ScholarSense
v0.1.0-alpha

學者是一種工具,可幫助您根據自己的興趣找到相關論文來閱讀。它允許您使用查詢搜索論文。它使用語言模型將論文的信息(標題,摘要等)嵌入矢量空間中。然後,它將論文的嵌入在矢量數據庫中(內存或QDRANT)中索引。從本文中,它使用查詢來搜索數據庫中最相關的論文。
要在本地運行學者,您需要使用詩Python軟件包管理器安裝虛擬環境以及所有依賴項。
poetry install
要激活虛擬環境,您可以運行以下命令:
poetry shell
要驗證虛擬環境已激活,您可以導入包並打印版本:
python -c "import scholarsense; print(scholarsense.__version__)"
安裝軟件包後,您可能需要創建文件夾的結構。您可以通過運行以下命令來做到這一點:
./bash/create_dirs.sh
它創建以下結構:
.
├── artifacts
│ ├── data
│ │ ├── csv
│ │ ├── json
| └── embeddings
然後,您需要創建一個配置文件。您可以將config.yaml文件用作模板。您可以更改要搜索的關鍵字。
該工具可以通過兩種方式使用:
您可以直接從命令行運行腳本。例如,要從Arxiv刮下紙,您可以運行以下命令:
python scripts/run_scraping.py --config ./config/config.yaml --output_path ./artifacts/data/json --max_results 1000000
您也可以在Bash文件夾中使用BASH腳本。例如,要從Arxiv刮下紙,您可以運行以下命令:
./bash/scrap.sh
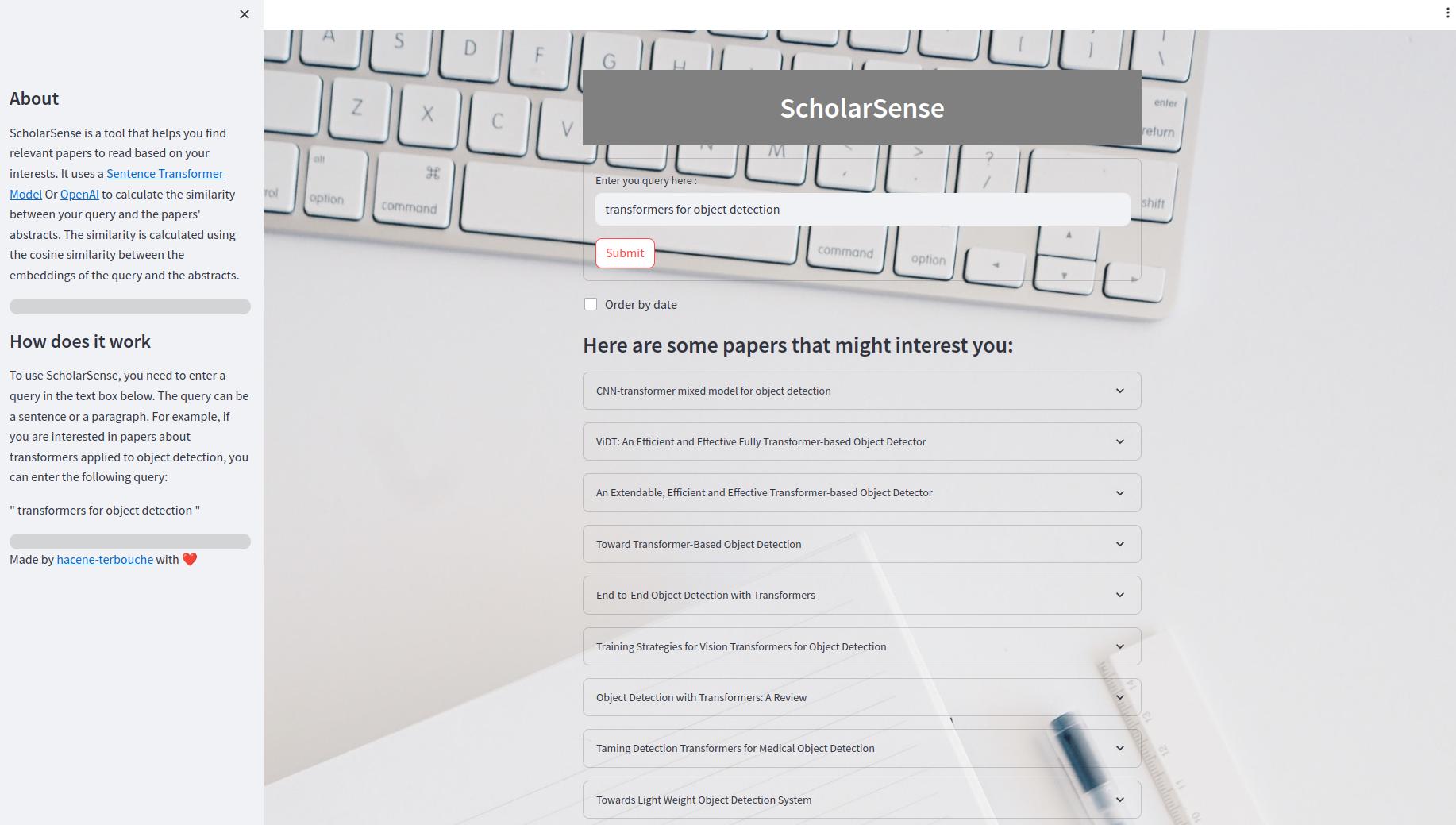
簡化應用程序是一個Web應用程序,可讓您使用查詢搜索論文。在UI內部,您可以在文本框中輸入查詢,然後單擊“提交”按鈕以獲取結果。您還可以按日期訂購結果。結果顯示為可擴展的論文列表。每篇論文都有一個標題,一個摘要和指向PDF文件的鏈接。
此存儲庫建議將三個後端用於簡化應用程序: 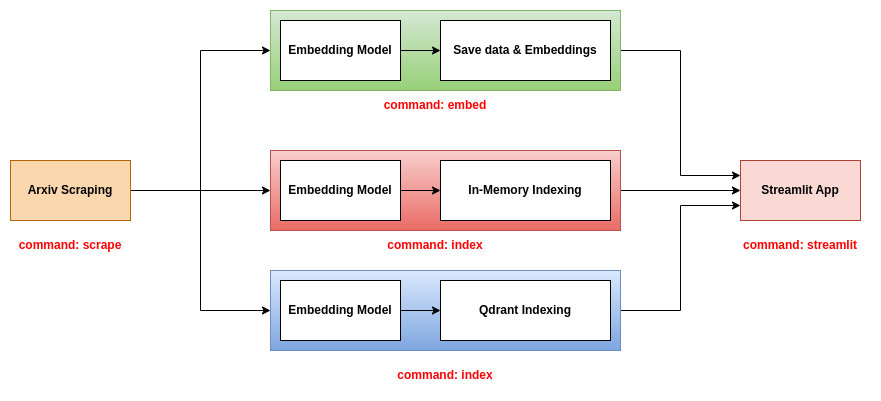
這個後端是最簡單的。它使用包含論文信息的CSV文件和包含論文嵌入的泡菜文件。 CSV文件包含以下列:
title :論文的標題。abstract :論文的摘要。pdf_url :PDF文件的URL。id :紙的ID。泡菜文件包含一個形狀的數組(n,d),其中n是紙張的數量,d是嵌入的尺寸。
要使用此後端,您應該使用三個命令scrape , embed和streamlit 。有關這些命令的更多信息,請參閱CLI工具部分。
此後端使用包含論文信息和索引論文和嵌入在內存數據庫中的JSON文件。該索引被保存為.bin文件。要使用此後端,您應該使用三個命令scrape , index和streamlit 。有關這些命令的更多信息,請參閱CLI工具部分。
此後端使用QDRANT數據庫中的論文和嵌入式的JSON文件,其中包含論文的信息和索引。要使用此後端,您應該使用三個命令scrape , index和streamlit 。有關這些命令的更多信息,請參閱CLI工具部分。
要運行QDrant服務器,您可以運行以下命令:
docker-compose up -d
使用學者的最簡單方法是使用CLI工具。您可以運行以下命令以獲取幫助消息:
scholarsense --help
CLI工具具有FOOR命令:
scrape :從Arxiv的刮紙紙embed :使用句子變壓器模型嵌入論文或打開AI模型index :使用A矢量數據庫嵌入和索引論文(內存或QDRANT)streamlit :運行精簡應用並蒐索論文要從Arxiv刮下紙,您可以運行以下命令:
scholarsense scrape --help
該命令採用以下參數:
config :YAML配置文件的路徑,其中包含要搜索的關鍵字。output_path :輸出文件的路徑,其中論文將作為JSON文件保存。max_results :每個關鍵字要刮擦的最大紙張數,默認值為1000000。 此命令用於使用句子變壓器模型或打開AI模型嵌入論文。然後,它將嵌入式保存在泡菜文件中。要嵌入論文,您可以運行以下命令:
scholarsense embed --help
該命令採用以下參數:
input_path :包含論文的JSON文件的路徑。output_path :輸出文件的路徑,其中論文將作為泡菜文件保存。csv_file_path :通往CSV文件的路徑,將保存PEPERS的信息。model_type :要使用的模型的類型,無論是sentence-transformers還是openai ,默認值是sentence-transformers 。model_name :使用所選類型的模型名稱,默認值為all-MiniLM-L6-v2 。encoding_method :使用{標題,摘要,cont等}的編碼方法的類型,默認為title 。 此命令用於使用A Vector數據庫(內存或QDRANT)嵌入和索引論文。要嵌入和索引論文,您可以運行以下命令:
scholarsense index --help
該命令採用以下參數:
db_path :包含論文的JSON文件的路徑。model_type :要使用的模型的類型,無論是sentence-transformers還是openai ,默認值是sentence-transformers 。model_name :使用所選類型的模型名稱,默認值為all-MiniLM-L6-v2 。encoding_method :使用{標題,摘要,cont等}的編碼方法的類型,默認為title 。indexing_method :用於索引論文的方法,無論是in-memory或qdrant ,默認值是in-memory 。host :QDRANT服務器的主機,默認值無。port :QDRANT服務器的端口,默認值無。collection_name :用於QDRANT中的集合的名稱,默認值無。index_file_path :保存為.bin文件的索引文件的路徑用於內存索引,默認值無。 此命令用於運行簡化應用程序並蒐索論文。要運行簡化應用程序,您可以運行以下命令:
scholarsense streamlit --help
該命令採用以下參數:
backend :使用simple , in-memory或qdrant後端。model_type :要使用的模型類型,無論是sentence-transformers還是openai 。model_name :使用所選類型的模型名稱。encoding_method :使用{標題,抽象,concat等}的編碼方法的類型。limit :要顯示的最大論文數量。collection_name :用於QDRANT的集合的名稱。csv_file_path :CSV文件中包含論文信息的路徑,如果您使用簡單的後端,則很有用。embedding_file_path :包含嵌入式的泡菜文件的路徑,如果您使用簡單的後端,則很有用。index_file_path :保存為.bin文件的索引文件的路徑用於內存索引,如果您使用內存中後端,則有用。

