image_search
1.0.0
L'avènement d'Internet a révolutionné la façon dont nous accédons aux informations via de puissants moteurs de recherche tels que Google, Bing et Yandex. Avec seulement quelques mots clés, nous pouvons trouver rapidement des pages Web pertinentes pour nos requêtes. À mesure que la technologie, en particulier l'IA, les progrès, de nombreux moteurs de recherche facilitent désormais les recherches d'images en ligne.
Diverses techniques de recherche d'images ont émergé, notamment:
Dans ce projet, nous utiliserons un réseau neuronal convolutionnel pré-formé (CNN) pour extraire des fonctionnalités précieuses des images. Cette méthodologie, un composant clé de la recherche d'images basée sur le contenu, fournit les avantages suivants:
En résumé, dans cette étude, nous aimerons répondre à la question suivante: deux images similaires associées à l'intégration sont-elles toujours similaires?
Pour ce projet, nous avons utilisé le CIFAR-10. Il s'agit d'un ensemble de données disponible librement comprenant 60 000 images en couleur, chacune mesurant 32x32 pixels . Ces images appartiennent à 10 catégories distinctes: avion, automobile, oiseau, chat, cerf, chien, grenouille, cheval, navire et camion. Pour obtenir leurs intérêts correspondants, nous avons appliqué un modèle CNN pré-formé, en particulier le VGG-16 , pour extraire des caractéristiques essentielles. Le vecteur résultant est 512-dimension . Dans Pinecone, nous avons créé un index nommé "Images" avec une dimension de 512, où tous ces vecteurs seront stockés.
L'idée derrière ce projet est de trouver si des images similaires d'oiseaux par exemple ont des intégres similaires. Pour ce faire, nous avons téléchargé 50 000 sur le total des 60 000 images associées à l'intégration à un index de poireau. Cette partition a été faite pour nous assurer que nous avons des images entièrement nouvelles et distinctes par rapport à celles déjà stockées en tant que vecteurs en pinone. Notez également que cette partion est déjà effectuée par l'ensemble de données CIFAR-10 dans des lots de train et de test représentant les versions sérialisées des tableaux d'images originaux.
Le Picutre ci-dessous décrit l'ensemble du processus de stockage des intérêts à un index de pinone. Depuis la première étape de la lecture des images, appliquant un réseau neuronal VGG16 pré-formé pour générer 512 embellis dimensionnels qui sont ensuite mis en place (c'est-à-dire stockés) dans un index de pinone. 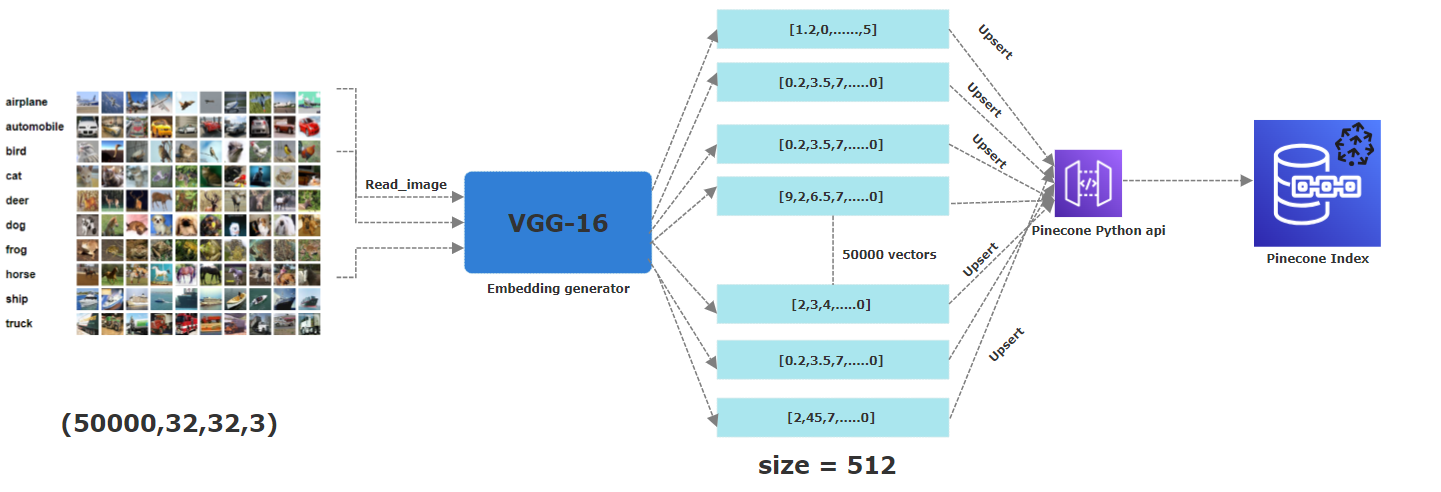
Dans ce projet, nous gérons 50 000 images, qui posent des défis en termes de compatation, en particulier lors de la lecture d'images, débordant (nous avons réduit la version sérialisée de DataSet CIFAR-10) et extrait les fonctionnalités via un CNN. Nous avons essayé de tirer parti de la puissance de l'informatique parallèle lors de l'exécution de notre code afin que tout fonctionne aussi rapidement que possible sur plusieurs cœurs de CPU via le multithreading.
Remarque: Si possible, exécutez ce projet sur un environnement alimenté par GPU pour des calculs plus rapides.
Créez gratuitement un compte PineCone ici.
Obtenez la clé API et l'environnement associé à votre compte de pinone
Clone ce dépôt (pour aider à voir ce tutoriel).
Créez un environnement virtuel dans le dossier du projet (pour aider à voir ce tutoriel).
Exécutez la commande suivante pour installer les packages nécessaires.
pip3 install -r requirements.txt
pip install -r requirements.txt
python insert_data.py -key <API_KEY> -env <ENV> -metric <METRIC>
Remplacez <env> et <api_key> par les valeurs que vous obtenez de votre compte PineCone. Attendez que le script soit terminé. 7. Lancez l'application en utilisant les éléments suivants.
streamlit run app.py -- -key <API_KEY> -env <ENV>
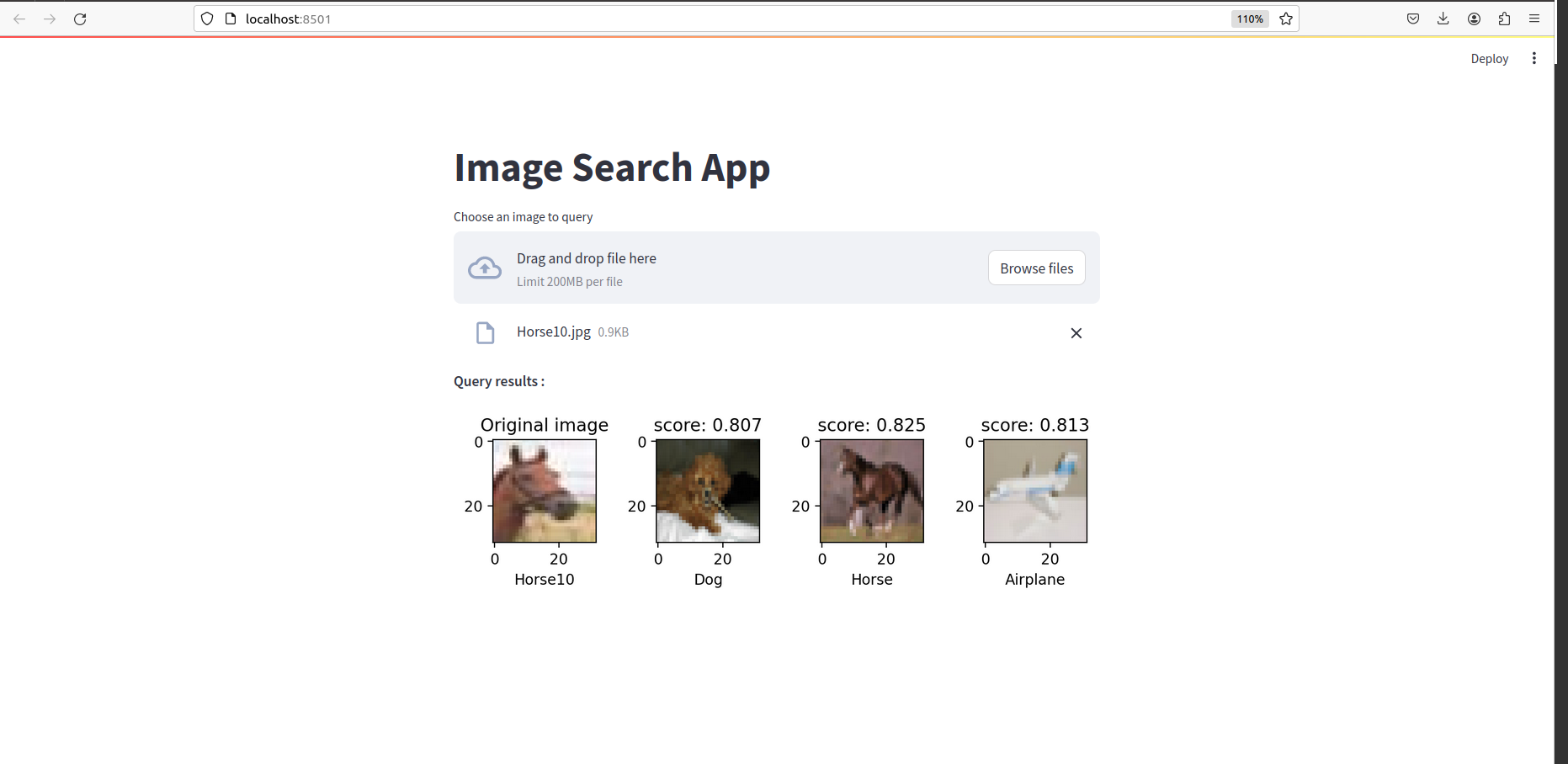
Une fois que tout est fait, vous devriez voir quelque chose comme ceci: