ScholarSense
v0.1.0-alpha

Wissenschaftler ist ein Tool, mit dem Sie relevante Papiere finden können, die auf Ihren Interessen gelesen werden können. Sie können mit einer Abfrage nach Papieren suchen. Es verwendet ein Sprachmodell, um die Informationen der Artikel (Titel, Abstrakte usw.) in einen Vektorraum einzubetten. Anschließend indiziert es die Einbettungen der Papiere in einer Vektor-Datenbank (In-Memory oder QDRant).
Um Wissenschaftler lokal auszuführen, müssen Sie die virtuelle Umgebung sowie alle Abhängigkeiten mithilfe von Poesie Python Paket Manager installieren.
poetry install
Um die virtuelle Umgebung zu aktivieren, können Sie den folgenden Befehl ausführen:
poetry shell
Um zu überprüfen, ob die virtuelle Umgebung aktiviert ist, können Sie das Paket importieren und die Version drucken:
python -c "import scholarsense; print(scholarsense.__version__)"
Nach der Installation des Pakets müssen Sie möglicherweise die Struktur der Ordner erstellen. Sie können dies tun, indem Sie den folgenden Befehl ausführen:
./bash/create_dirs.sh
Es schafft die folgende Struktur:
.
├── artifacts
│ ├── data
│ │ ├── csv
│ │ ├── json
| └── embeddings
Anschließend müssen Sie eine Konfigurationsdatei erstellen. Sie können die Datei config.yaml als Vorlage verwenden. Sie können die Schlüsselwörter ändern, nach denen Sie suchen können.
Dieses Tool kann auf zwei Arten verwendet werden:
Sie können die Skripte direkt aus der Befehlszeile ausführen. Zum Beispiel können Sie den folgenden Befehl ausführen, um Papiere von Arxiv auszuführen:
python scripts/run_scraping.py --config ./config/config.yaml --output_path ./artifacts/data/json --max_results 1000000
Sie können auch die Bash -Skripte im Bash -Ordner verwenden. Zum Beispiel können Sie den folgenden Befehl ausführen, um Papiere von Arxiv auszuführen:
./bash/scrap.sh
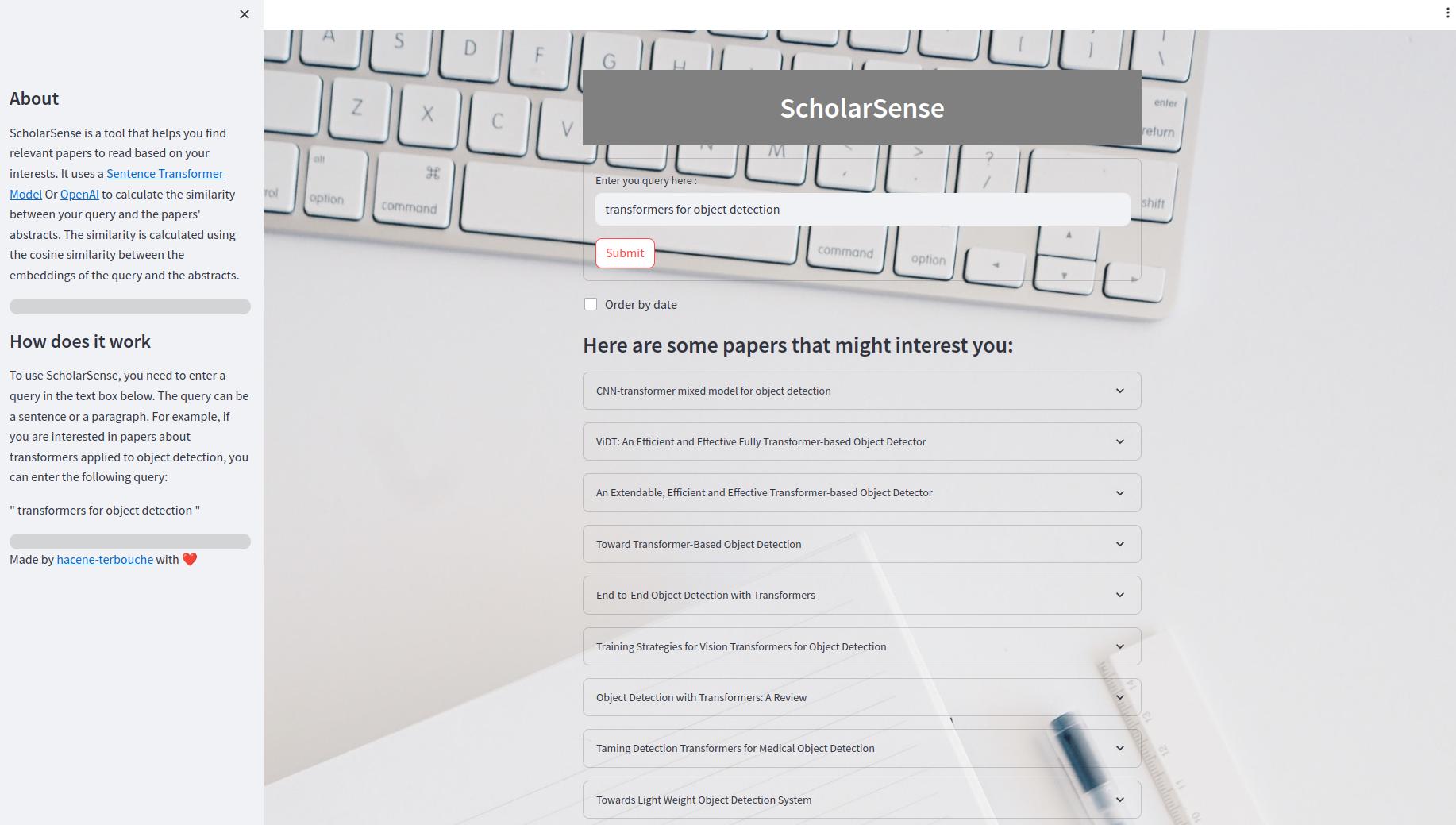
Die Streamlit -App ist eine Web -App, mit der Sie mit einer Abfrage nach Papieren suchen können. In der Benutzeroberfläche können Sie eine Abfrage in das Textfeld eingeben und auf die Schaltfläche "Senden" klicken, um die Ergebnisse zu erhalten. Sie können die Ergebnisse auch nach Datum bestellen. Die Ergebnisse werden als erweiterbare Liste von Papieren angezeigt. Jedes Papier verfügt über einen Titel, eine Zusammenfassung und einen Link zur PDF -Datei.
Dieses Repo schlägt drei Backends vor, die Sie mit der Streamlit -App verwenden können: 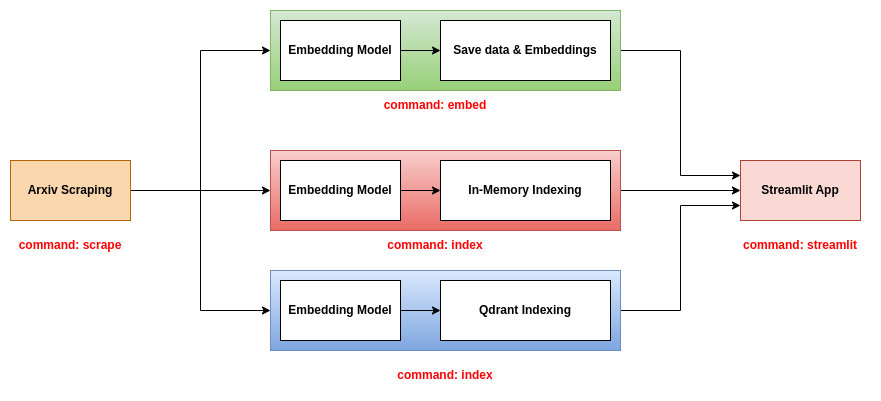
Dieses Backend ist das einfachste. Es wird eine CSV -Datei verwendet, die die Informationen der Papiere und eine Gurkendatei mit den Einbettungen der Papiere enthält. Die CSV -Datei enthält die folgenden Spalten:
title : Der Titel des Papiers.abstract : Das Zusammenfassung des Papiers.pdf_url : Die URL der PDF -Datei.id : Die ID des Papiers.Die Gurkendatei enthält eine numpige Form von Form (N, D), wobei n die Anzahl der Papiere und d die Dimension der Einbettungen ist.
Um dieses Backend zu verwenden, sollten Sie die drei Befehle scrape , embed und streamlit . Weitere Informationen zu diesen Befehlen finden Sie im Abschnitt CLI Tool.
Dieses Backend verwendet die JSON-Dateien, die die Informationen der Papiere enthalten und sowohl die Papiere als auch die Einbettung in einer In-Memory-Datenbank indexieren. Der Index wird als .bin -Datei gespeichert. Um dieses Backend zu verwenden, sollten Sie die drei Befehle scrape , index und streamlit verwenden. Weitere Informationen zu diesen Befehlen finden Sie im Abschnitt CLI Tool.
Dieses Backend verwendet die JSON -Dateien, die die Informationen der Papiere enthalten und sowohl die Papiere als auch die Einbettung in einer QDrant -Datenbank indexieren. Um dieses Backend zu verwenden, sollten Sie die drei Befehle scrape , index und streamlit verwenden. Weitere Informationen zu diesen Befehlen finden Sie im Abschnitt CLI Tool.
Um den QDRANT -Server auszuführen, können Sie den folgenden Befehl ausführen:
docker-compose up -d
Der einfachste Weg zur Verwendung von Gelehrten besteht darin, das CLI -Tool zu verwenden. Sie können den folgenden Befehl ausführen, um die Hilfe zur Hilfe zu erhalten:
scholarsense --help
Das CLI -Werkzeug enthält FOOR -Befehle:
scrape : Papiere von Arxiv abkratzenembed : Um die Papiere mit dem Satztransformatormodell oder dem Open AI -Modell einzubettenindex : Um die Papiere mithilfe der A Vector-Datenbank (In-Memory oder Qdrant) einzubetten und zu indizieren)streamlit : Ausführen der Streamlit -App und nach Papieren suchen Um Papiere von Arxiv zu kratzen, können Sie den folgenden Befehl ausführen:
scholarsense scrape --help
Der Befehl nimmt die folgenden Argumente an:
config : Der Pfad zur YAML -Konfigurationsdatei, die die zu suchen, nach denen die Schlüsselwörter gesucht werden sollen.output_path : Der Pfad zur Ausgabedatei, in der die Papiere als JSON -Dateien gespeichert werden.max_results : Die maximale Anzahl von Papieren, die für jedes Schlüsselwort kratzen, beträgt 1000000. Dieser Befehl wird verwendet, um die Papiere mit dem Satztransformatormodell oder dem öffnenden KI -Modell zu betten. Anschließend speichert es die Einbettungen in einer Gurkendatei. Um die Papiere einzubetten, können Sie den folgenden Befehl ausführen:
scholarsense embed --help
Der Befehl nimmt die folgenden Argumente an:
input_path : Der Pfad zur JSON -Datei, die die Papiere enthält.output_path : Der Pfad zur Ausgabedatei, in der die Papiere als Gurkendateien gespeichert werden.csv_file_path : Ein Pfad zu einer CSV -Datei, in der die Informationen der Pepers gespeichert werden.model_type : Der zu verwendende Typ des Modells, entweder sentence-transformers oder openai , Standardeinstellung sind sentence-transformers .model_name : Der Name des Modells, der den gewählten Typ verwendet wird, ist die Standardeinstellung all-MiniLM-L6-v2 .encoding_method : Art der Codierungsmethode, um {Titel, Abstract, concat usw.} zu verwenden, Standard ist title . Dieser Befehl wird verwendet, um die Papiere mithilfe der A Vector-Datenbank (In-Memory oder QDRant) einzubetten und zu indizieren. Um die Papiere einzubetten und zu indizieren, können Sie den folgenden Befehl ausführen:
scholarsense index --help
Der Befehl nimmt die folgenden Argumente an:
db_path : Der Pfad zu JSON -Dateien, die die Papiere enthalten.model_type : Der zu verwendende Typ des Modells, entweder sentence-transformers oder openai , Standardeinstellung sind sentence-transformers .model_name : Der Name des Modells, der den gewählten Typ verwendet wird, ist die Standardeinstellung all-MiniLM-L6-v2 .encoding_method : Art der Codierungsmethode, um {Titel, Abstract, concat usw.} zu verwenden, Standard ist title .indexing_method : Die Methode zum Index der Papiere, entweder in-memory oder qdrant , standardmäßig ist in-memory .host : Der Host des QDrant -Servers ist keine Standard.port : Der Port des QDrant -Servers ist keine Standard.collection_name : Der Name der Sammlung, die in QDrant verwendet werden soll, ist keine.index_file_path : Der Pfad zu der als .bin-Datei für In-Memory-Indexierung gespeicherten Indexdatei ist Standard. Dieser Befehl wird verwendet, um die Streamlit -App auszuführen und nach Papieren zu suchen. Um die Streamlit -App auszuführen, können Sie den folgenden Befehl ausführen:
scholarsense streamlit --help
Der Befehl nimmt die folgenden Argumente an:
backend : Das zu verwendende Backend, entweder simple , in-memory oder qdrant .model_type : Der Typ des zu verwendenden Modells, entweder sentence-transformers oder openai .model_name : Der Name des Modells zur Verwendung des gewählten Typs.encoding_method : Art der Codierungsmethode zur Verwendung {Titel, Abstract, concat usw.}.limit : Die maximale Anzahl von Papieren, die angezeigt werden sollen.collection_name : Der Name der Sammlung, die in QDrant verwendet werden soll.csv_file_path : Ein Pfad zur CSV -Datei, die die Informationen der Papiere enthält, nützlich, wenn Sie einfaches Backend verwenden.embedding_file_path : Der Pfad zur Gurkendatei mit den Einbettungen, die nützlich sind, wenn Sie einfaches Backend verwenden.index_file_path : Der Pfad zu der als .bin-Datei für die In-Memory-Indexierung gespeicherten Indexdatei, nützlich, wenn Sie In-Memory-Backend verwenden.

