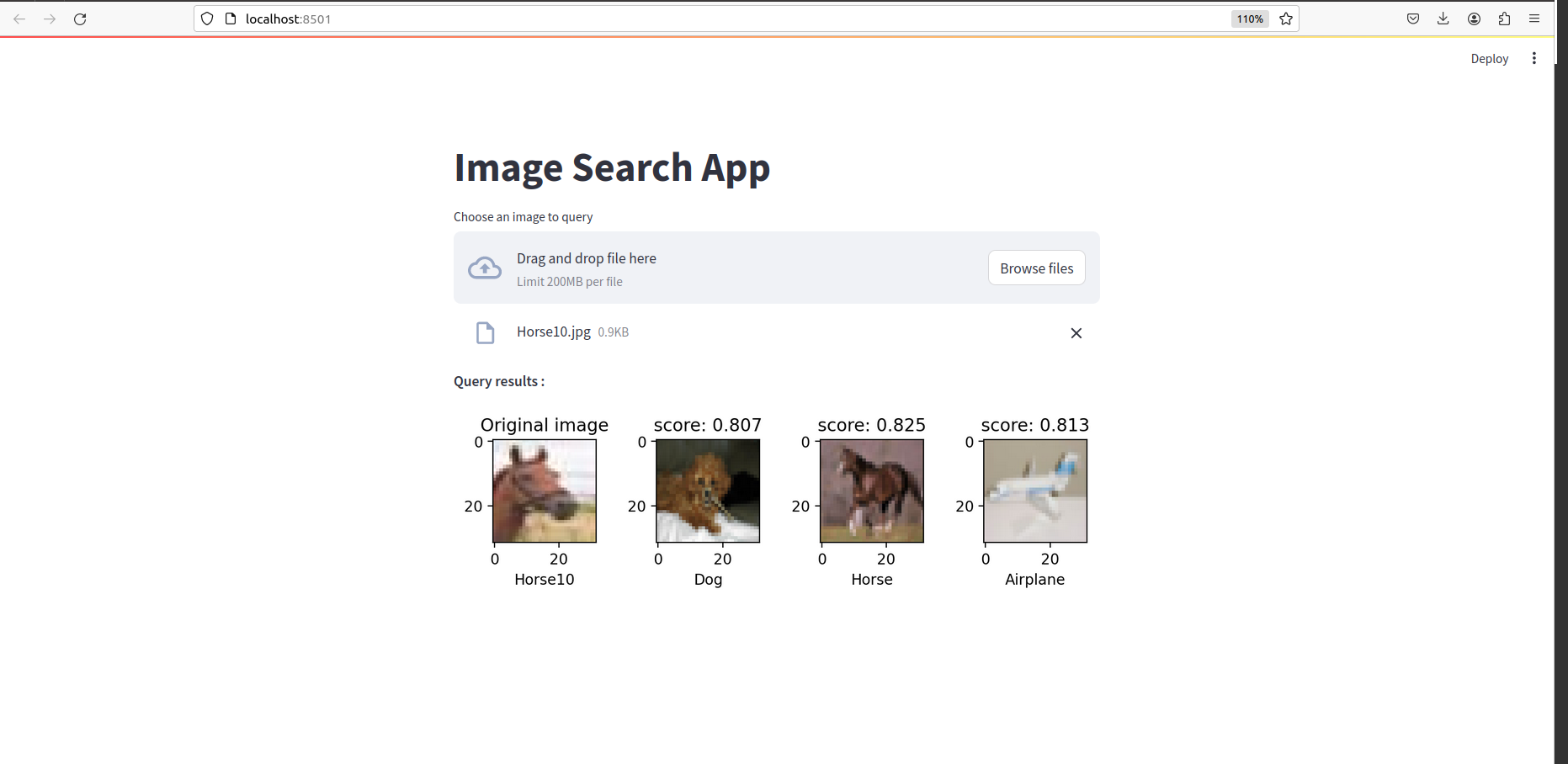
すべてが完了したら、次のようなものが表示されるはずです。