image_search
1.0.0
Появление Интернета произвело революцию в том, как мы получаем доступ к информации с помощью мощных поисковых систем, таких как Google, Bing и Yandex. С помощью всего лишь нескольких ключевых слов мы можем быстро найти веб -страницы, относящиеся к нашим запросам. Как технология, особенно ИИ, достижения, многие поисковые системы теперь облегчают поиск изображений в Интернете.
Появились различные методы поиска изображений, в том числе:
В этом проекте мы будем использовать предварительно обученную сверточную нейронную сеть (CNN) для извлечения ценных функций из изображений. Эта методология, ключевой компонент поиска на основе контента, предоставляет следующие преимущества:
Таким образом, в этом исследовании мы хотели бы ответить на следующий вопрос: Являются ли два аналогичных изображения, связанные с ним, все еще похожи?
Для этого проекта мы использовали CIFAR-10. Это свободно доступный набор данных, содержащий 60 000 цветных изображений, каждый из которых измеряет 32x32 пикселей . Эти изображения принадлежат 10 различным категориям: самолет, автомобиль, птица, кошка, оленя, собака, лягушка, лошадь, корабль и грузовик. Чтобы получить их соответствующие встраивания, мы применили предварительно обученную модель CNN, в частности VGG-16 , для извлечения основных функций. Полученный вектор 512-мерный . В Pinecone мы создали индекс под названием «изображения» с измерением 512, где будут храниться все эти векторы.
Идея этого проекта состоит в том, чтобы найти, есть ли подобные изображения птиц, например, похожие встраивания. Для этого мы загрузили 50 000 из 60 000 изображений, связанных с индексом Pinecone. Этот раздел был сделан для того, чтобы у нас были совершенно новые и отличные изображения по сравнению с теми, которые уже хранятся как векторы в Pinecone. Также обратите внимание, что эта паурирование уже выполняется набором данных CIFAR-10 в пакетах поезда и тестирования, представляющие сериализованные версии оригинальных массивов изображений.
PICUTRE ниже описывает весь процесс хранения встроений в индекс Pinecone. С первого этапа чтения изображений применение предварительно обученной нейронной сети VGG16 для генерации 512 размерных погружений, которые затем поднимаются (т.е. хранятся) в индексе Pinecone. 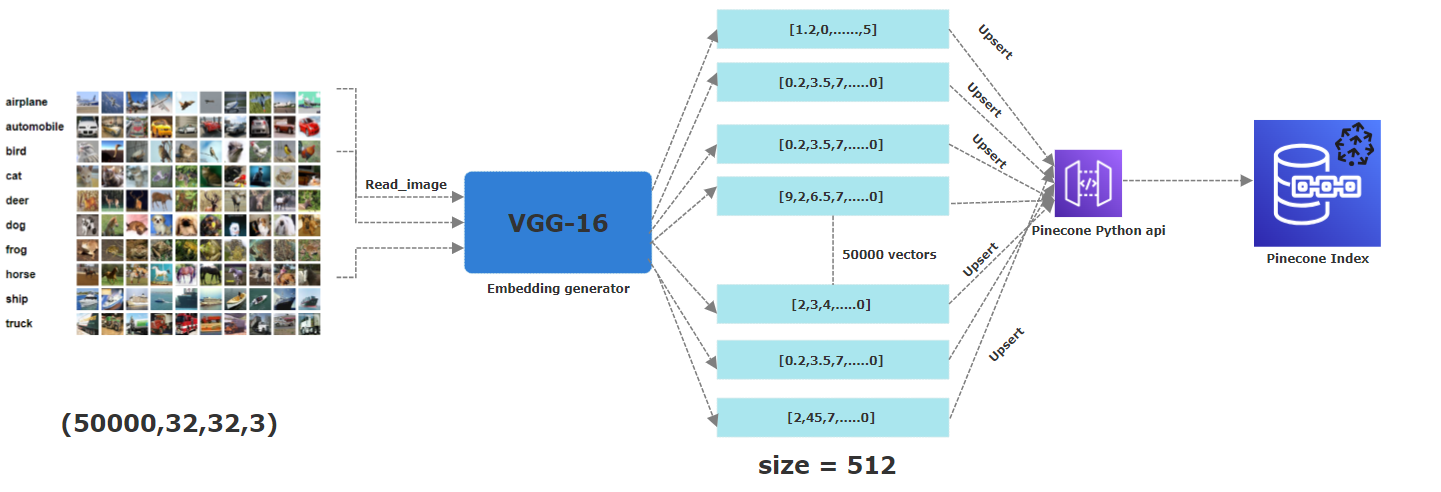
В этом проекте мы обрабатываем 50 тысяч изображений, которые ставят некоторые проблемы с точки зрения составления, особенно при чтении изображений, утихли (мы понизили сериализованную версию набора данных CIFAR-10) и извлечение функций через CNN. Мы попытались использовать мощность парраллельных вычислений при запуске нашего кода, чтобы все работало как можно быстрее на нескольких ядрах процессоров через многопоточное.
ПРИМЕЧАНИЕ. Если возможно, запустите этот проект в среде, работающей на графическом процессоре, для более быстрых вычислений.
Создайте учетную запись Pinecone бесплатно здесь.
Получите ключ и среду API, связанные с вашей учетной записью Pinecone
Клонировать это репо (для получения помощи, чтобы увидеть этот урок).
Создайте виртуальную среду в папке Project (для получения помощи просмотреть этот урок).
Запустите следующую команду, чтобы установить необходимые пакеты.
pip3 install -r requirements.txt
pip install -r requirements.txt
python insert_data.py -key <API_KEY> -env <ENV> -metric <METRIC>
Замените <enc> и <pi_key> на значения, которые вы получаете из своей учетной записи Pinecone. Подождите, пока сценарий будет выполнен. 7. Запустите приложение, используя следующее.
streamlit run app.py -- -key <API_KEY> -env <ENV>
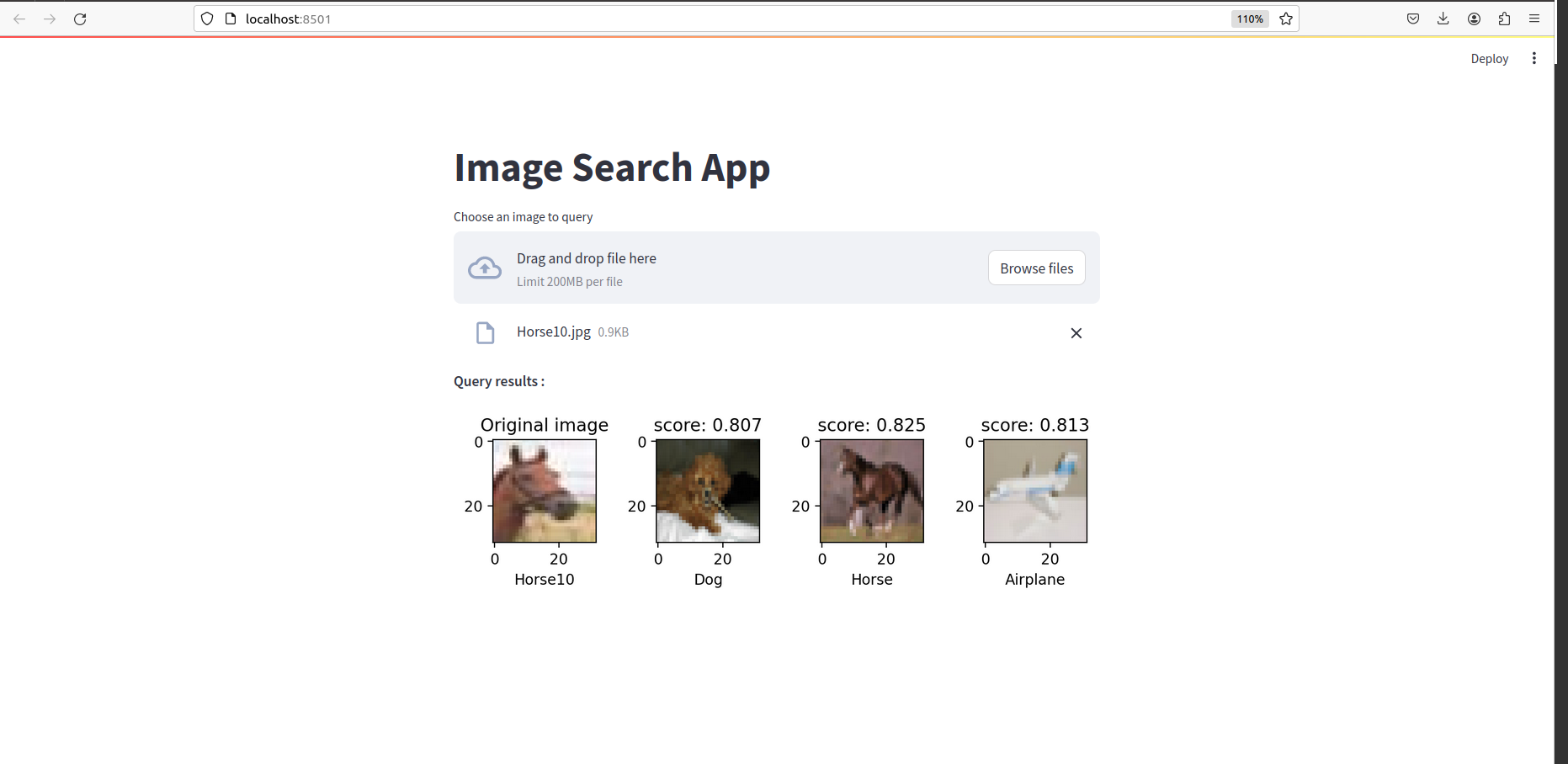
Как только все будет сделано, вы должны увидеть что -то вроде этого: