image_search
1.0.0
El advenimiento de Internet revolucionó la forma en que accedemos a la información a través de potentes motores de búsqueda como Google, Bing y Yandex. Con solo algunas palabras clave, podemos localizar rápidamente páginas web pertinentes a nuestras consultas. Como la tecnología, particularmente la IA, avanza, muchos motores de búsqueda ahora facilitan las búsquedas de imágenes en línea.
Han surgido varias técnicas para la búsqueda de imágenes, que incluyen:
En este proyecto, utilizaremos una red neuronal convolucional (CNN) previamente entrenada para extraer características valiosas de las imágenes. Esta metodología, un componente clave de la búsqueda de imágenes basada en contenido, proporciona los siguientes beneficios:
En resumen, en este estudio nos gustaría responder a la siguiente pregunta: ¿Las dos imágenes similares asociadas son similares?
Para este proyecto, hemos utilizado el CIFAR-10. Es un conjunto de datos disponible gratuitamente que comprende 60,000 imágenes en color, cada una de las cuales mide 32x32 píxeles . Estas imágenes pertenecen a 10 categorías distintas: avión, automóvil, pájaro, gato, ciervo, perro, rana, caballo, barco y camión. Para obtener sus incrustaciones correspondientes, aplicamos un modelo CNN previamente entrenado, específicamente VGG-16 , para extraer características esenciales. El vector resultante es 512-dimensional . Dentro de Pinecone, creamos un índice llamado "imágenes" con una dimensión de 512, donde se almacenarán todos estos vectores.
La idea detrás de este proyecto es encontrar si las imágenes similares de pájaros, por ejemplo, tienen incrustaciones similares. Para hacerlo, hemos subido 50,000 del total de 60,000 imágenes asociadas a un índice de piña. Esta partición se realizó para garantizar que tengamos imágenes completamente nuevas y distintas en comparación con las ya almacenadas como vectores en Pinecone. También tenga en cuenta que el conjunto de datos CIFAR-10 ya realiza este parición en lotes de tren y prueba que representan las versiones serializadas de las matrices de imágenes originales.
La imagen a continuación describe todo el proceso de almacenar los incrustaciones en un índice de piña. Desde el primer paso de leer las imágenes, aplicando una red neuronal VGG16 previamente capacitada para generar 512 embarcaciones dimensionales que luego se elevan (es decir, almacenadas) en un índice de piña. 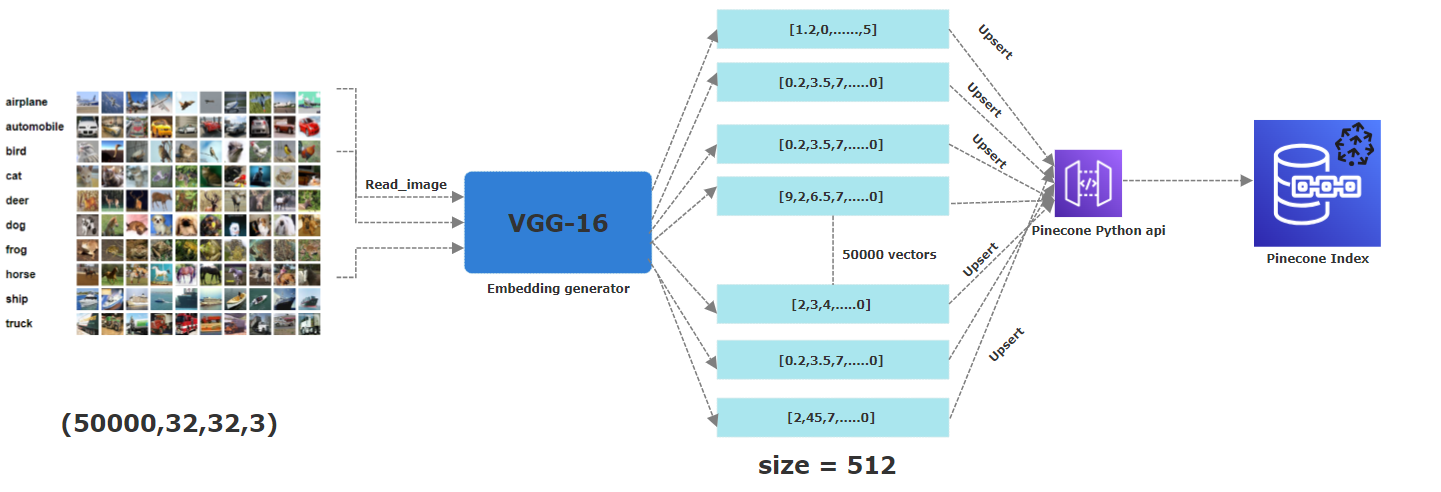
En este proyecto, estamos manejando 50 mil imágenes, que plantean algunos desafíos en términos de compución, especialmente cuando leen imágenes, no hemos disminuido la versión serializada del conjunto de datos CIFAR-10) y extrayendo características a través de un CNN. Intentamos aprovechar la potencia de la computación paralela al ejecutar nuestro código para que todo se ejecute lo más rápido posible en múltiples núcleos de CPU a través de múltiples lecturas.
Nota: Si es posible, ejecute este proyecto en un entorno alimentado por GPU para cálculos más rápidos.
Cree una cuenta de Pinecone gratis aquí.
Obtenga la clave API y el ambiente asociado a su cuenta de Pinecone
Clone este repositorio (para obtener ayuda, vea este tutorial).
Cree un entorno virtual en la carpeta del proyecto (para obtener ayuda, consulte este tutorial).
Ejecute el siguiente comando para instalar los paquetes necesarios.
pip3 install -r requirements.txt
pip install -r requirements.txt
python insert_data.py -key <API_KEY> -env <ENV> -metric <METRIC>
Reemplace <env> y <pi_key> con los valores que obtiene de su cuenta Pinecone. Espere a que se haga el guión. 7. Inicie la aplicación usando la siguiente.
streamlit run app.py -- -key <API_KEY> -env <ENV>
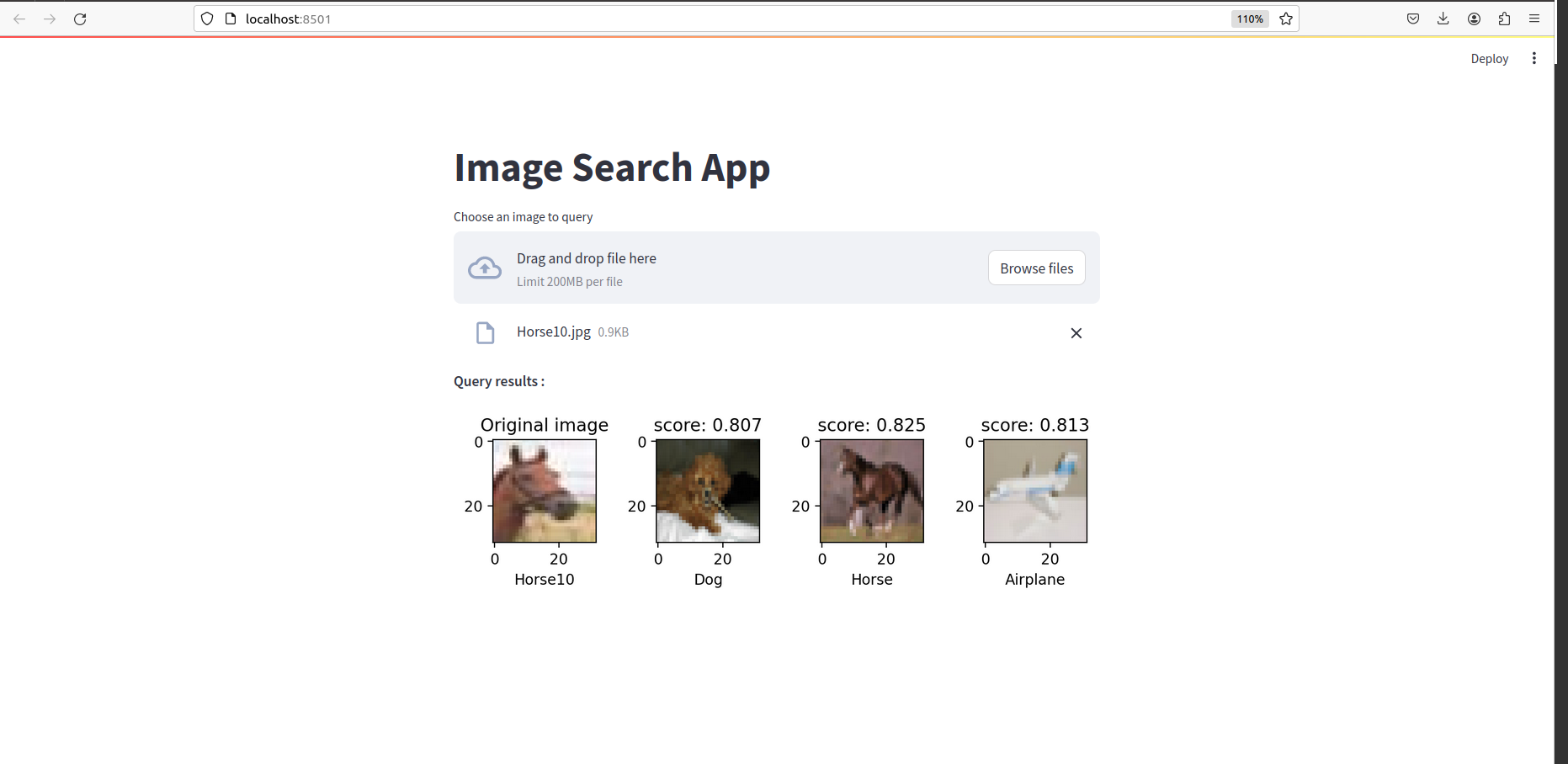
Una vez que todo esté hecho, deberías ver algo como esto: