ScholarSense
v0.1.0-alpha

Scholarsenseは、あなたの興味に基づいて読む関連論文を見つけるのに役立つツールです。クエリを使用して論文を検索することができます。言語モデルを使用して、論文の情報(タイトル、要約など)をベクトル空間に埋め込みます。次に、ベクトルデータベース(インメモリまたはQDRANT)に論文の埋め込みをインデックス化します。まず、クエリを使用して、データベース内の最も関連性の高い論文を検索します。
Scholarsenseをローカルで実行するには、Poetry Pythonパッケージマネージャーを使用して、仮想環境とすべての依存関係をインストールする必要があります。
poetry install
仮想環境を有効にするには、次のコマンドを実行できます。
poetry shell
仮想環境がアクティブ化されていることを確認するには、パッケージをインポートしてバージョンを印刷できます。
python -c "import scholarsense; print(scholarsense.__version__)"
パッケージをインストールした後、フォルダーの構造を作成する必要がある場合があります。次のコマンドを実行することでそれを行うことができます。
./bash/create_dirs.sh
次の構造を作成します。
.
├── artifacts
│ ├── data
│ │ ├── csv
│ │ ├── json
| └── embeddings
次に、構成ファイルを作成する必要があります。 config.yamlファイルをテンプレートとして使用できます。キーワードを変更して検索できます。
このツールは2つの方法で使用できます。
コマンドラインからスクリプトを直接実行できます。たとえば、Arxivから紙をこすります。次のコマンドを実行できます。
python scripts/run_scraping.py --config ./config/config.yaml --output_path ./artifacts/data/json --max_results 1000000
BashフォルダーでBashスクリプトを使用することもできます。たとえば、Arxivから紙をこすります。次のコマンドを実行できます。
./bash/scrap.sh
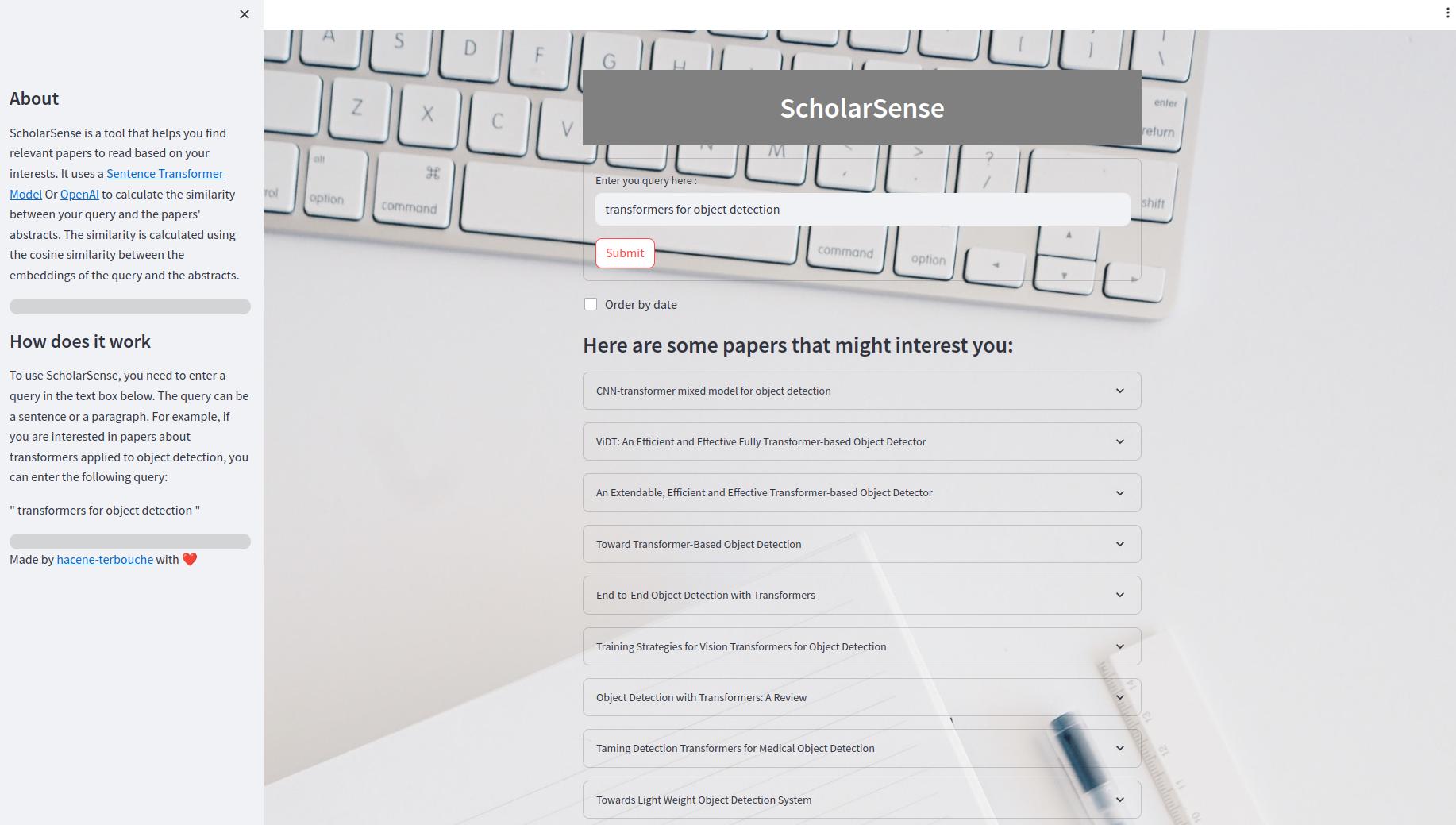
Streamlitアプリは、クエリを使用して論文を検索できるWebアプリです。 UI内では、テキストボックスにクエリを入力し、[送信]ボタンをクリックして結果を取得できます。日付で結果を注文することもできます。結果は、論文の拡張可能なリストとして表示されます。各ペーパーには、タイトル、要約、およびPDFファイルへのリンクがあります。
このリポジトリは、Resirlitアプリで使用する3つのバックエンドを提案しています。 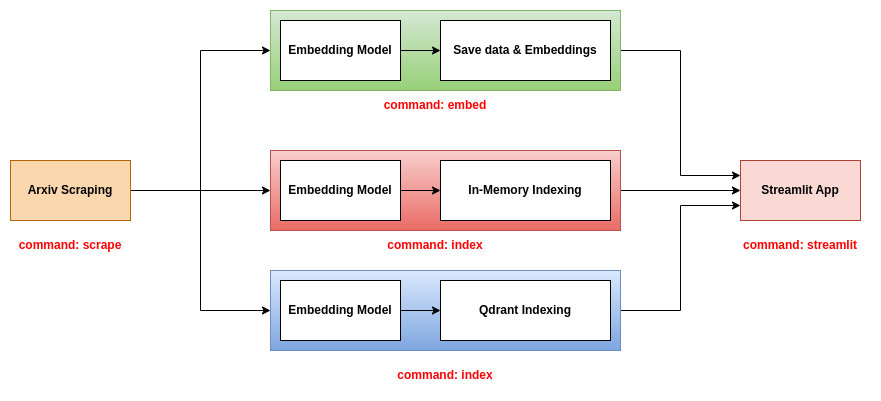
このバックエンドは最も簡単なものです。論文の情報を含むCSVファイルと、論文の埋め込みを含むピクルスファイルを使用します。 CSVファイルには、次の列が含まれています。
title :論文のタイトル。abstract :論文の要約。pdf_url :PDFファイルのURL。id :論文のID。ピクルスファイルには、形状のnumpy配列(n、d)が含まれています。ここで、nは論文の数、dは埋め込みの寸法です。
このバックエンドを使用するには、3つのコマンドのscrape 、 embed 、およびstreamlit使用する必要があります。これらのコマンドの詳細については、CLIツールセクションを参照してください。
このバックエンドでは、論文の情報を含むJSONファイルを使用し、書類と埋め込みの両方をメモリ内データベースにインデックスします。インデックスは.binファイルとして保存されます。このバックエンドを使用するには、3つのコマンドscrape 、 index 、およびstreamlit使用する必要があります。これらのコマンドの詳細については、CLIツールセクションを参照してください。
このバックエンドでは、論文の情報を含むJSONファイルを使用し、QDRANTデータベースに書類と埋め込みの両方をインデックスします。このバックエンドを使用するには、3つのコマンドscrape 、 index 、およびstreamlit使用する必要があります。これらのコマンドの詳細については、CLIツールセクションを参照してください。
QDRANTサーバーを実行するには、次のコマンドを実行できます。
docker-compose up -d
Scholarsenseを使用する最も簡単な方法は、CLIツールを使用することです。次のコマンドを実行して、ヘルプメッセージを取得できます。
scholarsense --help
CLIツールにはfoorコマンドがあります。
scrape :Arxivから紙をスクレイプするembed :文変圧器モデルまたは開くAIモデルを使用して論文を埋め込むindex :A Vectorデータベース(インメモリまたはQDRANT)を使用して論文を埋め込んでインデックス化するstreamlit :retrylidアプリを実行して論文を検索するにはArxivから紙をこすります。次のコマンドを実行できます。
scholarsense scrape --help
コマンドは次の引数を取ります。
config :検索するキーワードを含むYAML構成ファイルへのパス。output_path :出力ファイルへのパス。ここで、論文はJSONファイルとして保存されます。max_results :キーワードごとにスクレイプする論文の最大数、デフォルトは1000000です。 このコマンドは、文変換器モデルまたは開いたAIモデルを使用して論文を埋め込むために使用されます。次に、漬物ファイルに埋め込みを保存します。論文を埋め込むには、次のコマンドを実行できます。
scholarsense embed --help
コマンドは次の引数を取ります。
input_path :論文を含むJSONファイルへのパス。output_path :出力ファイルへのパス。ここで、ペーパーがピクルスファイルとして保存されます。csv_file_path :Pepersの情報が保存されるCSVファイルへのパス。model_type :使用するモデルのタイプ、 sentence-transformersまたはopenaiいずれかで、デフォルトはsentence-transformersです。model_name :選択したタイプを使用するモデルの名前、デフォルトはall-MiniLM-L6-v2です。encoding_method :{title、abstract、concatなどを使用するエンコードメソッドのタイプ、デフォルトはtitleです。 このコマンドは、A Vectorデータベース(インメモリまたはQDRANT)を使用して論文の埋め込みとインデックスを作成するために使用されます。論文を埋め込み、インデックスを作成するには、次のコマンドを実行できます。
scholarsense index --help
コマンドは次の引数を取ります。
db_path :論文を含むJSONファイルへのパス。model_type :使用するモデルのタイプ、 sentence-transformersまたはopenaiいずれかで、デフォルトはsentence-transformersです。model_name :選択したタイプを使用するモデルの名前、デフォルトはall-MiniLM-L6-v2です。encoding_method :{title、abstract、concatなどを使用するエンコードメソッドのタイプ、デフォルトはtitleです。indexing_method : in-memoryまたはqdrant論文のインデックス付けに使用する方法は、デフォルトはin-memoryです。host :QDRANTサーバーのホスト、デフォルトではありません。port :QDRANTサーバーのポート、デフォルトではありません。collection_name :qdrantで使用するコレクションの名前、デフォルトはなしです。index_file_path :インデックスファイルへのパスは、インメモリインデックスのために.binファイルとして保存されます。デフォルトはなしです。 このコマンドは、retrylidアプリを実行し、論文を検索するために使用されます。 RimeLitアプリを実行するには、次のコマンドを実行できます。
scholarsense streamlit --help
コマンドは次の引数を取ります。
backend :使用するバックエンド、 simple 、 in-memoryまたはqdrantのいずれか。model_type :使用するモデルのタイプ、 sentence-transformers 、 openaiいずれか。model_name :選択したタイプを使用するモデルの名前。encoding_method :{title、abstract、concatなどを使用するエンコードメソッドのタイプ}。limit :表示する論文の最大数。collection_name :qdrantで使用するコレクションの名前。csv_file_path :Papersの情報を含むCSVファイルへのパス。単純なバックエンドを使用している場合に役立ちます。embedding_file_path :埋め込みを含むピクルファイルへのパス。単純なバックエンドを使用している場合に役立ちます。index_file_path :インデックスファイルへのパスは、メモリ内インデックスのために.binファイルとして保存されます。

