image_search
1.0.0
互联网的出现彻底改变了我们通过Google,Bing和Yandex等有效搜索引擎访问信息的方式。只有几个关键字,我们可以迅速找到与我们的查询有关的网页。随着技术,尤其是AI的进步,许多搜索引擎现在促进了在线图像搜索。
出现了各种图像搜索技术,包括:
在这个项目中,我们将使用预训练的卷积神经网络(CNN)从图像中提取有价值的特征。此方法是基于内容的图像搜索的关键组成部分,它提供了以下好处:
总而言之,在这项研究中,我们想回答以下问题:相关嵌入的两个类似图像是否仍然相似?
对于这个项目,我们使用了CIFAR-10。它是一个免费可用的数据集,其中包括60,000个颜色图像,每个图像的尺寸为32x32像素。这些图像属于10个不同的类别:飞机,汽车,鸟,猫,鹿,狗,青蛙,马,船和卡车。为了获得其相应的嵌入,我们应用了预先训练的CNN模型,特别是VGG-16 ,以提取基本特征。结果矢量为512维。在Pinecone中,我们创建了一个名为“图像”的索引,其尺寸为512,其中所有这些向量都将存储。
该项目背后的想法是找到例如类似的鸟类图像是否具有相似的嵌入。为此,我们已经在与Pinecone指数相关的60,000张图像中上传了50,000张。与已经存储在Pinecone中的向量的图像相比,该分区是为了确保我们拥有全新的图像。另请注意,这种分析已经由CIFAR-10数据集完成到火车上,并代表代表原始图像阵列的序列化版本的测试批次。
下面的PICUTRE描述了将嵌入到Pinecone索引的整个过程。从读取图像的第一步开始,应用预先训练的VGG16神经网络生成512个维嵌入,然后将其上述(即存储)在Pinecone索引中。 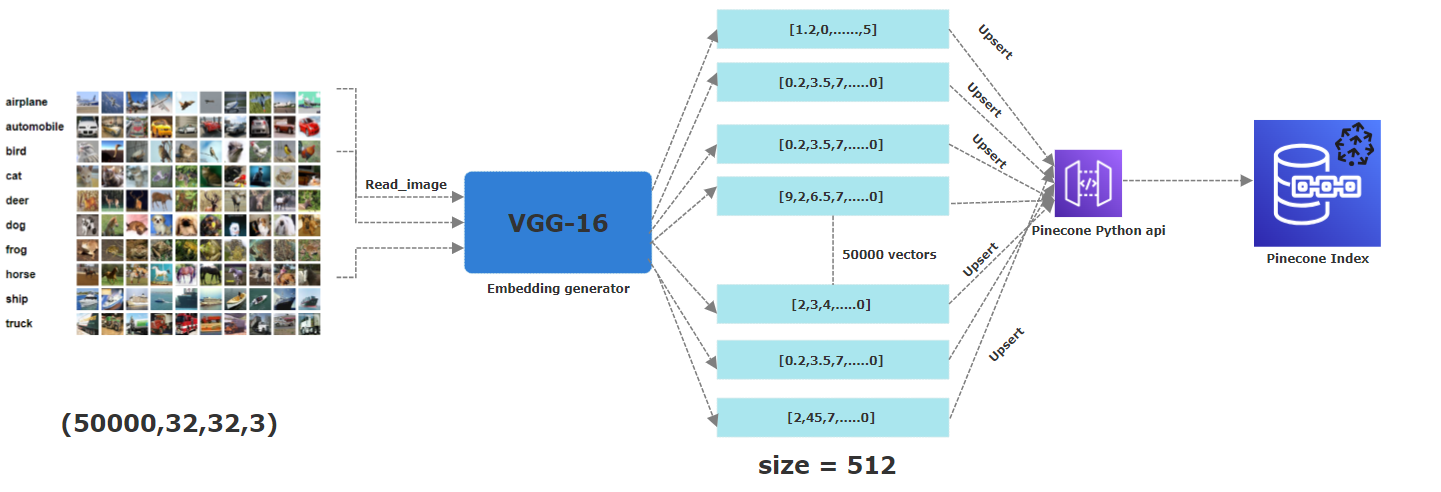
在这个项目中,我们正在处理5万张图像,这在兼容方面构成了一些挑战,尤其是在阅读图像时(我们已经将CIFAR-10数据集序列化版本)删除并通过CNN提取功能。我们试图在运行代码时利用帕拉利计算的功能,以便通过多线程在多个CPU内核上尽可能快地运行。
注意:如果可能的话,请在GPU驱动的环境上运行此项目,以进行更快的计算。
在此处免费创建Pinecone帐户。
获取与Pinecone帐户相关的API密钥和环境
克隆此存储库(有关帮助,请参阅本教程)。
在项目文件夹中创建虚拟环境(有关帮助请参见本教程)。
运行以下命令安装必要的软件包。
pip3 install -r requirements.txt
pip install -r requirements.txt
python insert_data.py -key <API_KEY> -env <ENV> -metric <METRIC>
将<env>和<API_KEY>替换为您从Pinecone帐户中获得的值。等待脚本完成。 7。使用以下内容启动该应用程序。
streamlit run app.py -- -key <API_KEY> -env <ENV>
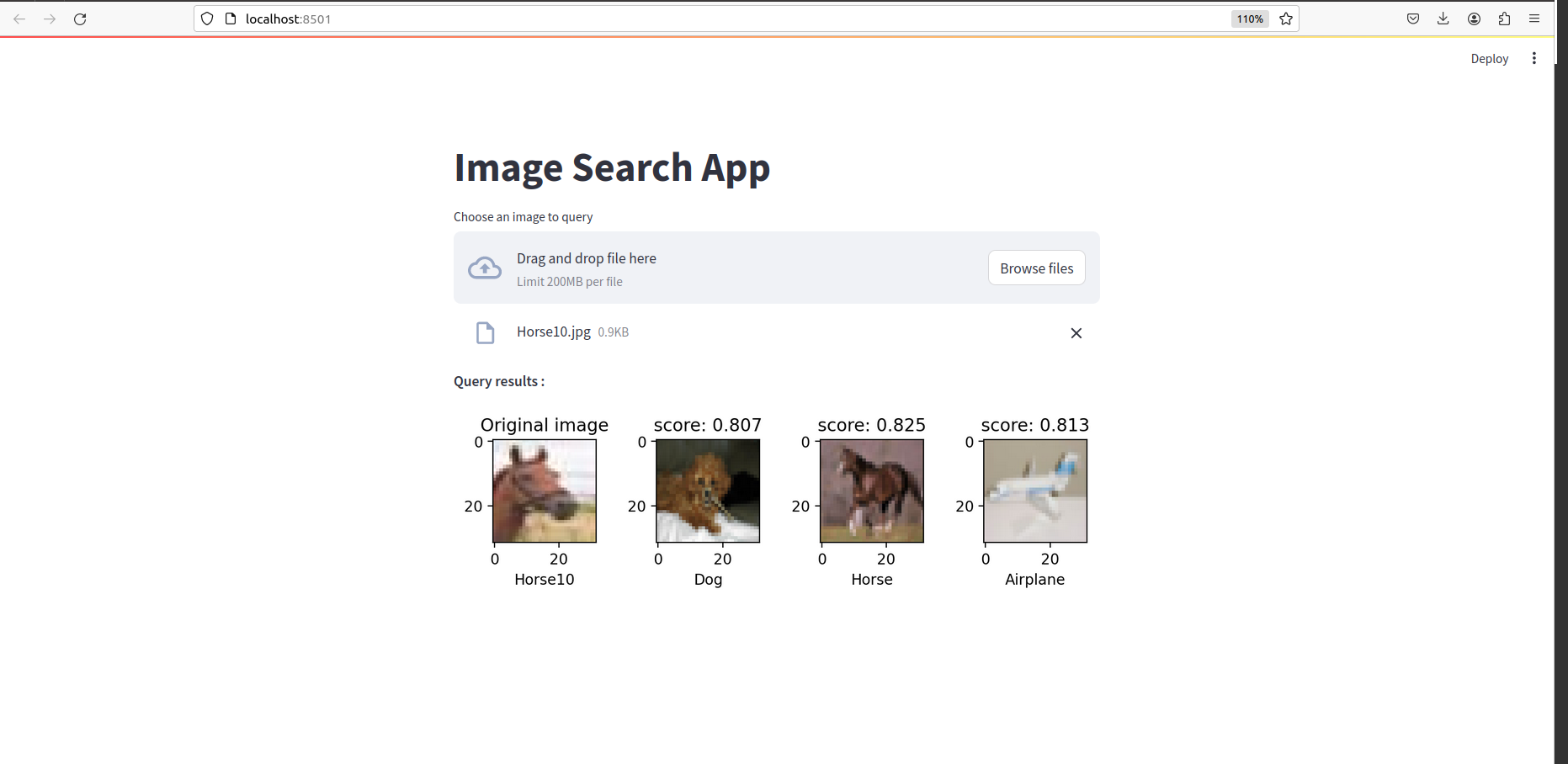
一旦完成了一切,您就应该看到这样的东西: