ScholarSense
v0.1.0-alpha

Scholarsense는 귀하의 관심사에 따라 읽을 관련 논문을 찾는 데 도움이되는 도구입니다. 쿼리를 사용하여 논문을 검색 할 수 있습니다. 언어 모델을 사용하여 논문의 정보 (제목, 초록 등)를 벡터 공간에 포함시킵니다. 그런 다음 벡터 데이터베이스 (Memory 또는 Qdrant)에 논문의 임베딩을 색인화합니다. 쿼리를 사용하여 데이터베이스에서 가장 관련성이 높은 논문을 검색합니다.
Scholarsense를 로컬로 실행하려면 Poetry Python 패키지 관리자를 사용하여 모든 의존성뿐만 아니라 가상 환경을 설치해야합니다.
poetry install
가상 환경을 활성화하려면 다음 명령을 실행할 수 있습니다.
poetry shell
가상 환경이 활성화되어 있는지 확인하려면 패키지를 가져와 버전을 인쇄 할 수 있습니다.
python -c "import scholarsense; print(scholarsense.__version__)"
패키지를 설치 한 후 폴더의 구조를 만들어야 할 수도 있습니다. 다음 명령을 실행하여 수행 할 수 있습니다.
./bash/create_dirs.sh
다음 구조를 만듭니다.
.
├── artifacts
│ ├── data
│ │ ├── csv
│ │ ├── json
| └── embeddings
그런 다음 구성 파일을 만들어야합니다. config.yaml 파일을 템플릿으로 사용할 수 있습니다. 검색 할 키워드를 변경할 수 있습니다.
이 도구는 두 가지 방법으로 사용할 수 있습니다.
명령 줄에서 직접 스크립트를 실행할 수 있습니다. 예를 들어, Arxiv에서 논문을 긁어 내려면 다음 명령을 실행할 수 있습니다.
python scripts/run_scraping.py --config ./config/config.yaml --output_path ./artifacts/data/json --max_results 1000000
Bash 폴더에서 Bash 스크립트를 사용할 수도 있습니다. 예를 들어, Arxiv에서 논문을 긁어 내려면 다음 명령을 실행할 수 있습니다.
./bash/scrap.sh
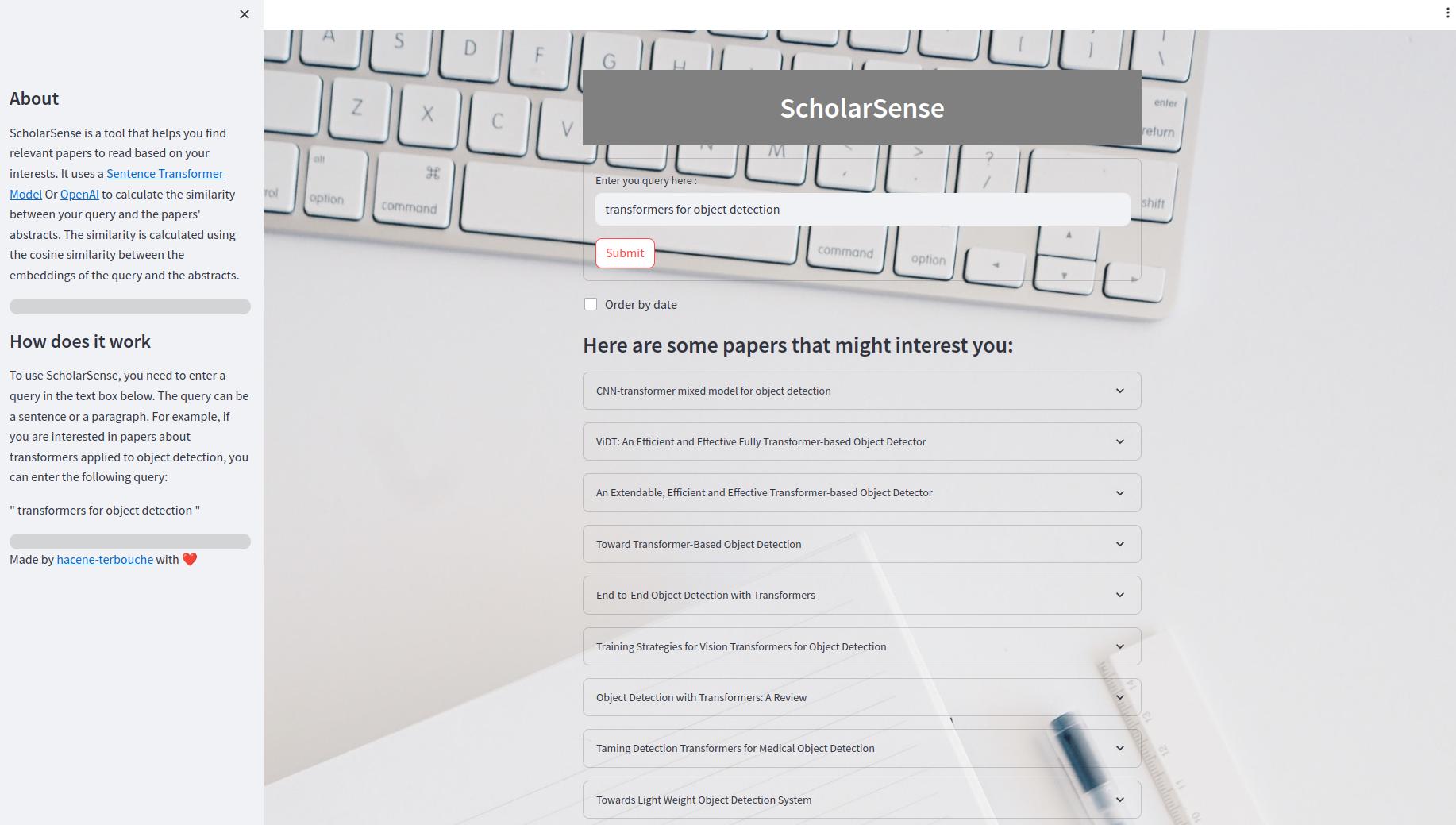
Streamlit 앱은 쿼리를 사용하여 논문을 검색 할 수있는 웹 앱입니다. UI 내부에는 텍스트 상자에 쿼리를 입력하고 "제출"버튼을 클릭하여 결과를 얻을 수 있습니다. 날짜별로 결과를 주문할 수도 있습니다. 결과는 확장 가능한 용지 목록으로 표시됩니다. 각 논문에는 제목, 초록 및 PDF 파일 링크가 있습니다.
이 repo는 Streamlit 앱과 함께 사용할 세 가지 백엔드를 제안합니다. 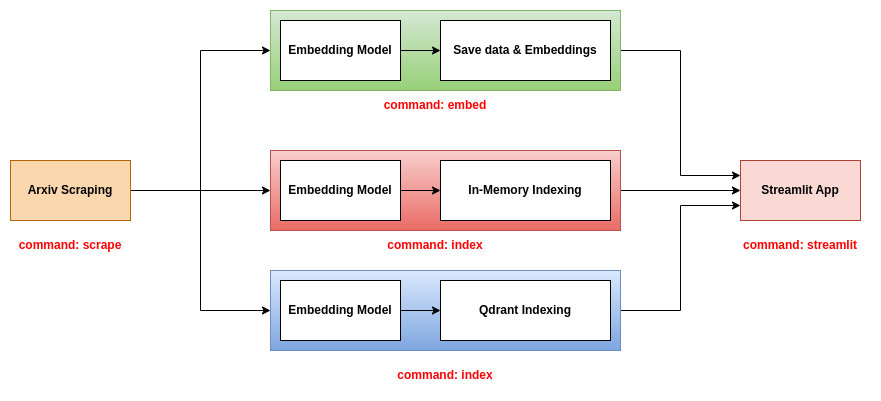
이 백엔드는 가장 간단한 백엔드입니다. 논문 정보가 포함 된 CSV 파일과 논문의 임베딩이 포함 된 피클 파일을 사용합니다. CSV 파일에는 다음 열이 포함되어 있습니다.
title : 종이 제목.abstract : 논문의 초록.pdf_url : PDF 파일의 URL.id : 종이의 ID.피클 파일에는 Numpy Shape 배열 (n, d)이 포함되어 있으며, 여기서 n은 종이 수이고 d는 임베딩의 치수입니다.
이 백엔드를 사용하려면 세 가지 명령을 사용하여 scrape , embed 및 streamlit 사용해야합니다. 이 명령에 대한 자세한 내용은 CLI 도구 섹션을 참조하십시오.
이 백엔드는 논문의 정보가 포함 된 JSON 파일을 사용하고 메모리 내 데이터베이스에 종이와 임베딩을 모두 색인합니다. 인덱스는 .bin 파일로 저장됩니다. 이 백엔드를 사용하려면 세 가지 명령 scrape , index 및 streamlit 사용해야합니다. 이 명령에 대한 자세한 내용은 CLI 도구 섹션을 참조하십시오.
이 백엔드는 논문 정보가 포함 된 JSON 파일을 사용하고 QDRANT 데이터베이스에 종이와 임베딩을 모두 색인합니다. 이 백엔드를 사용하려면 세 가지 명령 scrape , index 및 streamlit 사용해야합니다. 이 명령에 대한 자세한 내용은 CLI 도구 섹션을 참조하십시오.
Qdrant 서버를 실행하려면 다음 명령을 실행할 수 있습니다.
docker-compose up -d
Scholarsense를 사용하는 가장 간단한 방법은 CLI 도구를 사용하는 것입니다. 다음 명령을 실행하여 도움말 메시지를받을 수 있습니다.
scholarsense --help
CLI 도구에는 다음과 같은 명령이 있습니다.
scrape : Arxiv에서 종이를 긁어 내기 위해embed : 문장 변압기 모델 또는 열린 AI 모델을 사용하여 논문을 포함하려면index : A 벡터 데이터베이스 (Memory 또는 Qdrant)를 사용하여 용지를 포함시키고 색인하십시오.streamlit : 간소화 앱을 실행하고 논문 검색 Arxiv에서 논문을 긁어 내려면 다음 명령을 실행할 수 있습니다.
scholarsense scrape --help
명령은 다음과 같은 주장을합니다.
config : 검색 할 키워드가 포함 된 Yaml 구성 파일의 경로.output_path : 종이가 JSON 파일로 저장되는 출력 파일의 경로.max_results : 각 키워드에 대해 긁을 최대 용지 수는 기본값은 1000000입니다. 이 명령은 문장 변압기 모델 또는 열린 AI 모델을 사용하여 논문을 포함시키는 데 사용됩니다. 그런 다음 임베딩을 피클 파일로 저장합니다. 논문을 포함 시키려면 다음 명령을 실행할 수 있습니다.
scholarsense embed --help
명령은 다음과 같은 주장을합니다.
input_path : 용지가 포함 된 JSON 파일의 경로.output_path : 종이가 피클 파일로 저장되는 출력 파일의 경로.csv_file_path : Pepers의 정보가 저장되는 CSV 파일로가는 경로.model_type : sentence-transformers 또는 openai 사용할 모델의 유형은 기본값이 sentence-transformers 입니다.model_name : 선택한 유형의 사용에 대한 모델 이름, 기본값은 all-MiniLM-L6-v2 입니다.encoding_method : {title, actract, concat 등을 사용하는 인코딩 메소드 유형}, 기본값은 title 입니다. 이 명령은 A 벡터 데이터베이스 (Memory 또는 Qdrant)를 사용하여 용지를 포함시키고 색인하는 데 사용됩니다. 논문을 포함시키고 색인하려면 다음 명령을 실행할 수 있습니다.
scholarsense index --help
명령은 다음과 같은 주장을합니다.
db_path : 논문이 포함 된 JSON 파일의 경로.model_type : sentence-transformers 또는 openai 사용할 모델의 유형은 기본값이 sentence-transformers 입니다.model_name : 선택한 유형의 사용에 대한 모델 이름, 기본값은 all-MiniLM-L6-v2 입니다.encoding_method : {title, actract, concat 등을 사용하는 인코딩 메소드 유형}, 기본값은 title 입니다.indexing_method : in-memory 또는 qdrant 의 용지를 색인화하는 데 사용하는 방법은 기본값이 in-memory 입니다.host : Qdrant 서버의 호스트, 기본값은 없음.port : QDRANT 서버의 포트는 기본값이 없습니다.collection_name : Qdrant에서 사용할 컬렉션의 이름은 기본값이 없습니다.index_file_path : 인덱스 파일로 저장된 경로는 메모리 인덱싱을위한 .bin 파일로, 기본값은 없음. 이 명령은 Streamlit 앱을 실행하고 논문을 검색하는 데 사용됩니다. Streamlit 앱을 실행하려면 다음 명령을 실행할 수 있습니다.
scholarsense streamlit --help
명령은 다음과 같은 주장을합니다.
backend : simple , in-memory 또는 qdrant 사용할 백엔드.model_type : sentence-transformers 또는 openai 사용할 모델의 유형.model_name : 선택한 유형의 사용 모델 이름.encoding_method : {제목, 초록, 콘트 등을 사용할 인코딩 메소드 유형}.limit : 표시 할 최대 용지 수입니다.collection_name : Qdrant에서 사용할 컬렉션의 이름입니다.csv_file_path : 종이 정보가 포함 된 CSV 파일의 경로로 간단한 백엔드를 사용하는 경우 유용합니다.embedding_file_path : Embedding이 포함 된 피클 파일의 경로, 간단한 백엔드를 사용하는 경우 유용합니다.index_file_path : 메모리 인덱싱을위한 .bin 파일로 저장된 인덱스 파일의 경로는 메모리 백엔드를 사용하는 경우 유용합니다.

