ScholarSense
v0.1.0-alpha

Scholararsense adalah alat yang membantu Anda menemukan makalah yang relevan untuk dibaca berdasarkan minat Anda. Ini memungkinkan Anda untuk mencari kertas menggunakan kueri. Ini menggunakan model bahasa untuk menanamkan informasi makalah (judul, abstrak, dll.) Ke dalam ruang vektor. Kemudian, ia mengindeks embedding makalah dalam database vektor (dalam memori atau qdrant). Akhirnya, ia menggunakan kueri untuk mencari makalah yang paling relevan dalam database.
Untuk menjalankan Scholararsense secara lokal, Anda perlu menginstal lingkungan virtual serta semua dependensi menggunakan puisi Python Package Manager.
poetry install
Untuk mengaktifkan lingkungan virtual, Anda dapat menjalankan perintah berikut:
poetry shell
Untuk memverifikasi bahwa lingkungan virtual diaktifkan, Anda dapat mengimpor paket dan mencetak versi:
python -c "import scholarsense; print(scholarsense.__version__)"
Setelah menginstal paket, Anda mungkin perlu membuat struktur folder. Anda dapat melakukannya dengan menjalankan perintah berikut:
./bash/create_dirs.sh
Itu menciptakan struktur berikut:
.
├── artifacts
│ ├── data
│ │ ├── csv
│ │ ├── json
| └── embeddings
Kemudian, Anda perlu membuat file konfigurasi. Anda dapat menggunakan file config.yaml sebagai templat. Anda dapat mengubah kata kunci yang harus dicari.
Alat ini dapat digunakan dalam dua cara:
Anda dapat menjalankan skrip langsung dari baris perintah. Misalnya, untuk mengikis kertas dari Arxiv, Anda dapat menjalankan perintah berikut:
python scripts/run_scraping.py --config ./config/config.yaml --output_path ./artifacts/data/json --max_results 1000000
Anda juga dapat menggunakan skrip bash di folder bash. Misalnya, untuk mengikis kertas dari Arxiv, Anda dapat menjalankan perintah berikut:
./bash/scrap.sh
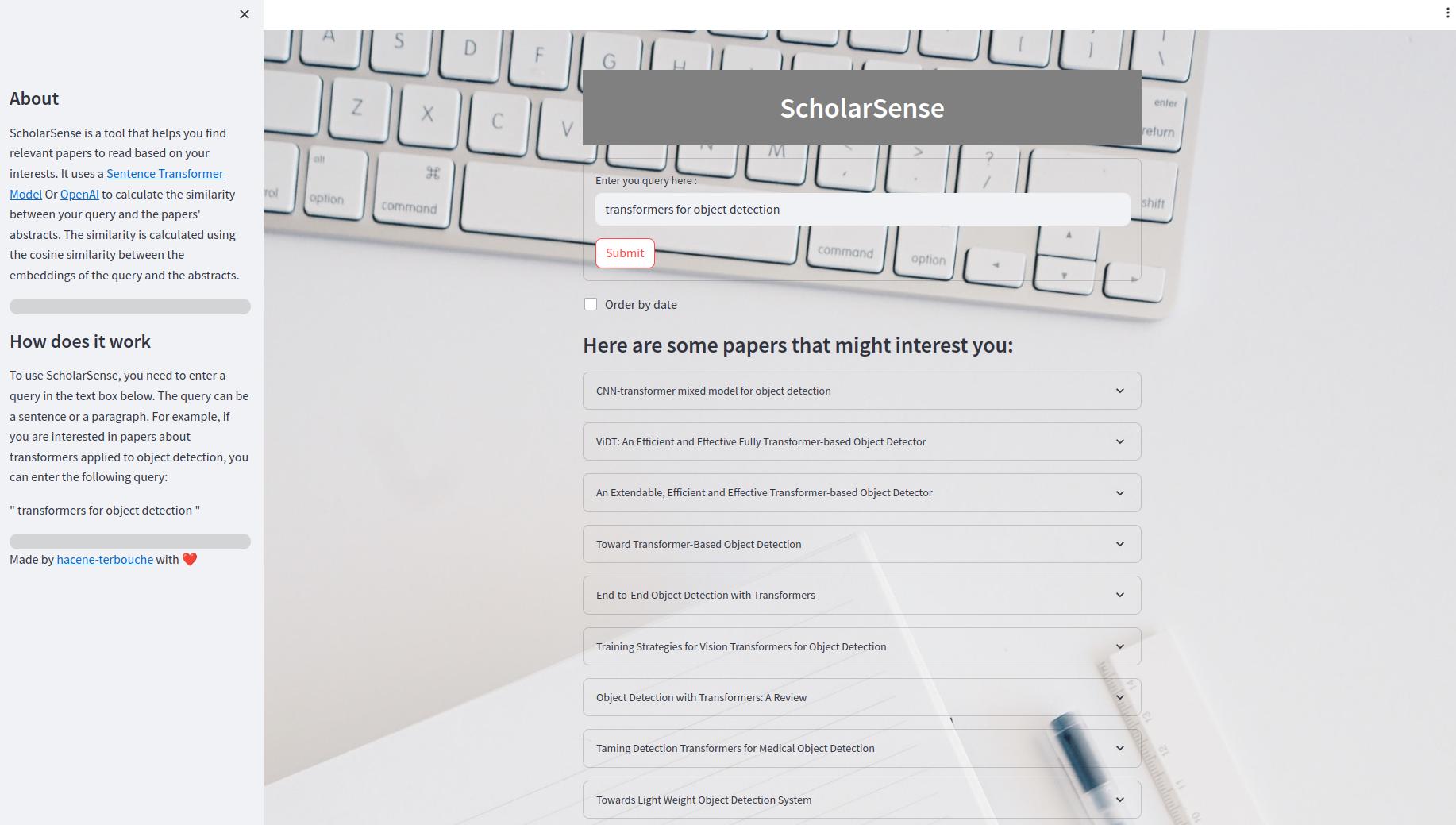
Aplikasi StreamLit adalah aplikasi web yang memungkinkan Anda mencari kertas menggunakan kueri. Di dalam UI, Anda dapat memasukkan kueri di kotak teks dan klik tombol "Kirim" untuk mendapatkan hasilnya. Anda juga dapat memesan hasil berdasarkan tanggal. Hasilnya ditampilkan sebagai daftar makalah yang dapat diperluas. Setiap kertas memiliki judul, abstrak, dan tautan ke file PDF.
Repo ini mengusulkan tiga backend untuk digunakan dengan aplikasi streamlit: 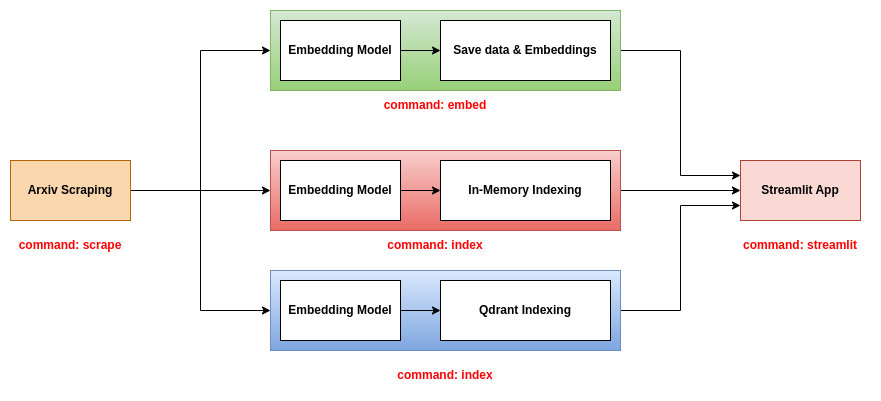
Backend ini adalah yang paling sederhana. Ini menggunakan file CSV yang berisi informasi kertas dan file acar yang berisi embeddings dari makalah. File CSV berisi kolom berikut:
title : Judul kertas.abstract : Abstrak makalah.pdf_url : URL file PDF.id : ID kertas.File acar berisi serangkaian bentuk yang tidak bagus (N, D), di mana N adalah jumlah kertas dan D adalah dimensi dari embeddings.
Untuk menggunakan backend ini, Anda harus menggunakan tiga perintah scrape , embed , dan streamlit . Untuk informasi lebih lanjut tentang perintah ini, silakan merujuk ke bagian alat CLI.
Backend ini menggunakan file JSON yang berisi informasi makalah dan mengindeks makalah dan embeddings dalam database dalam memori. Indeks disimpan sebagai file .bin. Untuk menggunakan backend ini, Anda harus menggunakan tiga perintah scrape , index , dan streamlit . Untuk informasi lebih lanjut tentang perintah ini, silakan merujuk ke bagian alat CLI.
Backend ini menggunakan file JSON yang berisi informasi makalah dan mengindeks makalah dan embeddings dalam database Qdrant. Untuk menggunakan backend ini, Anda harus menggunakan tiga perintah scrape , index , dan streamlit . Untuk informasi lebih lanjut tentang perintah ini, silakan merujuk ke bagian alat CLI.
Untuk menjalankan server Qdrant, Anda dapat menjalankan perintah berikut:
docker-compose up -d
Cara paling sederhana untuk menggunakan Scholararsense adalah dengan menggunakan alat CLI. Anda dapat menjalankan perintah berikut untuk mendapatkan pesan bantuan:
scholarsense --help
Alat CLI memiliki perintah foor:
scrape : Mengikis kertas dari arxivembed : Untuk menanamkan kertas menggunakan model transformator kalimat atau model AI terbukaindex : Untuk menanamkan dan mengindeks kertas menggunakan database vektor (dalam memori atau qdrant)streamlit : Untuk menjalankan aplikasi streamlit dan mencari makalah Untuk mengikis kertas dari Arxiv, Anda dapat menjalankan perintah berikut:
scholarsense scrape --help
Perintah mengambil argumen berikut:
config : Jalur ke file konfigurasi YAML, berisi kata kunci yang harus dicari.output_path : Jalur ke file output, di mana kertas akan disimpan sebagai file JSON.max_results : Jumlah maksimum makalah untuk mengikis untuk setiap kata kunci, default adalah 1000000. Perintah ini digunakan untuk menanamkan kertas menggunakan model transformator kalimat atau model AI terbuka. Kemudian menyimpan embeddings dalam file acar. Untuk menyematkan kertas, Anda dapat menjalankan perintah berikut:
scholarsense embed --help
Perintah mengambil argumen berikut:
input_path : Path ke file JSON yang berisi kertas.output_path : Jalur ke file output, di mana kertas akan disimpan sebagai file acar.csv_file_path : Jalur ke file CSV, di mana informasi Pepers akan disimpan.model_type : Jenis model yang akan digunakan, baik sentence-transformers atau openai , default adalah sentence-transformers .model_name : Nama model yang akan digunakan jenis yang dipilih, default adalah all-MiniLM-L6-v2 .encoding_method : Jenis metode pengkodean untuk menggunakan {title, abstrak, concat, dll.}, default adalah title . Perintah ini digunakan untuk menanamkan dan mengindeks kertas menggunakan database vektor (dalam memori atau qdrant). Untuk menyematkan dan mengindeks kertas, Anda dapat menjalankan perintah berikut:
scholarsense index --help
Perintah mengambil argumen berikut:
db_path : Jalur ke file JSON yang berisi kertas.model_type : Jenis model yang akan digunakan, baik sentence-transformers atau openai , default adalah sentence-transformers .model_name : Nama model yang akan digunakan jenis yang dipilih, default adalah all-MiniLM-L6-v2 .encoding_method : Jenis metode pengkodean untuk menggunakan {title, abstrak, concat, dll.}, default adalah title .indexing_method : Metode untuk digunakan untuk mengindeks kertas, baik in-memory atau qdrant , default adalah in-memory .host : Host dari server Qdrant, default tidak ada.port : Port dari server Qdrant, default tidak ada.collection_name : Nama koleksi yang akan digunakan di Qdrant, default tidak ada.index_file_path : Jalur ke file indeks yang disimpan sebagai file .bin untuk pengindeksan dalam memori, default tidak ada. Perintah ini digunakan untuk menjalankan aplikasi streamLit dan mencari makalah. Untuk menjalankan aplikasi StreamLit, Anda dapat menjalankan perintah berikut:
scholarsense streamlit --help
Perintah mengambil argumen berikut:
backend : Backend untuk digunakan, baik simple , in-memory atau qdrant .model_type : Jenis model yang akan digunakan, baik sentence-transformers atau openai .model_name : Nama model yang akan digunakan jenis yang dipilih.encoding_method : Jenis metode pengkodean untuk menggunakan {title, abstrak, concat, dll.}.limit : Jumlah maksimum kertas untuk ditampilkan.collection_name : Nama koleksi yang akan digunakan di Qdrant.csv_file_path : Jalur ke file CSV yang berisi informasi makalah, berguna jika Anda menggunakan backend sederhana.embedding_file_path : Jalur ke file acar yang berisi embeddings, berguna jika Anda menggunakan backend sederhana.index_file_path : Jalur ke file indeks disimpan sebagai file .bin untuk pengindeksan dalam memori, berguna jika Anda menggunakan backend dalam memori.

