image_search
1.0.0
O advento da Internet revolucionou a maneira como acessamos informações por meio de motores de pesquisa potentes como Google, Bing e Yandex. Com apenas algumas palavras -chave, podemos localizar rapidamente páginas da web pertinentes às nossas consultas. Como tecnologia, particularmente a IA, avança, muitos mecanismos de pesquisa agora facilitam as pesquisas de imagens on -line.
Surgiram várias técnicas para pesquisa de imagens, incluindo:
Neste projeto, usaremos uma rede neural convolucional pré-treinada (CNN) para extrair recursos valiosos das imagens. Essa metodologia, um componente-chave da pesquisa de imagem baseada em conteúdo, fornece os seguintes benefícios:
Em resumo, neste estudo, gostaríamos de responder à seguinte pergunta: Duas imagens similares associadas a incorporação ainda são semelhantes?
Para este projeto, usamos o CIFAR-10. É um conjunto de dados disponível gratuitamente, compreendendo 60.000 imagens coloridas, cada uma medindo 32x32 pixels . Essas imagens pertencem a 10 categorias distintas: avião, automóvel, pássaro, gato, veado, cachorro, sapo, cavalo, navio e caminhão. Para obter suas incorporações correspondentes, aplicamos um modelo CNN pré-treinado, especificamente VGG-16 , para extrair recursos essenciais. O vetor resultante é 512-dimensional . Na Pinecone, criamos um índice chamado "imagens" com uma dimensão de 512, onde todos esses vetores serão armazenados.
A idéia por trás deste projeto é descobrir se imagens semelhantes de pássaros, por exemplo, têm incorporações semelhantes. Para fazer isso, enviamos 50.000 do total de 60.000 imagens associadas a incorporação a um índice Pinecone. Esta partição foi feita para garantir que tenhamos imagens totalmente novas e distintas em comparação com as já armazenadas como vetores em Pinecone. Observe também que esse parição já é feito pelo conjunto de dados CIFAR-10 em lotes de trem e teste, representando as versões serializadas das matrizes de imagens originais.
O picutre abaixo descreve todo o processo de armazenar as incorporações em um índice de pinecone. Desde a primeira etapa da leitura das imagens, a aplicação de uma rede neural VGG16 pré-treinada para gerar incorporações dimensionais 512 que são então ascendentes (ou seja, armazenadas) em um índice de pinecone. 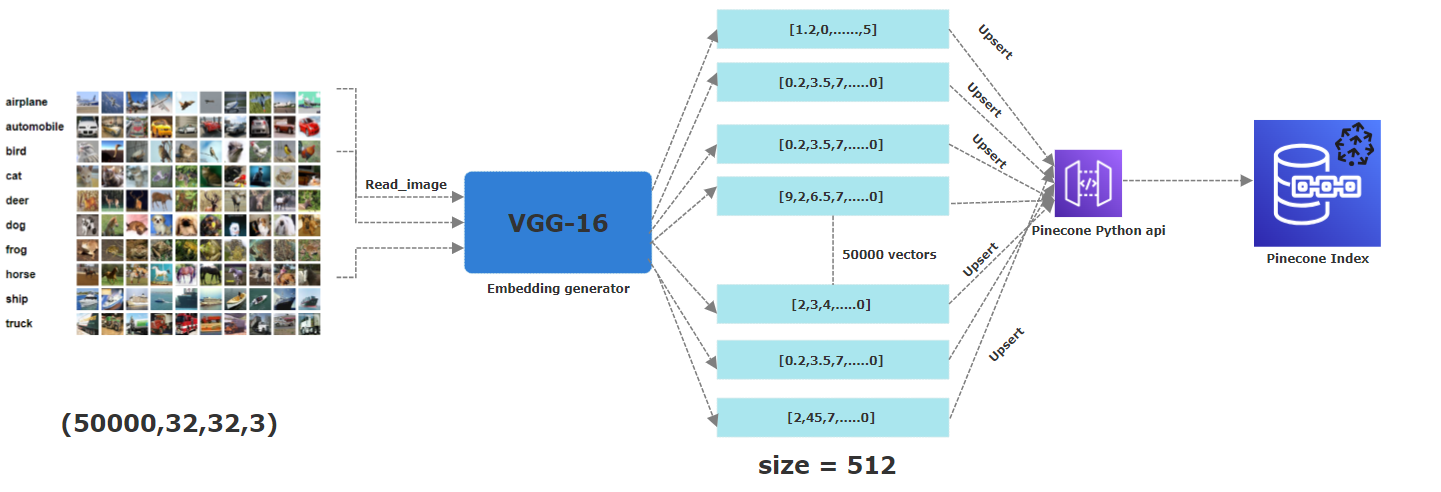
Neste projeto, estamos lidando com 50 mil imagens, que apresentam alguns desafios em termos de compição, especialmente ao ler imagens, descompactar (nós downlaodamos a versão serializada do conjunto de dados CIFAR-10) e extrair recursos por meio de uma CNN. Tentamos aproveitar o poder da computação paralelo ao executar nosso código para que tudo funcione o mais rápido possível em vários núcleos de CPU via multithreading.
Nota: Se possível, execute este projeto em um ambiente alimentado por GPU para cálculos mais rápidos.
Crie uma conta Pinecone gratuitamente aqui.
Obtenha a chave da API e o ambiente associado à sua conta Pinecone
Clone este repositório (para obter ajuda para ver este tutorial).
Crie um ambiente virtual na pasta do projeto (para obter ajuda, consulte este tutorial).
Execute o seguinte comando para instalar os pacotes necessários.
pip3 install -r requirements.txt
pip install -r requirements.txt
python insert_data.py -key <API_KEY> -env <ENV> -metric <METRIC>
Substitua <INV> e <PI_KEY> pelos valores que você obtém da sua conta Pinecone. Aguarde o script ser feito. 7. Inicie o aplicativo usando o seguinte.
streamlit run app.py -- -key <API_KEY> -env <ENV>
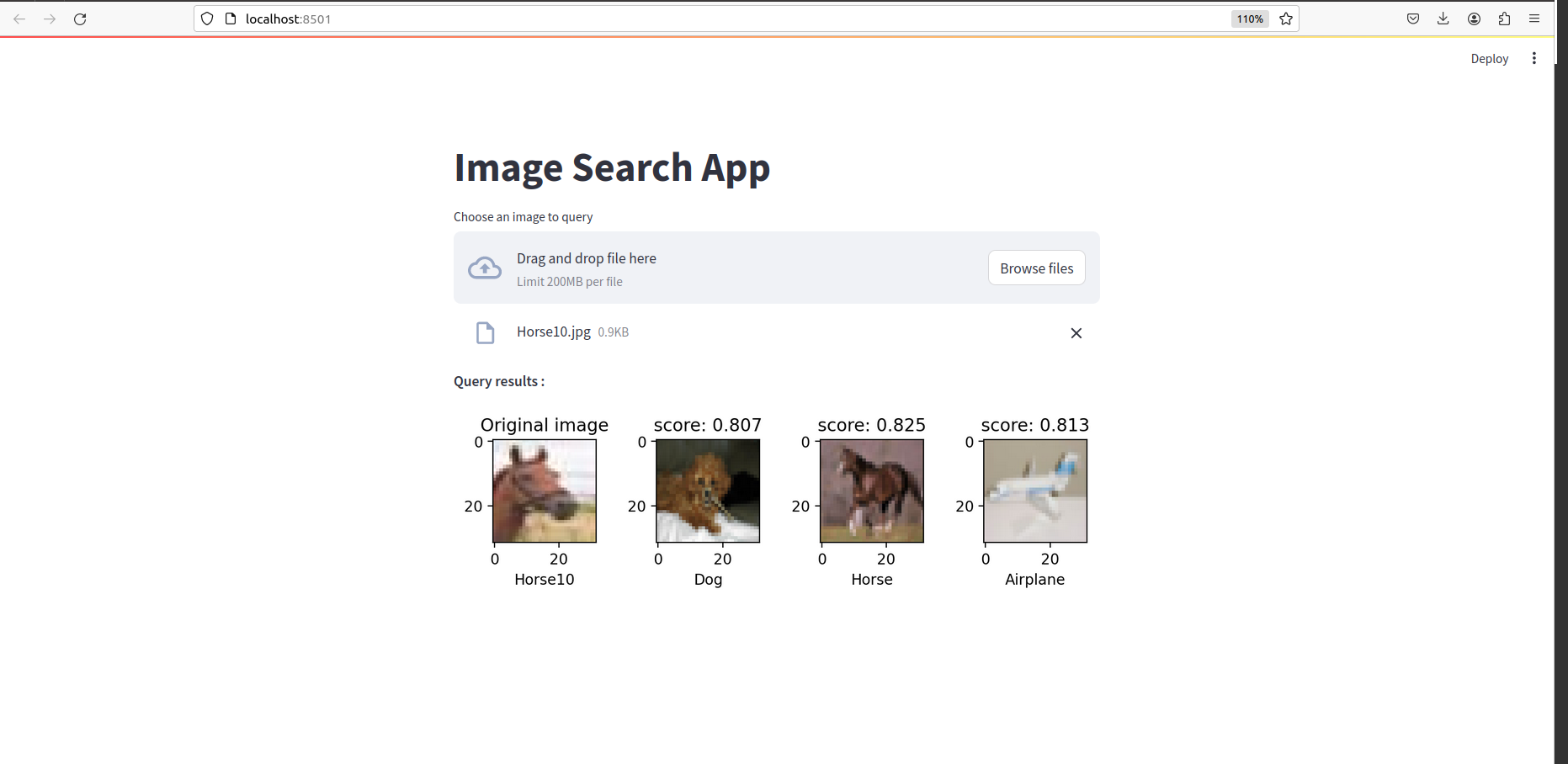
Depois que tudo estiver feito, você deve ver algo assim: