ScholarSense
v0.1.0-alpha

Scholarsense - это инструмент, который помогает вам найти соответствующие документы для чтения в зависимости от ваших интересов. Это позволяет вам искать документы, используя запрос. Он использует языковую модель для встраивания информации о документах (заголовок, аннотация и т. Д.) В векторное пространство. Затем он индексирует встраивания документов в векторную базу данных (в памяти или Qdrant).
Чтобы запустить ученых на местном уровне, вам необходимо установить виртуальную среду, а также все зависимости, использующие поэзию Python Package Manager.
poetry install
Чтобы активировать виртуальную среду, вы можете запустить следующую команду:
poetry shell
Чтобы убедиться, что виртуальная среда активирована, вы можете импортировать пакет и распечатать версию:
python -c "import scholarsense; print(scholarsense.__version__)"
После установки пакета вам может потребоваться создать структуру папок. Вы можете сделать это, выполнив следующую команду:
./bash/create_dirs.sh
Это создает следующую структуру:
.
├── artifacts
│ ├── data
│ │ ├── csv
│ │ ├── json
| └── embeddings
Затем вам нужно создать файл конфигурации. Вы можете использовать файл config.yaml в качестве шаблона. Вы можете изменить ключевые слова для поиска.
Этот инструмент можно использовать двумя способами:
Вы можете запустить сценарии непосредственно из командной строки. Например, для сокраски из Arxiv, вы можете запустить следующую команду:
python scripts/run_scraping.py --config ./config/config.yaml --output_path ./artifacts/data/json --max_results 1000000
Вы также можете использовать сценарии Bash в папке Bash. Например, для сокраски из Arxiv, вы можете запустить следующую команду:
./bash/scrap.sh
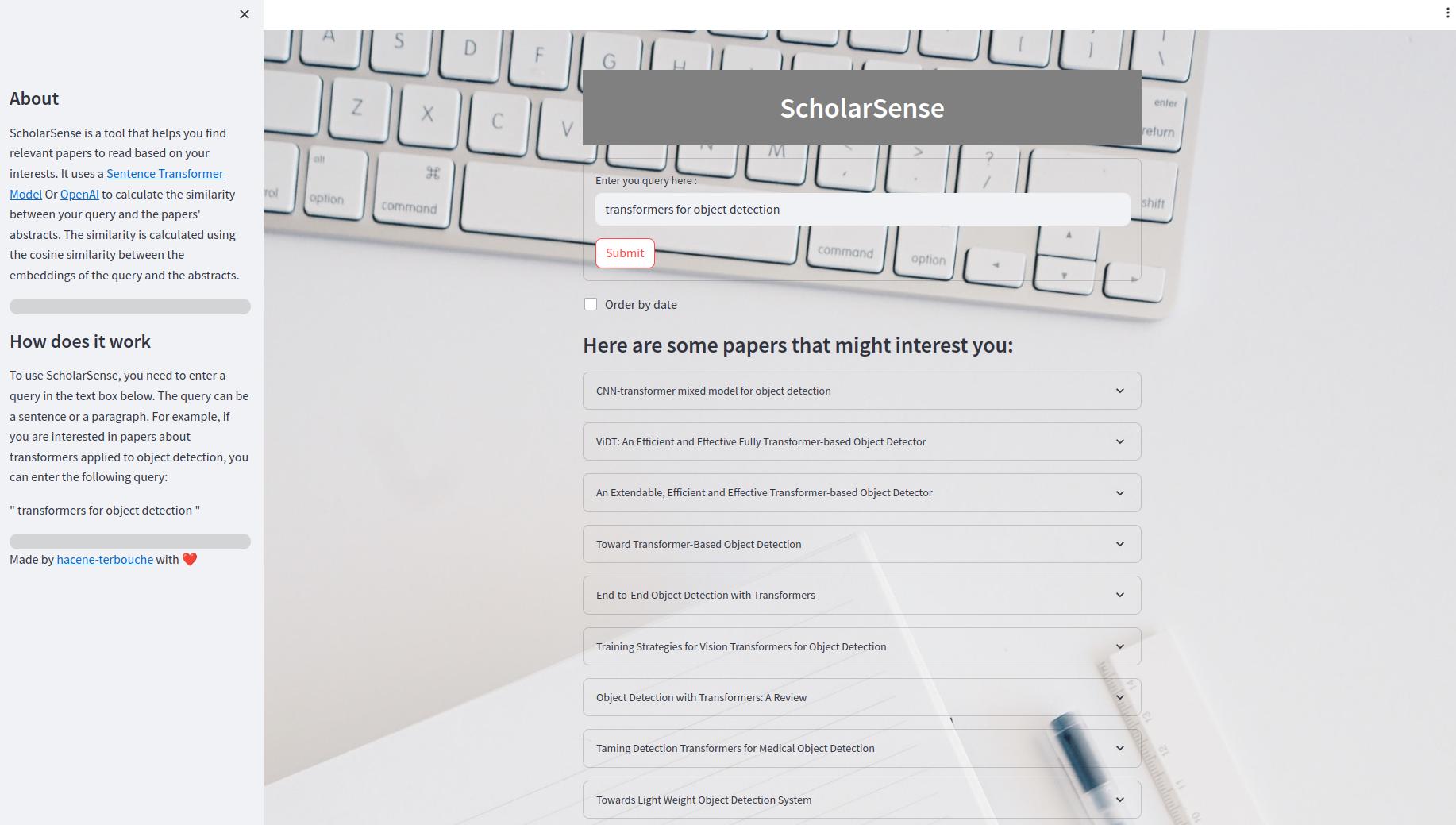
Приложение Streamlit - это веб -приложение, которое позволяет искать документы, используя запрос. Внутри пользовательского интерфейса вы можете ввести запрос в текстовом поле и нажать кнопку «Отправить», чтобы получить результаты. Вы также можете заказать результаты по дате. Результаты отображаются в виде расширяемого списка бумаг. Каждая статья имеет заголовок, абстрактный и ссылка на файл PDF.
Этот репо предлагает три бэкэнда, которые можно использовать с приложением Streamlit: 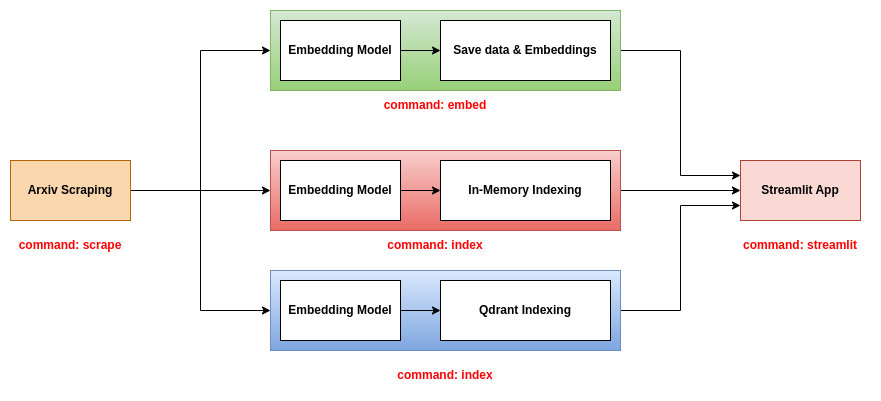
Этот бэкэнд является самым простым. Он использует файл CSV, содержащий информацию о документах, и файл маринозов, содержащий встраивание бумаг. Файл CSV содержит следующие столбцы:
title : Название бумаги.abstract : Аннотация статьи.pdf_url : URL -адрес файла PDF.id : идентификатор бумаги.Файл маринозов содержит массив формы Numpy (n, d), где n - количество бумаг, а D - размер внедрения.
Чтобы использовать этот бэкэнд, вы должны использовать три команды scrape , embed и streamlit . Для получения дополнительной информации об этих командах, пожалуйста, обратитесь к разделу инструмента CLI.
В этом бэкэнде используются файлы JSON, содержащие информацию о документах, и индекс как бумаги, так и встроения в базе данных в памяти. Индекс сохраняется как файл .bin. Чтобы использовать этот бэкэнд, вы должны использовать три команды scrape , index и streamlit . Для получения дополнительной информации об этих командах, пожалуйста, обратитесь к разделу инструмента CLI.
В этом бэкенде используются файлы JSON, содержащие информацию о документах и индекс как бумаги, так и встроенных в базу данных Qdrant. Чтобы использовать этот бэкэнд, вы должны использовать три команды scrape , index и streamlit . Для получения дополнительной информации об этих командах, пожалуйста, обратитесь к разделу инструмента CLI.
Чтобы запустить сервер Qdrant, вы можете запустить следующую команду:
docker-compose up -d
Самый простой способ использования ученых - это использовать инструмент CLI. Вы можете запустить следующую команду, чтобы получить сообщение справки:
scholarsense --help
У инструмента CLI есть команды FOOR:
scrape : чтобы соскребить бумаги из Arxivembed : встроить бумаги, используя модель трансформатора предложений или открыть модель ИИindex : встроить и индексировать документы с использованием векторной базы данных (в памяти или Qdrant)streamlit : запустить приложение Streamlit и поиск документов Чтобы очистить бумаги из Arxiv, вы можете запустить следующую команду:
scholarsense scrape --help
Команда принимает следующие аргументы:
config : Путь к файлу конфигурации YAML, содержащий ключевые слова для поиска.output_path : путь к выходному файлу, где бумаги будут сохранены как файлы JSON.max_results : максимальное количество бумаг для очистки для каждого ключевого слова по умолчанию составляет 1000000. Эта команда используется для встраивания бумаг, используя модель трансформатора предложений или открыть модель ИИ. Затем он сохраняет вторжения в маринованном файле. Чтобы встроить документы, вы можете запустить следующую команду:
scholarsense embed --help
Команда принимает следующие аргументы:
input_path : путь к файлу JSON, содержащий документы.output_path : путь к выходному файлу, где бумаги будут сохранены как файлы Pickle.csv_file_path : путь к файлу CSV, где будет сохранена информация Pepers.model_type : тип модели для использования, либо sentence-transformers , либо openai , по умолчанию sentence-transformers .model_name : Имя модели для использования выбранного типа, по умолчанию all-MiniLM-L6-v2 .encoding_method : тип метода кодирования для использования {заголовок, аннотация, concat и т. Д.}, по умолчанию является title . Эта команда используется для встраивания и индексирования бумаг с использованием векторной базы данных (в памяти или Qdrant). Чтобы встроить и индексировать бумаги, вы можете запустить следующую команду:
scholarsense index --help
Команда принимает следующие аргументы:
db_path : Путь к файлам JSON, содержащие документы.model_type : тип модели для использования, либо sentence-transformers , либо openai , по умолчанию sentence-transformers .model_name : Имя модели для использования выбранного типа, по умолчанию all-MiniLM-L6-v2 .encoding_method : тип метода кодирования для использования {заголовок, аннотация, concat и т. Д.}, по умолчанию является title .indexing_method : метод, который можно использовать для индексации бумаг, либо in-memory , либо qdrant , по умолчанию in-memory .host : хост сервера Qdrant, по умолчанию нет.port : порт сервера Qdrant, по умолчанию нет.collection_name : имя коллекции для использования в Qdrant, по умолчанию нет.index_file_path : путь к файлу индекса, сохраненный как .bin-файл для индексации в памяти, по умолчанию нет. Эта команда используется для запуска приложения Streamlit и поиска документов. Чтобы запустить приложение Streamlit, вы можете запустить следующую команду:
scholarsense streamlit --help
Команда принимает следующие аргументы:
backend : бэкэнд для использования, simple , in-memory или qdrant .model_type : тип модели для использования, либо sentence-transformers , либо openai .model_name : имя модели для использования выбранного типа.encoding_method : тип метода кодирования для использования {заголовок, аннотация, concat и т. Д.}.limit : максимальное количество бумаг для отображения.collection_name : название коллекции для использования в Qdrant.csv_file_path : путь к файлу CSV, содержащий информацию о документах, полезно, если вы используете простой бэкэнд.embedding_file_path : Путь к файлу рассола, содержащий встроенные вставки, полезный, если вы используете простой бэкэнд.index_file_path : путь к файлу индекса, сохраненный как .bin-файл для индексации в памяти, полезно, если вы используете бэкэнд в памяти.

