image_search
1.0.0
인터넷의 출현은 Google, Bing 및 Yandex와 같은 강력한 검색 엔진을 통해 정보에 액세스하는 방식에 혁명을 일으켰습니다. 몇 가지 키워드만으로도 쿼리와 관련된 웹 페이지를 신속하게 찾을 수 있습니다. 기술, 특히 AI, 발전으로서 많은 검색 엔진이 이제 온라인 이미지 검색을 용이하게합니다.
이미지 검색 기술이 다음을 포함하여 등장했습니다.
이 프로젝트에서는 미리 훈련 된 CNN (Convolutional Neural Network)을 사용하여 이미지에서 귀중한 기능을 추출합니다. 컨텐츠 기반 이미지 검색의 핵심 구성 요소 인이 방법론은 다음과 같은 이점을 제공합니다.
요약하면,이 연구에서 우리는 다음과 같은 질문에 답하고 싶습니다. 관련된 두 가지 이미지와 관련된 두 가지 이미지가 여전히 비슷합니까?
이 프로젝트에서는 CIFAR-10을 사용했습니다. 60,000 개의 컬러 이미지로 구성된 자유롭게 사용할 수있는 데이터 세트로 각각 32x32 픽셀을 측정합니다. 이 이미지는 비행기, 자동차, 새, 고양이, 사슴, 개, 개구리, 말, 선박 및 트럭의 10 가지 범주에 속합니다. 상응하는 임베딩을 얻기 위해, 우리는 미리 훈련 된 CNN 모델, 특히 VGG-16을 적용하여 필수 기능을 추출했습니다. 결과 벡터는 512 차원 입니다. Pinecone 내에서, 우리는 512 차원의 "이미지"라는 색인을 만들었습니다. 여기서 모든 벡터가 저장됩니다.
이 프로젝트의 배후에있는 아이디어는 예를 들어 조류의 비슷한 이미지에 비슷한 내장이 있는지 찾는 것입니다. 그렇게하기 위해, 우리는 Pinecone 지수에 포함 된 총 60,000 개의 이미지 중 5 만 건물을 업로드했습니다. 이 파티션은 이미 Pinecone의 벡터로 저장된 이미지와 비교하여 완전히 새롭고 뚜렷한 이미지를 갖도록하기 위해 만들어졌습니다. 또한이 패션은 이미 CIFAR-10 데이터 세트에 의해 원래 이미지 배열의 직렬화 된 버전을 나타내는 열차 및 테스트 배치로 수행됩니다.
아래의 Picutre는 임베딩을 Pinecone 지수에 저장하는 전체 과정을 설명합니다. 이미지를 읽는 첫 번째 단계에서 미리 훈련 된 VGG16 신경망을 적용하여 512 차원 삽입물을 생성 한 다음, 파인 콘 인덱스에 화려합니다 (즉, 저장). 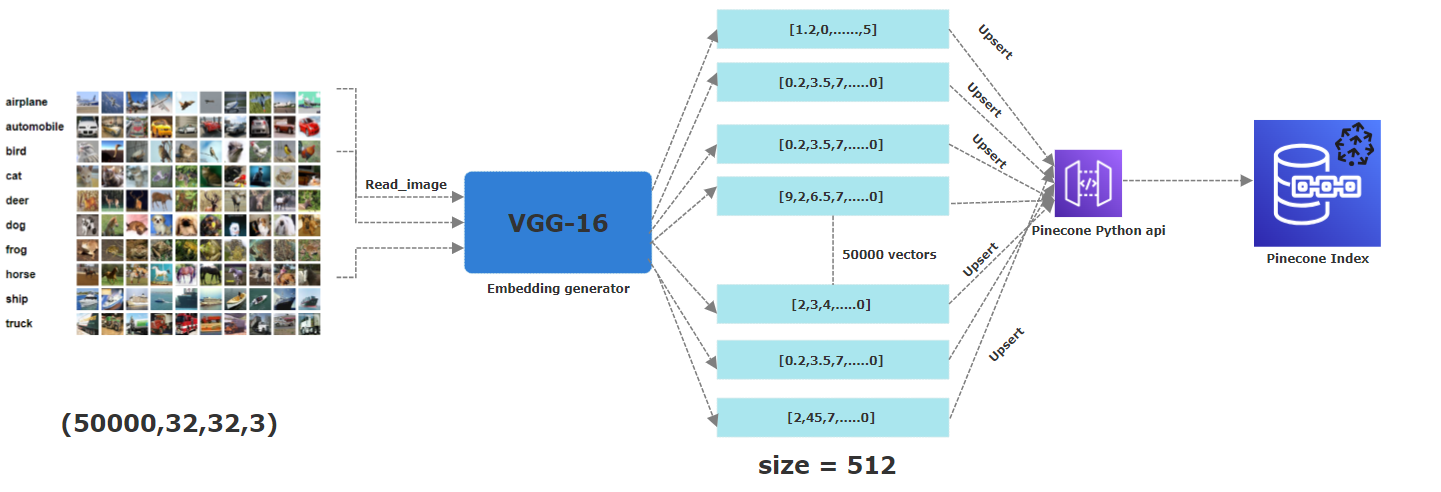
이 프로젝트에서는 5 만 개의 이미지를 처리하고 있습니다.이 이미지는 특히 이미지를 읽을 때 컴파일 할 때 컴파일 측면에서 몇 가지 과제를 제기하고 있습니다 (CIFAR-10 데이터 세트 직렬화 된 버전을 다운로드했습니다). CNN을 통해 기능을 추출합니다. 우리는 코드를 실행할 때 앵무새 컴퓨팅의 힘을 활용하려고 노력하여 멀티 스레딩을 통해 여러 CPU 코어에서 가능한 한 빨리 실행되도록했습니다.
참고 : 가능하면 더 빠른 계산을 위해 GPU 전원 환경 에서이 프로젝트를 실행하십시오.
여기에서 무료로 Pinecone 계정을 만듭니다.
Pinecone 계정과 관련된 API 키 및 환경을 얻으십시오.
이 repo를 복제하십시오 (이 튜토리얼 참조).
프로젝트 폴더에서 가상 환경을 만듭니다 (이 자습서를 참조하십시오).
필요한 패키지를 설치하려면 다음 명령을 실행하십시오.
pip3 install -r requirements.txt
pip install -r requirements.txt
python insert_data.py -key <API_KEY> -env <ENV> -metric <METRIC>
<ENV> 및 <API_KEY>를 PENECONE 계정에서 얻은 값으로 바꾸십시오. 스크립트가 완료 될 때까지 기다리십시오. 7. 다음을 사용하여 앱을 시작하십시오.
streamlit run app.py -- -key <API_KEY> -env <ENV>
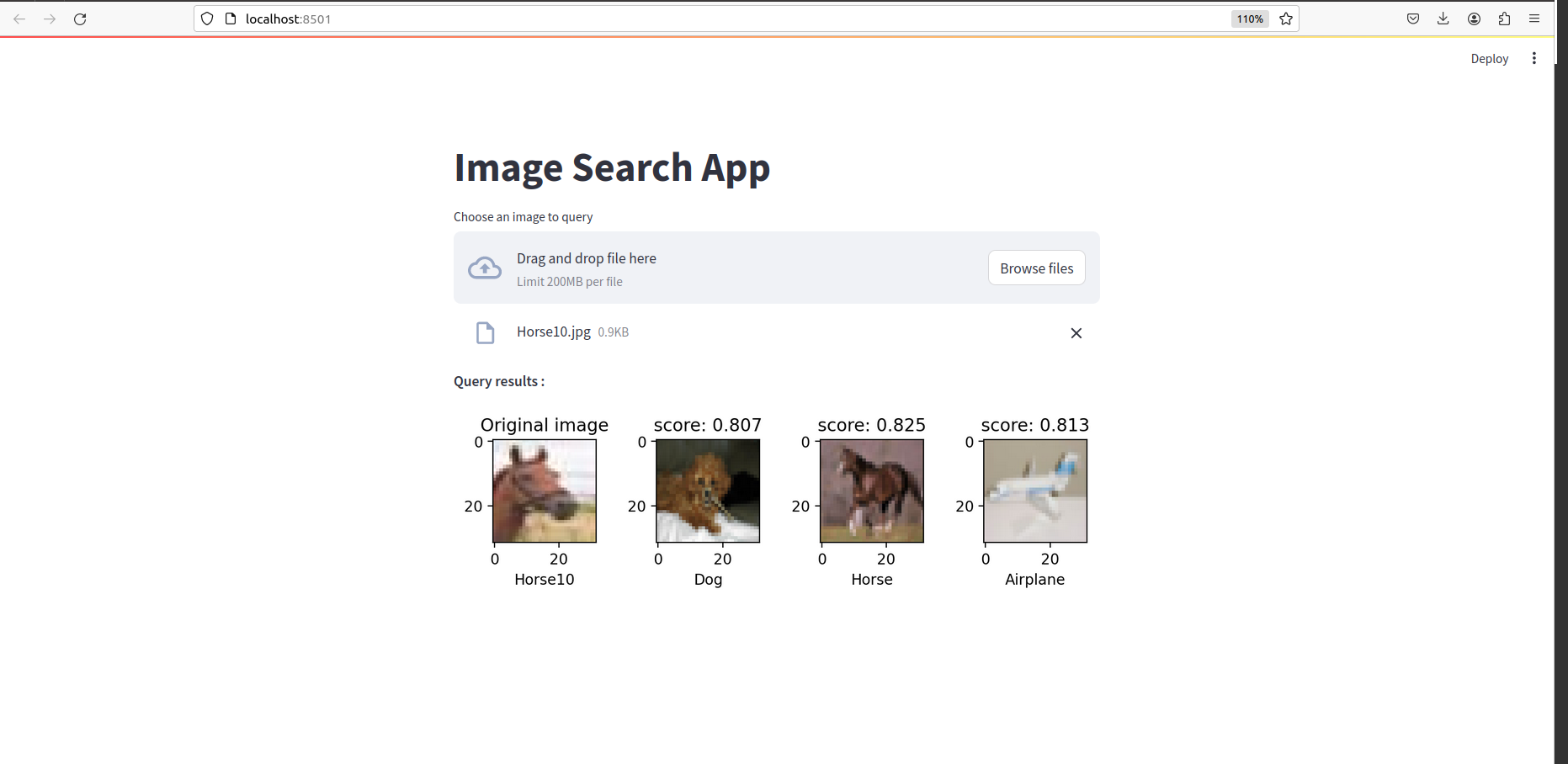
모든 것이 완료되면 다음과 같은 것을 볼 수 있습니다.