ScholarSense
v0.1.0-alpha

ScholarSense é uma ferramenta que ajuda a encontrar trabalhos relevantes para ler com base em seus interesses. Ele permite que você pesquise artigos usando uma consulta. Ele usa um modelo de idioma para incorporar as informações dos papéis (título, resumo, etc.) em um espaço vetorial. Em seguida, indexa as incorporações dos papéis em um banco de dados vetorial (na memória ou QDRANT) .Finalmente, ele usa a consulta para procurar os artigos mais relevantes no banco de dados.
Para executar o ScholarSense localmente, você precisa instalar o ambiente virtual, bem como todas as dependências usando o Poetry Python Package Manager.
poetry install
Para ativar o ambiente virtual, você pode executar o seguinte comando:
poetry shell
Para verificar se o ambiente virtual está ativado, você pode importar o pacote e imprimir a versão:
python -c "import scholarsense; print(scholarsense.__version__)"
Depois de instalar o pacote, pode ser necessário criar a estrutura das pastas. Você pode fazer isso executando o seguinte comando:
./bash/create_dirs.sh
Cria a seguinte estrutura:
.
├── artifacts
│ ├── data
│ │ ├── csv
│ │ ├── json
| └── embeddings
Em seguida, você precisa criar um arquivo de configuração. Você pode usar o arquivo config.yaml como um modelo. Você pode alterar as palavras -chave a serem pesquisadas.
Esta ferramenta pode ser usada de duas maneiras:
Você pode executar os scripts diretamente da linha de comando. Por exemplo, para raspar papéis do ARXIV, você pode executar o seguinte comando:
python scripts/run_scraping.py --config ./config/config.yaml --output_path ./artifacts/data/json --max_results 1000000
Você também pode usar os scripts de bash na pasta Bash. Por exemplo, para raspar papéis do ARXIV, você pode executar o seguinte comando:
./bash/scrap.sh
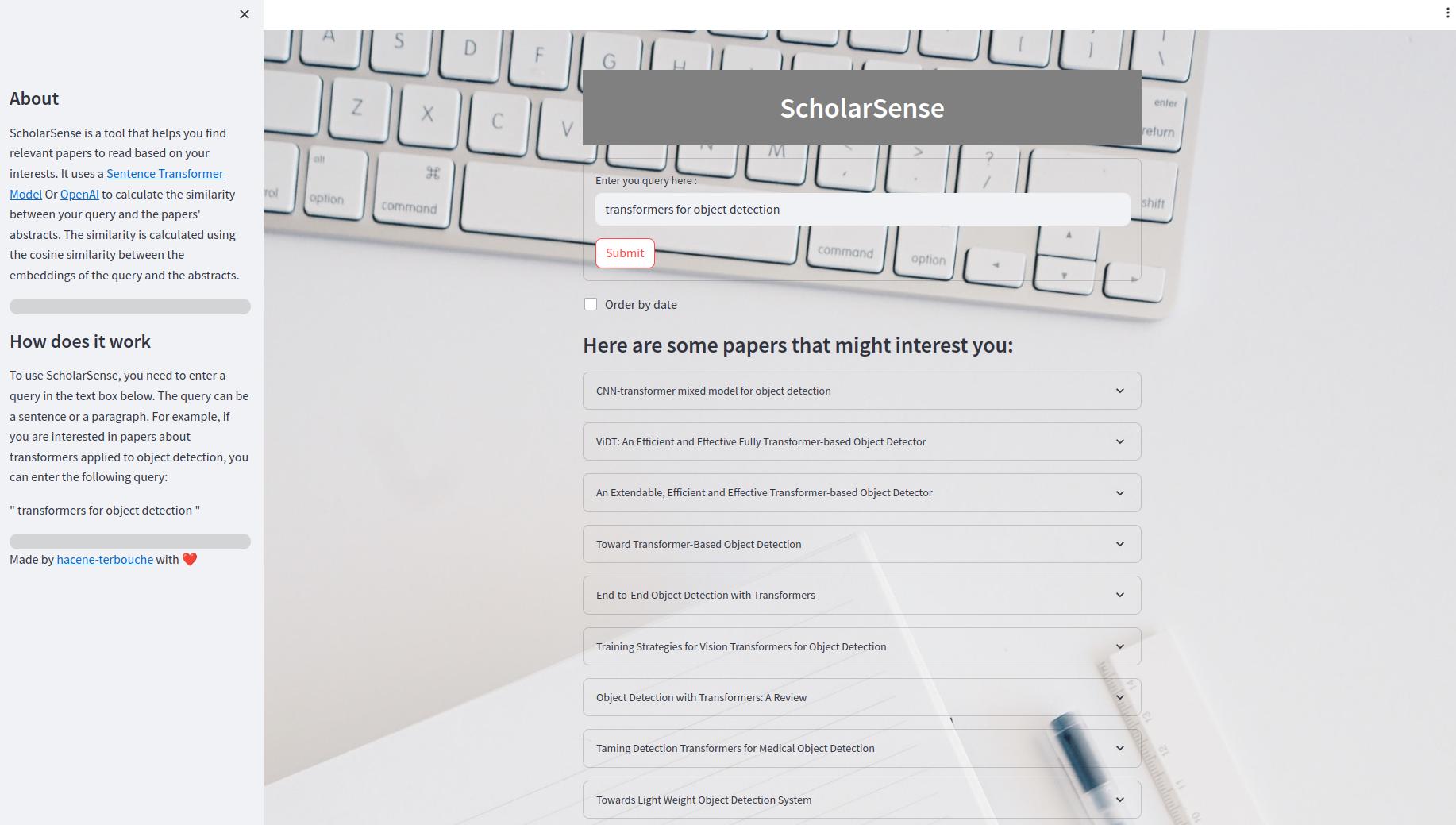
O aplicativo Streamlit é um aplicativo da Web que permite pesquisar papéis usando uma consulta. Dentro da interface do usuário, você pode inserir uma consulta na caixa de texto e clicar no botão "Enviar" para obter os resultados. Você também pode solicitar os resultados por data. Os resultados são exibidos como uma lista expansível de trabalhos. Cada artigo tem um título, um resumo e um link para o arquivo PDF.
Este repo propõe três back -ends a serem usados com o aplicativo Streamlit: 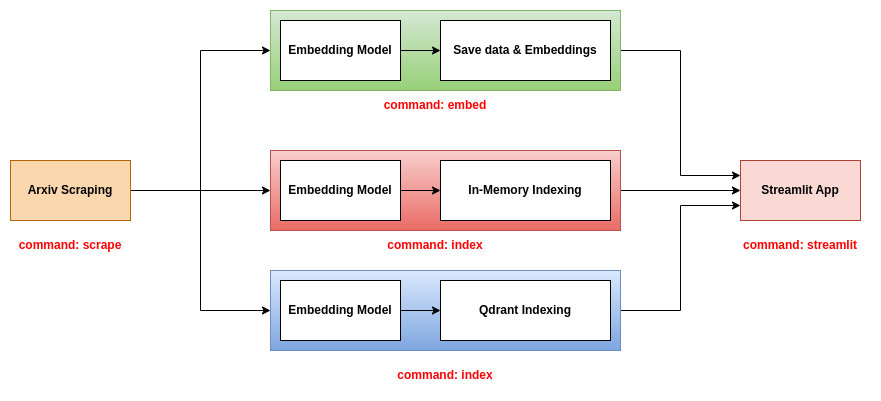
Este back -end é o mais simples. Ele usa um arquivo CSV que contém as informações dos papéis e um arquivo em picles que contém as incorporações dos papéis. O arquivo CSV contém as seguintes colunas:
title : O título do artigo.abstract : O resumo do artigo.pdf_url : O URL do arquivo PDF.id : O ID do papel.O arquivo em picles contém uma variedade de formas numpy (n, d), onde n é o número de papéis e d é a dimensão das incorporações.
Para usar esse back -end, você deve usar os três comandos scrape , embed e streamlit . Para obter mais informações sobre esses comandos, consulte a seção de ferramentas da CLI.
Esse back-end usa os arquivos JSON que contêm as informações dos papéis e indexam os papéis e as incorporações em um banco de dados de memória. O índice é salvo como um arquivo .bin. Para usar esse back -end, você deve usar os três comandos scrape , index e streamlit . Para obter mais informações sobre esses comandos, consulte a seção de ferramentas da CLI.
Esse back -end usa os arquivos JSON que contêm as informações dos papéis e indexam os papéis e as incorporações em um banco de dados QDRANT. Para usar esse back -end, você deve usar os três comandos scrape , index e streamlit . Para obter mais informações sobre esses comandos, consulte a seção de ferramentas da CLI.
Para executar o servidor QDrant, você pode executar o seguinte comando:
docker-compose up -d
A maneira mais simples de usar o ScholarSense é usar a ferramenta CLI. Você pode executar o seguinte comando para obter a mensagem de ajuda:
scholarsense --help
A ferramenta da CLI possui comandos FOOR:
scrape : raspar papéis de arxivembed : para incorporar os papéis usando o modelo de transformador de sentença ou o modelo de IA abertoindex : Para incorporar e indexar os documentos usando o banco de dados A Vector (in-memória ou QDRANT)streamlit : para executar o aplicativo StreamLit e pesquisar papéis Para raspar papéis de Arxiv, você pode executar o seguinte comando:
scholarsense scrape --help
O comando leva os seguintes argumentos:
config : o caminho para o arquivo de configuração YAML, contendo as palavras -chave a serem pesquisadas.output_path : o caminho para o arquivo de saída, onde os papéis serão salvos como arquivos JSON.max_results : o número máximo de papéis a raspar para cada palavra -chave, o padrão é 1000000. Este comando é usado para incorporar os papéis usando o modelo de transformador de sentença ou o modelo de IA aberto. Em seguida, salva as incorporações em um arquivo de picles. Para incorporar os papéis, você pode executar o seguinte comando:
scholarsense embed --help
O comando leva os seguintes argumentos:
input_path : o caminho para o arquivo json que contém os papéis.output_path : o caminho para o arquivo de saída, onde os papéis serão salvos como arquivos de picles.csv_file_path : um caminho para um arquivo CSV, onde as informações do Pepers serão salvas.model_type : o tipo de modelo a ser usado, sentence-transformers ou openai , o padrão é sentence-transformers .model_name : o nome do modelo para usar o tipo escolhido, o padrão é all-MiniLM-L6-v2 .encoding_method : tipo de método de codificação para usar {título, abstrato, concat, etc.}, o padrão é title . Este comando é usado para incorporar e indexar os documentos usando o banco de dados A Vector (In Memory ou QDrant). Para incorporar e indexar os papéis, você pode executar o seguinte comando:
scholarsense index --help
O comando leva os seguintes argumentos:
db_path : O caminho para os arquivos JSON que contêm os papéis.model_type : o tipo de modelo a ser usado, sentence-transformers ou openai , o padrão é sentence-transformers .model_name : o nome do modelo para usar o tipo escolhido, o padrão é all-MiniLM-L6-v2 .encoding_method : tipo de método de codificação para usar {título, abstrato, concat, etc.}, o padrão é title .indexing_method : O método a ser usado para indexar os papéis, in-memory ou qdrant , o padrão está in-memory .host : o host do servidor QDrant, o padrão não é.port : a porta do servidor QDRANT, o padrão não é.collection_name : o nome da coleção a ser usado no QDRANT, o padrão não é.index_file_path : o caminho para o arquivo de índice salvo como arquivo .bin para indexação na memória, o padrão é nenhum. Este comando é usado para executar o aplicativo StreamLit e pesquisar artigos. Para executar o aplicativo StreamLit, você pode executar o seguinte comando:
scholarsense streamlit --help
O comando leva os seguintes argumentos:
backend : o back-end a ser usado, simple , in-memory ou qdrant .model_type : o tipo do modelo a ser usado, sentence-transformers ou openai .model_name : o nome do modelo para usar o tipo escolhido.encoding_method : tipo de método de codificação para usar {título, abstrato, concat, etc.}.limit : o número máximo de papéis a serem exibidos.collection_name : o nome da coleção a ser usado no QDRANT.csv_file_path : um caminho para o arquivo CSV que contém as informações dos papéis, útil se você estiver usando o back -end simples.embedding_file_path : o caminho para o arquivo de picles que contém as incorporações, útil se você estiver usando o back -end simples.index_file_path : o caminho para o arquivo de índice salvo como arquivo .bin para indexação na memória, útil se você estiver usando o back-end na memória.

