ScholarSense
v0.1.0-alpha

Scholarsense เป็นเครื่องมือที่ช่วยให้คุณค้นหาเอกสารที่เกี่ยวข้องในการอ่านตามความสนใจของคุณ ช่วยให้คุณค้นหาเอกสารโดยใช้แบบสอบถาม มันใช้แบบจำลองภาษาเพื่อฝังข้อมูลเอกสาร (ชื่อเรื่องนามธรรม ฯลฯ ) ลงในพื้นที่เวกเตอร์ จากนั้นจะจัดทำดัชนีการฝังของเอกสารในฐานข้อมูลเวกเตอร์ (ในหน่วยความจำหรือ qdrant) ในที่สุดมันใช้แบบสอบถามเพื่อค้นหาเอกสารที่เกี่ยวข้องมากที่สุดในฐานข้อมูล
ในการเรียกใช้นักวิชาการในพื้นที่คุณต้องติดตั้งสภาพแวดล้อมเสมือนจริงรวมถึงการพึ่งพาทั้งหมดโดยใช้ Poetry Python Package Manager
poetry install
ในการเปิดใช้งานสภาพแวดล้อมเสมือนจริงคุณสามารถเรียกใช้คำสั่งต่อไปนี้:
poetry shell
ในการตรวจสอบว่าเปิดใช้งานสภาพแวดล้อมเสมือนจริงคุณสามารถนำเข้าแพ็คเกจและพิมพ์เวอร์ชัน:
python -c "import scholarsense; print(scholarsense.__version__)"
หลังจากติดตั้งแพ็คเกจคุณอาจต้องสร้างโครงสร้างของโฟลเดอร์ คุณสามารถทำได้โดยเรียกใช้คำสั่งต่อไปนี้:
./bash/create_dirs.sh
มันสร้างโครงสร้างต่อไปนี้:
.
├── artifacts
│ ├── data
│ │ ├── csv
│ │ ├── json
| └── embeddings
จากนั้นคุณต้องสร้างไฟล์กำหนดค่า คุณสามารถใช้ไฟล์ config.yaml เป็นเทมเพลต คุณสามารถเปลี่ยนคำหลักเพื่อค้นหา
เครื่องมือนี้สามารถใช้ได้สองวิธี:
คุณสามารถเรียกใช้สคริปต์โดยตรงจากบรรทัดคำสั่ง ตัวอย่างเช่นการขูดเอกสารจาก arxiv คุณสามารถเรียกใช้คำสั่งต่อไปนี้:
python scripts/run_scraping.py --config ./config/config.yaml --output_path ./artifacts/data/json --max_results 1000000
คุณยังสามารถใช้สคริปต์ Bash ในโฟลเดอร์ Bash ตัวอย่างเช่นการขูดเอกสารจาก arxiv คุณสามารถเรียกใช้คำสั่งต่อไปนี้:
./bash/scrap.sh
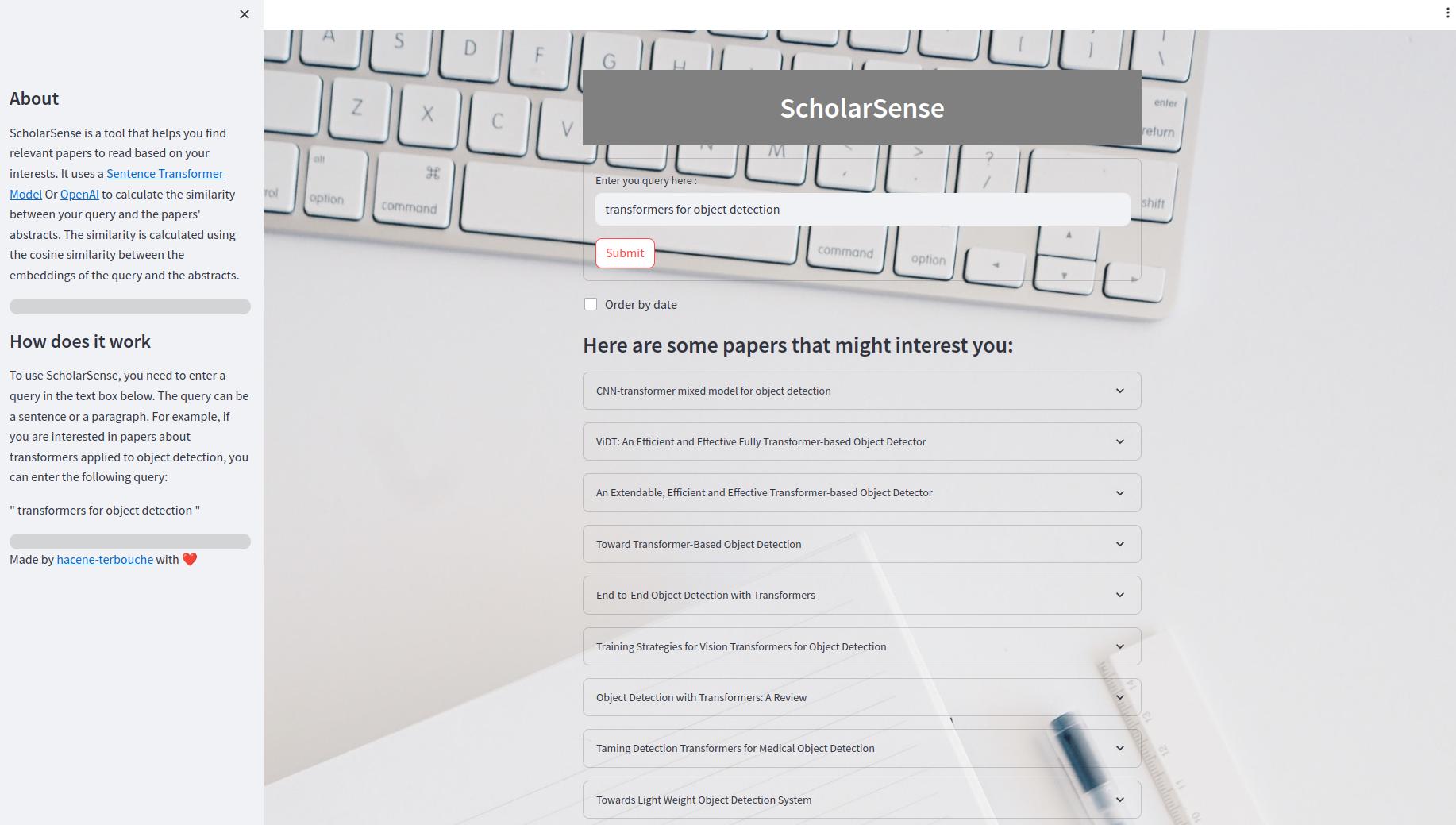
แอป StreamLit เป็นแอปเว็บที่ให้คุณค้นหาเอกสารโดยใช้แบบสอบถาม ภายใน UI คุณสามารถป้อนแบบสอบถามในกล่องข้อความและคลิกที่ปุ่ม "ส่ง" เพื่อรับผลลัพธ์ คุณยังสามารถสั่งซื้อผลลัพธ์ตามวันที่ ผลลัพธ์จะแสดงเป็นรายการเอกสารที่ขยายได้ กระดาษแต่ละเล่มมีชื่อเรื่องนามธรรมและลิงก์ไปยังไฟล์ PDF
repo นี้เสนอแบ็กเอนด์สามตัวเพื่อใช้กับแอพ Streamlit: 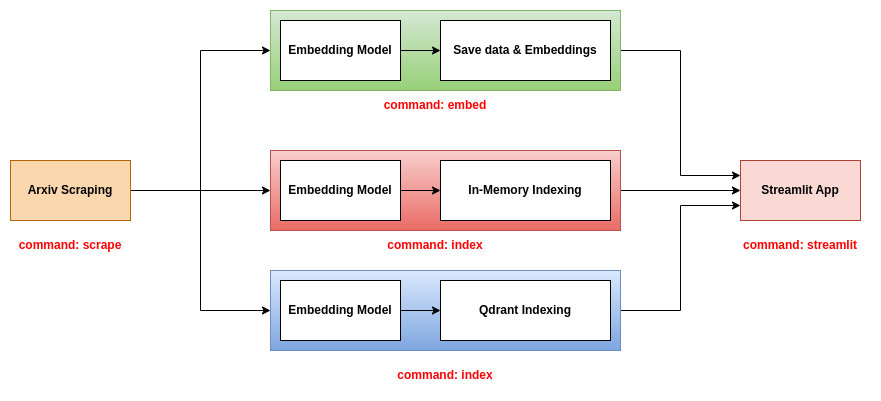
แบ็กเอนด์นี้เป็นสิ่งที่ง่ายที่สุด มันใช้ไฟล์ CSV ที่มีข้อมูลเอกสารและไฟล์ดองที่มีการฝังของเอกสาร ไฟล์ CSV มีคอลัมน์ต่อไปนี้:
title : ชื่อเรื่องของกระดาษabstract : บทคัดย่อของกระดาษpdf_url : URL ของไฟล์ PDFid : ID ของกระดาษไฟล์ดองมีอาร์เรย์ numpy ของรูปร่าง (n, d) โดยที่ n คือจำนวนเอกสารและ d คือมิติของการฝัง
ในการใช้แบ็กเอนด์นี้คุณควรใช้คำสั่งสามคำ scrape embed streamlit สำหรับข้อมูลเพิ่มเติมเกี่ยวกับคำสั่งเหล่านี้โปรดดูส่วนเครื่องมือ CLI
แบ็กเอนด์นี้ใช้ไฟล์ JSON ที่มีข้อมูลเอกสารและดัชนีทั้งเอกสารและ embeddings ในฐานข้อมูลในหน่วยความจำ ดัชนีจะถูกบันทึกเป็นไฟล์. bin ในการใช้แบ็กเอนด์นี้คุณควรใช้ scrape คำสั่งสามคำ index และ streamlit สำหรับข้อมูลเพิ่มเติมเกี่ยวกับคำสั่งเหล่านี้โปรดดูส่วนเครื่องมือ CLI
แบ็กเอนด์นี้ใช้ไฟล์ JSON ที่มีข้อมูลเอกสารและดัชนีทั้งเอกสารและ embeddings ในฐานข้อมูล QDRANT ในการใช้แบ็กเอนด์นี้คุณควรใช้ scrape คำสั่งสามคำ index และ streamlit สำหรับข้อมูลเพิ่มเติมเกี่ยวกับคำสั่งเหล่านี้โปรดดูส่วนเครื่องมือ CLI
ในการเรียกใช้เซิร์ฟเวอร์ QDRANT คุณสามารถเรียกใช้คำสั่งต่อไปนี้:
docker-compose up -d
วิธีที่ง่ายที่สุดในการใช้ Scholarsense คือการใช้เครื่องมือ CLI คุณสามารถเรียกใช้คำสั่งต่อไปนี้เพื่อรับข้อความช่วยเหลือ:
scholarsense --help
เครื่องมือ CLI มีคำสั่ง foor:
scrape : เพื่อขูดเอกสารจาก arxivembed : เพื่อฝังเอกสารโดยใช้โมเดลหม้อแปลงประโยคหรือเปิดโมเดล AIindex : เพื่อฝังและดัชนีเอกสารโดยใช้ฐานข้อมูลเวกเตอร์ (ในหน่วยความจำหรือ qdrant)streamlit : เพื่อเรียกใช้แอป Streamlit และค้นหาเอกสาร ในการขูดเอกสารจาก arxiv คุณสามารถเรียกใช้คำสั่งต่อไปนี้:
scholarsense scrape --help
คำสั่งใช้อาร์กิวเมนต์ต่อไปนี้:
config : พา ธ ไปยังไฟล์กำหนดค่า YAML ที่มีคำหลักเพื่อค้นหาoutput_path : พา ธ ไปยังไฟล์เอาต์พุตซึ่งเอกสารจะถูกบันทึกเป็นไฟล์ JSONmax_results : จำนวนสูงสุดของเอกสารที่จะขูดสำหรับแต่ละคำหลักค่าเริ่มต้นคือ 10,00000 คำสั่งนี้ใช้ในการฝังเอกสารโดยใช้โมเดลหม้อแปลงประโยคหรือเปิดโมเดล AI จากนั้นจะบันทึก embeddings ในไฟล์ดอง ในการฝังเอกสารคุณสามารถเรียกใช้คำสั่งต่อไปนี้:
scholarsense embed --help
คำสั่งใช้อาร์กิวเมนต์ต่อไปนี้:
input_path : เส้นทางไปยังไฟล์ JSON ที่มีเอกสารoutput_path : พา ธ ไปยังไฟล์เอาต์พุตซึ่งเอกสารจะถูกบันทึกเป็นไฟล์ดองcsv_file_path : เส้นทางไปยังไฟล์ CSV ซึ่งข้อมูลของ Pepers จะถูกบันทึกไว้model_type : ประเภทของโมเดลที่จะใช้ไม่ว่าจะเป็น sentence-transformers หรือ openai ค่าเริ่มต้นคือ sentence-transformersmodel_name : ชื่อของโมเดลที่จะใช้ประเภทที่เลือกค่าเริ่มต้นคือ all-MiniLM-L6-v2encoding_method : ประเภทของวิธีการเข้ารหัสเพื่อใช้ {title, abstract, concat ฯลฯ }, ค่าเริ่มต้นคือ title คำสั่งนี้ใช้ในการฝังและจัดทำดัชนีเอกสารโดยใช้ฐานข้อมูลเวกเตอร์ (ในหน่วยความจำหรือ qdrant) ในการฝังและจัดทำดัชนีเอกสารคุณสามารถเรียกใช้คำสั่งต่อไปนี้:
scholarsense index --help
คำสั่งใช้อาร์กิวเมนต์ต่อไปนี้:
db_path : เส้นทางไปยังไฟล์ JSON ที่มีเอกสารmodel_type : ประเภทของโมเดลที่จะใช้ไม่ว่าจะเป็น sentence-transformers หรือ openai ค่าเริ่มต้นคือ sentence-transformersmodel_name : ชื่อของโมเดลที่จะใช้ประเภทที่เลือกค่าเริ่มต้นคือ all-MiniLM-L6-v2encoding_method : ประเภทของวิธีการเข้ารหัสเพื่อใช้ {title, abstract, concat ฯลฯ }, ค่าเริ่มต้นคือ titleindexing_method : วิธีการใช้ในการจัดทำดัชนีเอกสารทั้ง in-memory หรือ qdrant ค่าเริ่มต้นคือ in-memoryhost : โฮสต์ของเซิร์ฟเวอร์ QDRANT ค่าเริ่มต้นคือไม่มีport : พอร์ตของเซิร์ฟเวอร์ QDDRANT ค่าเริ่มต้นคือไม่มีcollection_name : ชื่อของคอลเลกชันที่จะใช้ใน Qdrant ค่าเริ่มต้นคือไม่มีindex_file_path : พา ธ ไปยังไฟล์ดัชนีที่บันทึกเป็นไฟล์. bin สำหรับการจัดทำดัชนีในหน่วยความจำค่าเริ่มต้นคือไม่มี คำสั่งนี้ใช้เพื่อเรียกใช้แอพ streamlit และค้นหาเอกสาร ในการเรียกใช้แอพ StreamLit คุณสามารถเรียกใช้คำสั่งต่อไปนี้:
scholarsense streamlit --help
คำสั่งใช้อาร์กิวเมนต์ต่อไปนี้:
backend : แบ็กเอนด์ที่จะใช้ไม่ว่าจะ simple in-memory หรือ qdrantmodel_type : ประเภทของโมเดลที่จะใช้ไม่ว่าจะเป็น sentence-transformers หรือ openaimodel_name : ชื่อของโมเดลที่จะใช้ประเภทที่เลือกencoding_method : ประเภทของวิธีการเข้ารหัสเพื่อใช้ {title, abstract, concat ฯลฯ }limit : จำนวนเอกสารสูงสุดที่จะแสดงcollection_name : ชื่อของคอลเลกชันที่จะใช้ใน Qdrantcsv_file_path : เส้นทางไปยังไฟล์ CSV ที่มีข้อมูลของเอกสารมีประโยชน์หากคุณใช้แบ็กเอนด์แบบง่ายembedding_file_path : เส้นทางไปยังไฟล์ดองที่มีการฝังตัวมีประโยชน์หากคุณใช้แบ็กเอนด์แบบง่ายindex_file_path : พา ธ ไปยังไฟล์ดัชนีที่บันทึกเป็นไฟล์. bin สำหรับการจัดทำดัชนีในหน่วยความจำมีประโยชน์หากคุณใช้แบ็กเอนด์ในหน่วยความจำ

