image_search
1.0.0
Das Aufkommen des Internets revolutionierte die Art und Weise, wie wir über potente Suchmaschinen wie Google, Bing und Yandex auf Informationen zugreifen. Mit nur wenigen Schlüsselwörtern können wir schnell Webseiten finden, die für unsere Abfragen relevant sind. Als Technologie, insbesondere KI, Fortschritte, ermöglichen viele Suchmaschinen jetzt Online -Image -Suche.
Es wurden verschiedene Techniken zur Bildsuchung aufgetaucht, darunter:
In diesem Projekt werden wir ein vorgebildetes Faltungsfischnetz (CNN) verwenden, um wertvolle Merkmale aus den Bildern zu extrahieren. Diese Methodik, eine Schlüsselkomponente der inhaltsbasierten Bildsuche, bietet die folgenden Vorteile:
Zusammenfassend möchten wir in dieser Studie die folgende Frage beantworten: Sind zwei ähnliche Bilder, die die Einbettung miteinander verbunden sind, immer noch ähnlich?
Für dieses Projekt haben wir die CIFAR-10 verwendet. Es ist ein frei verfügbarer Datensatz, der 60.000 Farbbilder umfasst, die jeweils 32 x 32 Pixel messen. Diese Bilder gehören zu 10 verschiedenen Kategorien: Flugzeug, Auto, Vogel, Katze, Hirsche, Hund, Frosch, Pferd, Schiff und LKW. Um ihre entsprechenden Einbettungen zu erhalten, haben wir ein vorgebildetes CNN-Modell angewendet, insbesondere VGG-16 , um wesentliche Merkmale zu extrahieren. Der resultierende Vektor ist 512-dimensional . Innerhalb von Pinecone haben wir einen Index mit dem Namen "Images" mit einer Dimension von 512 erstellt, in der alle diese Vektoren gespeichert werden.
Die Idee hinter diesem Projekt besteht darin, zu finden, ob ähnliche Bilder von Vögeln beispielsweise ähnliche Einbettungen haben. Zu diesem Zweck haben wir 50.000 der insgesamt 60.000 Bilder zugeordneten Einbettungen in einen Tinecone -Index hochgeladen. Diese Partition wurde durchgeführt, um sicherzustellen, dass wir völlig neue und unterschiedliche Bilder im Vergleich zu den bereits als Vektoren in Tinecone gespeicherten Bildern haben. Beachten Sie auch, dass diese Paritionierung bereits vom CIFAR-10-Datensatz in Zug- und Teststapel durchgeführt wird, die die serialisierten Versionen der Originalbilder-Arrays darstellen.
Die folgende Picutre beschreibt den gesamten Prozess des Speicherns der Einbettungen in einen Tinecone -Index. Vom ersten Schritt zum Lesen der Bilder, wenden Sie sich an ein vorgebildetes VGG16-Neuralnetzwerk, um 512 dimensionale Einbettungen zu generieren, die dann in einem Tinecone-Index aufgerichtet (dh gespeichert) werden. 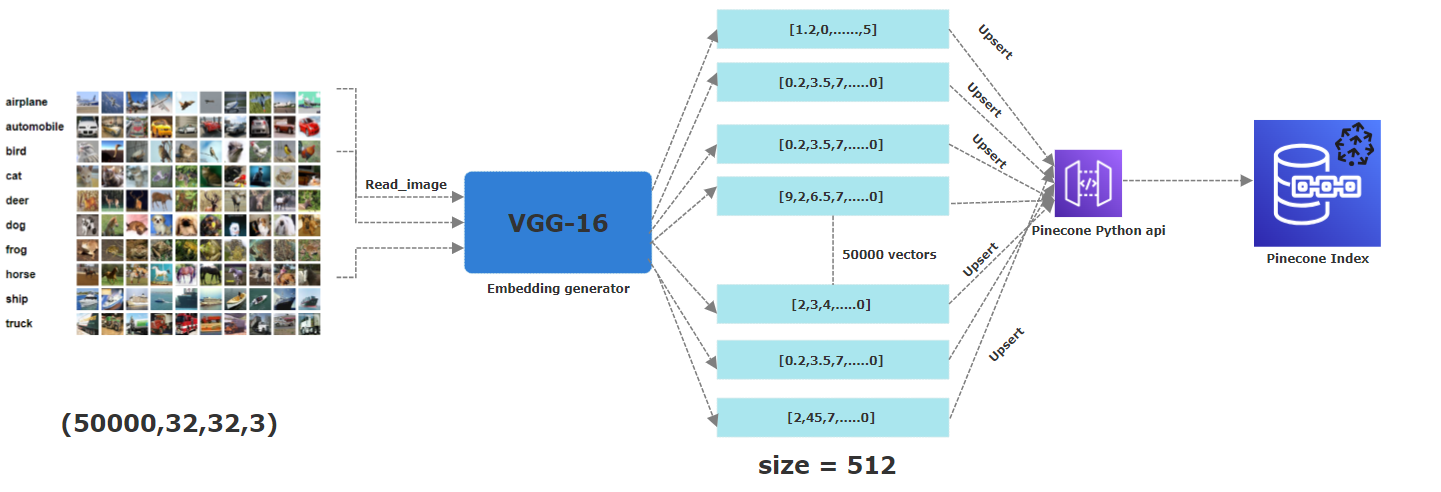
In diesem Projekt behandeln wir 50.000 Bilder, die einige Herausforderungen in Bezug auf die Vergleich darstellen, insbesondere beim Lesen von Bildern, unpickle (wir haben die serialisierte CIFAR-10-Dataset-Version heruntergekommen) und Funktionen über ein CNN extrahieren. Wir haben versucht, die Leistung des Parrallel Computing beim Ausführen unseres Codes so schnell wie möglich auf mehreren CPU -Kernen über Multithreading zu nutzen.
HINWEIS: Führen Sie dieses Projekt in einer GPU -Umgebung für schnellere Berechnungen aus.
Erstellen Sie hier kostenlos ein Tinecone -Konto.
Holen Sie sich den API -Schlüssel und die Umgebung, die Ihrem Tinecone -Konto zugeordnet ist
Klonen Sie dieses Repo (für Hilfe dieses Tutorial).
Erstellen Sie eine virtuelle Umgebung im Projektordner (um Hilfe in diesem Tutorial zu erhalten).
Führen Sie den folgenden Befehl aus, um die erforderlichen Pakete zu installieren.
pip3 install -r requirements.txt
pip install -r requirements.txt
python insert_data.py -key <API_KEY> -env <ENV> -metric <METRIC>
Ersetzen Sie <v> und <API_KEY> durch die Werte, die Sie von Ihrem Pinecone -Konto erhalten. Warten Sie, bis das Skript erledigt wird. 7. Starten Sie die App mit den folgenden.
streamlit run app.py -- -key <API_KEY> -env <ENV>
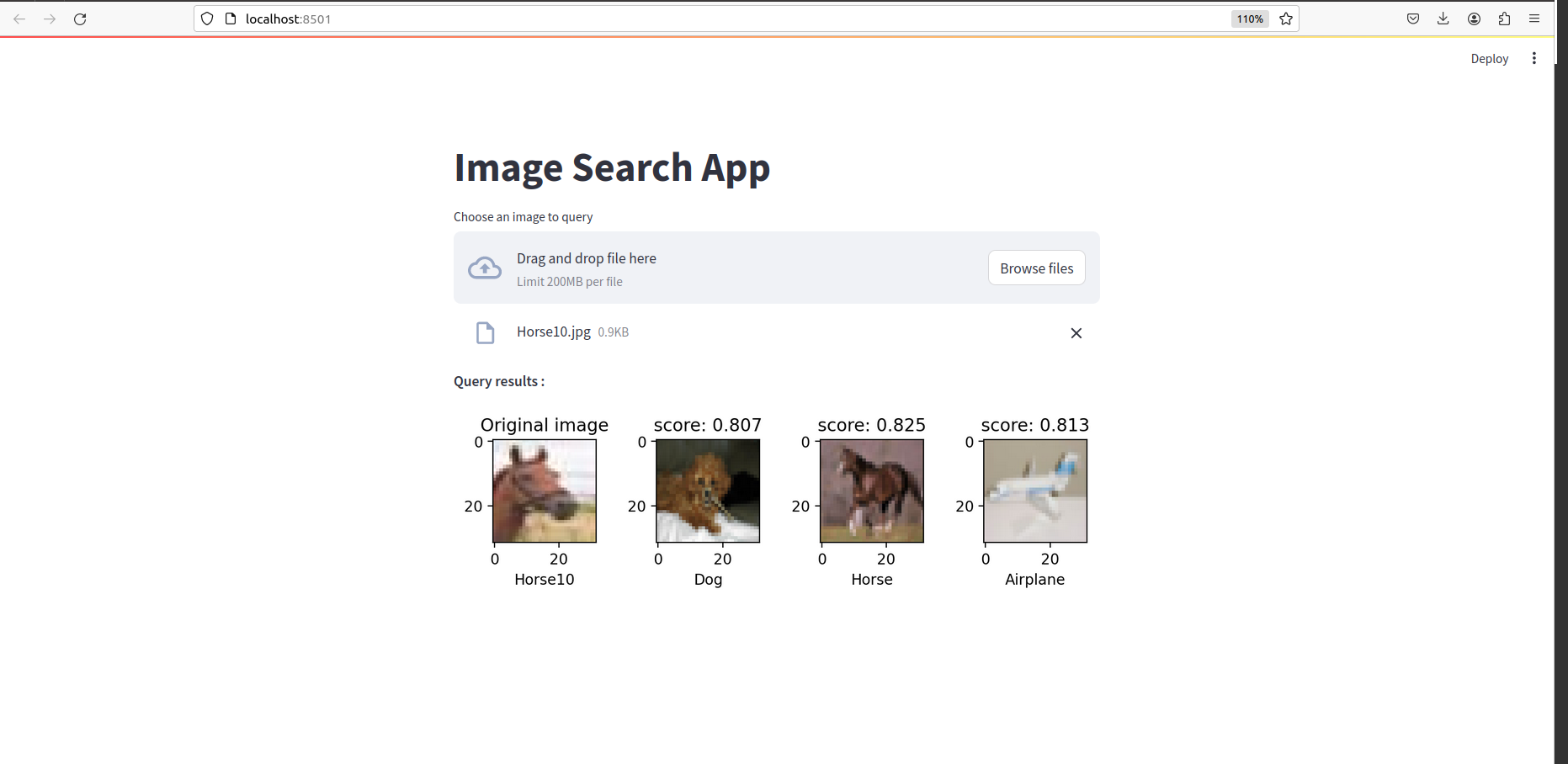
Sobald alles erledigt ist, sollten Sie so etwas sehen: