ScholarSense
v0.1.0-alpha

ScholarSense es una herramienta que le ayuda a encontrar artículos relevantes para leer según sus intereses. Le permite buscar documentos con una consulta. Utiliza un modelo de idioma para incorporar la información de los documentos (título, abstracto, etc.) en un espacio vectorial. Luego, indexa las integridades de los documentos en una base de datos de vectores (en memoria o qdrant). Definalmente, utiliza la consulta para buscar los documentos más relevantes en la base de datos.
Para ejecutar ScholarSense localmente, debe instalar el entorno virtual, así como todas las dependencias utilizando Poetry Python Package Manager.
poetry install
Para activar el entorno virtual, puede ejecutar el siguiente comando:
poetry shell
Para verificar que se active el entorno virtual, puede importar el paquete e imprimir la versión:
python -c "import scholarsense; print(scholarsense.__version__)"
Después de instalar el paquete, es posible que deba crear la estructura de las carpetas. Puede hacerlo ejecutando el siguiente comando:
./bash/create_dirs.sh
Crea la siguiente estructura:
.
├── artifacts
│ ├── data
│ │ ├── csv
│ │ ├── json
| └── embeddings
Luego, debe crear un archivo de configuración. Puede usar el archivo config.yaml como plantilla. Puede cambiar las palabras clave para buscar.
Esta herramienta se puede usar de dos maneras:
Puede ejecutar los scripts directamente desde la línea de comando. Por ejemplo, para raspar los documentos de ARXIV, puede ejecutar el siguiente comando:
python scripts/run_scraping.py --config ./config/config.yaml --output_path ./artifacts/data/json --max_results 1000000
También puede usar los scripts bash en la carpeta Bash. Por ejemplo, para raspar los documentos de ARXIV, puede ejecutar el siguiente comando:
./bash/scrap.sh
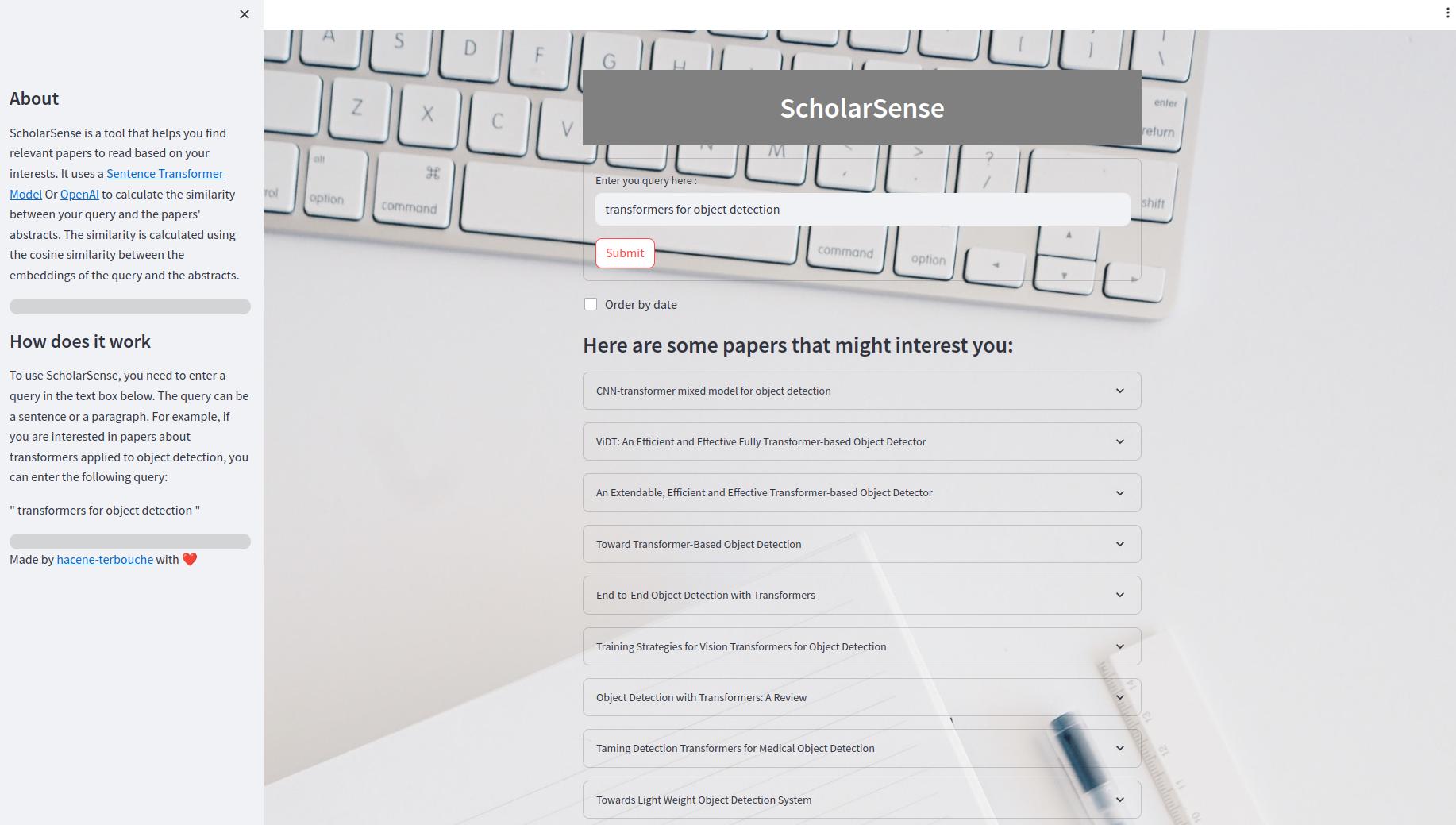
La aplicación Streamlit es una aplicación web que le permite buscar documentos utilizando una consulta. Dentro de la interfaz de usuario, puede ingresar una consulta en el cuadro de texto y hacer clic en el botón "Enviar" para obtener los resultados. También puede pedir los resultados por fecha. Los resultados se muestran como una lista expandible de documentos. Cada artículo tiene un título, un resumen y un enlace al archivo PDF.
Este repositorio propone tres backends para usar con la aplicación Streamlit: 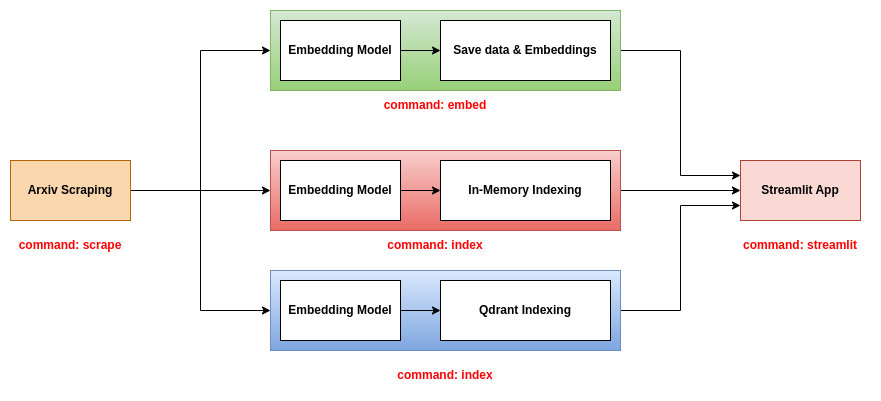
Este backend es el más simple. Utiliza un archivo CSV que contiene la información de los documentos y un archivo de encurtido que contiene los incrustaciones de los documentos. El archivo CSV contiene las siguientes columnas:
title : El título del periódico.abstract : El resumen del documento.pdf_url : la URL del archivo PDF.id : la identificación del documento.El archivo de encurtido contiene una matriz numpy de forma (n, d), donde n es el número de papeles y D es la dimensión de los incrustaciones.
Para usar este backend, debe usar los tres comandos scrape , embed y streamlit . Para obtener más información sobre estos comandos, consulte la sección de la herramienta CLI.
Este backend utiliza los archivos JSON que contienen la información de los documentos e indexan tanto los documentos como los incrustaciones en una base de datos en memoria. El índice se guarda como un archivo .bin. Para usar este backend, debe usar los tres comandos scrape , index y streamlit . Para obtener más información sobre estos comandos, consulte la sección de la herramienta CLI.
Este backend utiliza los archivos JSON que contienen la información de los documentos e indexan tanto los documentos como los incrustaciones en una base de datos QDRANT. Para usar este backend, debe usar los tres comandos scrape , index y streamlit . Para obtener más información sobre estos comandos, consulte la sección de la herramienta CLI.
Para ejecutar el servidor Qdrant, puede ejecutar el siguiente comando:
docker-compose up -d
La forma más simple de usar ScholarSense es usar la herramienta CLI. Puede ejecutar el siguiente comando para obtener el mensaje de ayuda:
scholarsense --help
La herramienta CLI tiene comandos Foor:
scrape : raspar los papeles de Arxivembed : para incrustar los documentos utilizando el modelo de transformador de oración o el modelo de IA abiertoindex : para incrustar e indexar los documentos utilizando la base de datos A vector (en memoria o qdrant)streamlit : para ejecutar la aplicación Streamlit y buscar documentos Para raspar los papeles de ARXIV, puede ejecutar el siguiente comando:
scholarsense scrape --help
El comando toma los siguientes argumentos:
config : la ruta al archivo de configuración YAML, que contiene las palabras clave para buscar.output_path : la ruta al archivo de salida, donde los documentos se guardarán como archivos JSON.max_results : el número máximo de documentos para raspar para cada palabra clave, el valor predeterminado es 1000000. Este comando se utiliza para incrustar los documentos utilizando el modelo de transformador de oración o el modelo de IA abierto. Luego guarda los incrustaciones en un archivo de encurtido. Para incrustar los documentos, puede ejecutar el siguiente comando:
scholarsense embed --help
El comando toma los siguientes argumentos:
input_path : la ruta al archivo JSON que contiene los documentos.output_path : la ruta al archivo de salida, donde los documentos se guardarán como archivos de encurtido.csv_file_path : una ruta a un archivo CSV, donde se guardará la información de los Pepers.model_type : el tipo de modelo a usar, ya sea sentence-transformers o openai , el valor predeterminado es sentence-transformers .model_name : el nombre del modelo para usar el tipo elegido, predeterminado es all-MiniLM-L6-v2 .encoding_method : Tipo de método de codificación para usar {Título, Abstract, Concat, etc.}, el título predeterminado es title . Este comando se utiliza para incrustar e indexar los documentos utilizando la base de datos A Vector (en memoria o qdrant). Para incrustar e indexar los documentos, puede ejecutar el siguiente comando:
scholarsense index --help
El comando toma los siguientes argumentos:
db_path : La ruta a los archivos JSON que contienen los documentos.model_type : el tipo de modelo a usar, ya sea sentence-transformers o openai , el valor predeterminado es sentence-transformers .model_name : el nombre del modelo para usar el tipo elegido, predeterminado es all-MiniLM-L6-v2 .encoding_method : Tipo de método de codificación para usar {Título, Abstract, Concat, etc.}, el título predeterminado es title .indexing_method : el método a usar para indexar los documentos, ya sea in-memory o qdrant , el valor predeterminado está in-memory .host : el host del servidor Qdrant, el valor predeterminado es ninguno.port : el puerto del servidor Qdrant, predeterminado es ninguno.collection_name : el nombre de la colección a usar en Qdrant, el valor predeterminado es ninguno.index_file_path : la ruta al archivo de índice guardado como el archivo .bin para la indexación en memoria, el valor predeterminado es ninguno. Este comando se utiliza para ejecutar la aplicación Streamlit y buscar documentos. Para ejecutar la aplicación Streamlit, puede ejecutar el siguiente comando:
scholarsense streamlit --help
El comando toma los siguientes argumentos:
backend : el backend para usar, ya sea simple , in-memory o qdrant .model_type : el tipo de modelo a usar, ya sea sentence-transformers o openai .model_name : el nombre del modelo para usar el tipo elegido.encoding_method : Tipo de método de codificación para usar {Título, Abstract, Concat, etc.}.limit : el número máximo de documentos a mostrar.collection_name : el nombre de la colección a usar en Qdrant.csv_file_path : una ruta al archivo CSV que contiene la información de los documentos, útil si está utilizando un backend simple.embedding_file_path : la ruta al archivo de pepinillos que contiene los incrustaciones, útil si está utilizando el backend simple.index_file_path : la ruta al archivo de índice guardado como el archivo .bin para la indexación en memoria, útil si está utilizando el backend en memoria.

