ScholarSense
v0.1.0-alpha

Scholarsense هي أداة تساعدك على العثور على الأوراق ذات الصلة التي يمكنك قراءتها بناءً على اهتماماتك. يسمح لك بالبحث عن الأوراق باستخدام استعلام. يستخدم نموذج لغة لتضمين معلومات الأوراق (العنوان ، الملخص ، إلخ) في مساحة متجه. بعد ذلك ، فهرسة تضمينات الأوراق في قاعدة بيانات متجه (في الذاكرة أو QDrant).
لتشغيل Scholarsense محليًا ، تحتاج إلى تثبيت البيئة الافتراضية وكذلك جميع التبعيات باستخدام Poetry Python Package Manager.
poetry install
لتفعيل البيئة الافتراضية ، يمكنك تشغيل الأمر التالي:
poetry shell
للتحقق من تنشيط البيئة الافتراضية ، يمكنك استيراد الحزمة وطباعة الإصدار:
python -c "import scholarsense; print(scholarsense.__version__)"
بعد تثبيت الحزمة ، قد تحتاج إلى إنشاء بنية المجلدات. يمكنك القيام بذلك عن طريق تشغيل الأمر التالي:
./bash/create_dirs.sh
يخلق الهيكل التالي:
.
├── artifacts
│ ├── data
│ │ ├── csv
│ │ ├── json
| └── embeddings
ثم ، تحتاج إلى إنشاء ملف تكوين. يمكنك استخدام ملف config.yaml كقالب. يمكنك تغيير الكلمات الرئيسية للبحث عنها.
يمكن استخدام هذه الأداة بطريقتين:
يمكنك تشغيل البرامج النصية مباشرة من سطر الأوامر. على سبيل المثال ، لكشط الأوراق من Arxiv ، يمكنك تشغيل الأمر التالي:
python scripts/run_scraping.py --config ./config/config.yaml --output_path ./artifacts/data/json --max_results 1000000
يمكنك أيضًا استخدام البرامج النصية باش في مجلد باش. على سبيل المثال ، لكشط الأوراق من Arxiv ، يمكنك تشغيل الأمر التالي:
./bash/scrap.sh
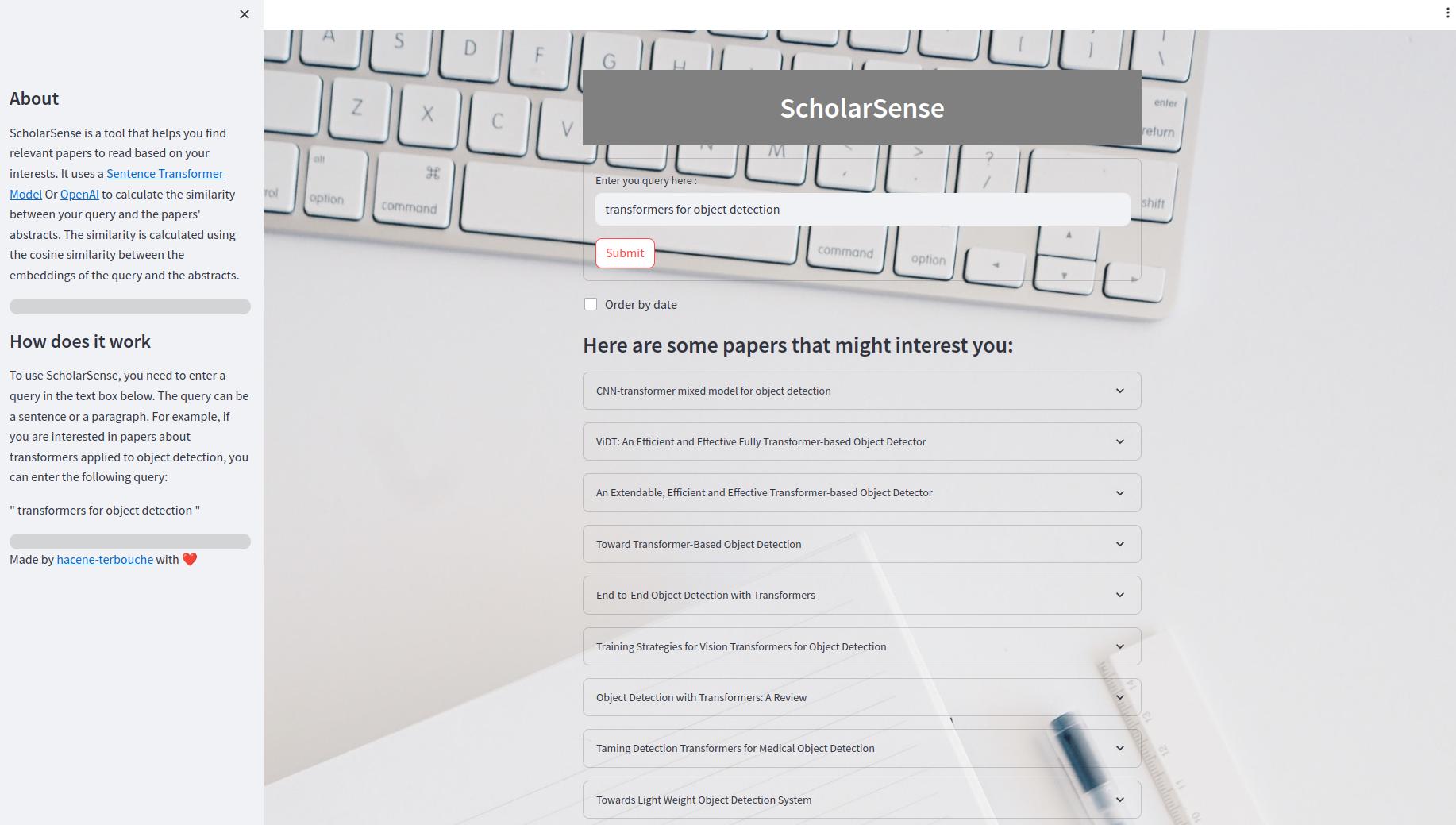
تطبيق SPEREMLIT هو تطبيق ويب يسمح لك بالبحث عن أوراق باستخدام استعلام. داخل واجهة المستخدم ، يمكنك إدخال استعلام في مربع النص والنقر فوق الزر "إرسال" للحصول على النتائج. يمكنك أيضًا طلب النتائج حسب التاريخ. يتم عرض النتائج كقائمة قابلة للتوسيع من الأوراق. كل ورقة لها عنوان وملخص ورابط لملف PDF.
يقترح هذا الريبو ثلاثة مباريات خلفية لاستخدامها مع تطبيق SPEMANLIT: 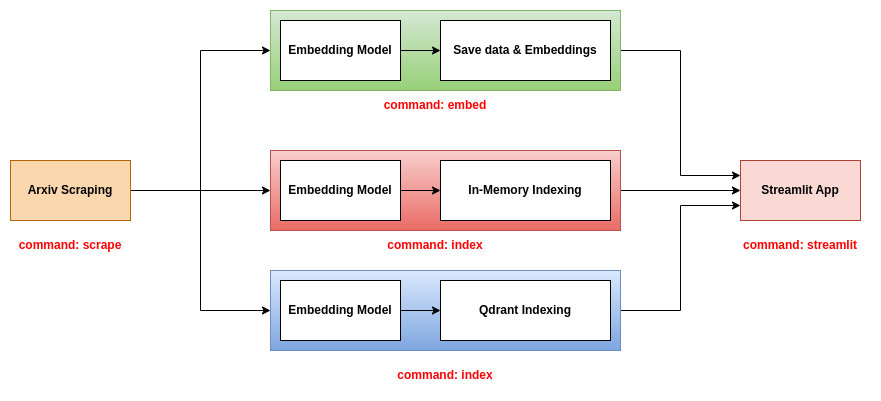
هذه الواجهة الخلفية هي أبسط واحد. يستخدم ملف CSV يحتوي على معلومات الأوراق وملف مخلل يحتوي على تضمينات الأوراق. يحتوي ملف CSV على الأعمدة التالية:
title : عنوان الورقة.abstract : ملخص الورقة.pdf_url : عنوان URL لملف PDF.id : معرف الورقة.يحتوي ملف المخلل على مجموعة من الشكل (N ، D) ، حيث N هو عدد الأوراق و D هو بُعد التضمينات.
لاستخدام هذه الواجهة الخلفية ، يجب عليك استخدام الأوامر الثلاثة scrape embed streamlit . لمزيد من المعلومات حول هذه الأوامر ، يرجى الرجوع إلى قسم أداة CLI.
تستخدم هذه الواجهة الخلفية ملفات JSON التي تحتوي على معلومات الأوراق وفهرس كل من الأوراق والتضمينات في قاعدة بيانات في الذاكرة. يتم حفظ الفهرس كملف .bin. لاستخدام هذه الواجهة الخلفية ، يجب عليك استخدام الأوامر الثلاثة scrape ، index ، و streamlit . لمزيد من المعلومات حول هذه الأوامر ، يرجى الرجوع إلى قسم أداة CLI.
تستخدم هذه الواجهة الخلفية ملفات JSON التي تحتوي على معلومات الأوراق وفهرس كل من الأوراق والتضمينات في قاعدة بيانات QDrant. لاستخدام هذه الواجهة الخلفية ، يجب عليك استخدام الأوامر الثلاثة scrape ، index ، و streamlit . لمزيد من المعلومات حول هذه الأوامر ، يرجى الرجوع إلى قسم أداة CLI.
لتشغيل خادم QDrant ، يمكنك تشغيل الأمر التالي:
docker-compose up -d
أبسط طريقة لاستخدام Scholarsense هي استخدام أداة CLI. يمكنك تشغيل الأمر التالي للحصول على رسالة المساعدة:
scholarsense --help
تحتوي أداة CLI على أوامر foor:
scrape : لكشط الأوراق من Arxivembed : لتضمين الأوراق باستخدام نموذج محول الجملة أو نموذج AI Openindex : لتضمين وفهرسة الأوراق باستخدام قاعدة بيانات المتجهات (في الذاكرة أو QDrant)streamlit : لتشغيل تطبيق STREMLIT والبحث عن الأوراق لكشط الأوراق من Arxiv ، يمكنك تشغيل الأمر التالي:
scholarsense scrape --help
يأخذ الأمر الوسائط التالية:
config : المسار إلى ملف تكوين YAML ، يحتوي على الكلمات الرئيسية للبحث عنها.output_path : المسار إلى ملف الإخراج ، حيث سيتم حفظ الأوراق كملفات JSON.max_results : الحد الأقصى لعدد الأوراق التي يجب كشطها لكل كلمة رئيسية ، الافتراضي هو 1000000. يتم استخدام هذا الأمر لتضمين الأوراق باستخدام نموذج محول الجملة أو نموذج AI Open. ثم يحفظ التضمينات في ملف المخلل. لتضمين الأوراق ، يمكنك تشغيل الأمر التالي:
scholarsense embed --help
يأخذ الأمر الوسائط التالية:
input_path : المسار إلى ملف JSON يحتوي على الأوراق.output_path : المسار إلى ملف الإخراج ، حيث سيتم حفظ الأوراق كملفات المخلل.csv_file_path : مسار إلى ملف CSV ، حيث سيتم حفظ معلومات Pepers.model_type : نوع النموذج المراد استخدامه ، إما sentence-transformers أو openai ، هو sentence-transformers .model_name : اسم النموذج لاستخدام النوع المختار ، الافتراضي هو all-MiniLM-L6-v2 .encoding_method : نوع طريقة الترميز لاستخدام {title ، الملخص ، concat ، إلخ} ، الافتراضي هو title . يتم استخدام هذا الأمر لتضمين الأوراق وفهرستها باستخدام قاعدة بيانات المتجه (في الذاكرة أو QDrant). لتضمين الأوراق وفهرسها ، يمكنك تشغيل الأمر التالي:
scholarsense index --help
يأخذ الأمر الوسائط التالية:
db_path : المسار إلى ملفات JSON التي تحتوي على الأوراق.model_type : نوع النموذج المراد استخدامه ، إما sentence-transformers أو openai ، هو sentence-transformers .model_name : اسم النموذج لاستخدام النوع المختار ، الافتراضي هو all-MiniLM-L6-v2 .encoding_method : نوع طريقة الترميز لاستخدام {title ، الملخص ، concat ، إلخ} ، الافتراضي هو title .indexing_method : الطريقة التي يجب استخدامها لفهرسة الأوراق ، إما in-memory أو qdrant ، تكون الافتراضي in-memory .host : مضيف خادم QDrant ، الافتراضي هو لا شيء.port : منفذ خادم QDrant ، الافتراضي هو لا شيء.collection_name : اسم المجموعة المراد استخدامها في QDrant ، الافتراضي هو لا شيء.index_file_path : المسار إلى ملف الفهرس المحفوظ كملف .bin لفهرسة في الذاكرة ، لا شيء. يتم استخدام هذا الأمر لتشغيل تطبيق STREMLIT والبحث عن الأوراق. لتشغيل تطبيق SPEREMLIT ، يمكنك تشغيل الأمر التالي:
scholarsense streamlit --help
يأخذ الأمر الوسائط التالية:
backend : الواجهة الخلفية لاستخدامها ، إما simple ، in-memory أو qdrant .model_type : نوع النموذج المراد استخدامه ، إما sentence-transformers أو openai .model_name : اسم النموذج لاستخدام النوع المختار.encoding_method : نوع طريقة الترميز لاستخدام {title ، Abstract ، concat ، etc.}.limit : الحد الأقصى لعدد الأوراق لعرضه.collection_name : اسم المجموعة لاستخدامها في QDrant.csv_file_path : مسار إلى ملف CSV يحتوي على معلومات الأوراق ، مفيدة إذا كنت تستخدم الواجهة الخلفية البسيطة.embedding_file_path : المسار إلى ملف المخلل الذي يحتوي على التضمين ، مفيد إذا كنت تستخدم الواجهة الخلفية البسيطة.index_file_path : المسار إلى ملف الفهرس المحفوظ كملف .bin لفهرسة في الذاكرة ، مفيد إذا كنت تستخدم الواجهة الخلفية في الذاكرة.

