ScholarSense
v0.1.0-alpha

Scholarsense est un outil qui vous aide à trouver des articles pertinents à lire en fonction de vos intérêts. Il vous permet de rechercher des articles à l'aide d'une requête. Il utilise un modèle de langue pour intégrer les informations des articles (titre, abstrait, etc.) dans un espace vectoriel. Ensuite, il index les intégres des articles dans une base de données vectorielle (en mémoire ou QDRANT). Enfin, il utilise la requête pour rechercher les articles les plus pertinents de la base de données.
Pour exécuter Scholarsense localement, vous devez installer l'environnement virtuel ainsi que toutes les dépendances à l'aide de Poetry Python Package Manager.
poetry install
Pour activer l'environnement virtuel, vous pouvez exécuter la commande suivante:
poetry shell
Pour vérifier que l'environnement virtuel est activé, vous pouvez importer le package et imprimer la version:
python -c "import scholarsense; print(scholarsense.__version__)"
Après avoir installé le package, vous devrez peut-être créer la structure des dossiers. Vous pouvez le faire en exécutant la commande suivante:
./bash/create_dirs.sh
Il crée la structure suivante:
.
├── artifacts
│ ├── data
│ │ ├── csv
│ │ ├── json
| └── embeddings
Ensuite, vous devez créer un fichier de configuration. Vous pouvez utiliser le fichier config.yaml comme modèle. Vous pouvez modifier les mots clés pour rechercher.
Cet outil peut être utilisé de deux manières:
Vous pouvez exécuter les scripts directement à partir de la ligne de commande. Par exemple, pour gratter les papiers d'ARXIV, vous pouvez exécuter la commande suivante:
python scripts/run_scraping.py --config ./config/config.yaml --output_path ./artifacts/data/json --max_results 1000000
Vous pouvez également utiliser les scripts bash dans le dossier bash. Par exemple, pour gratter les papiers d'ARXIV, vous pouvez exécuter la commande suivante:
./bash/scrap.sh
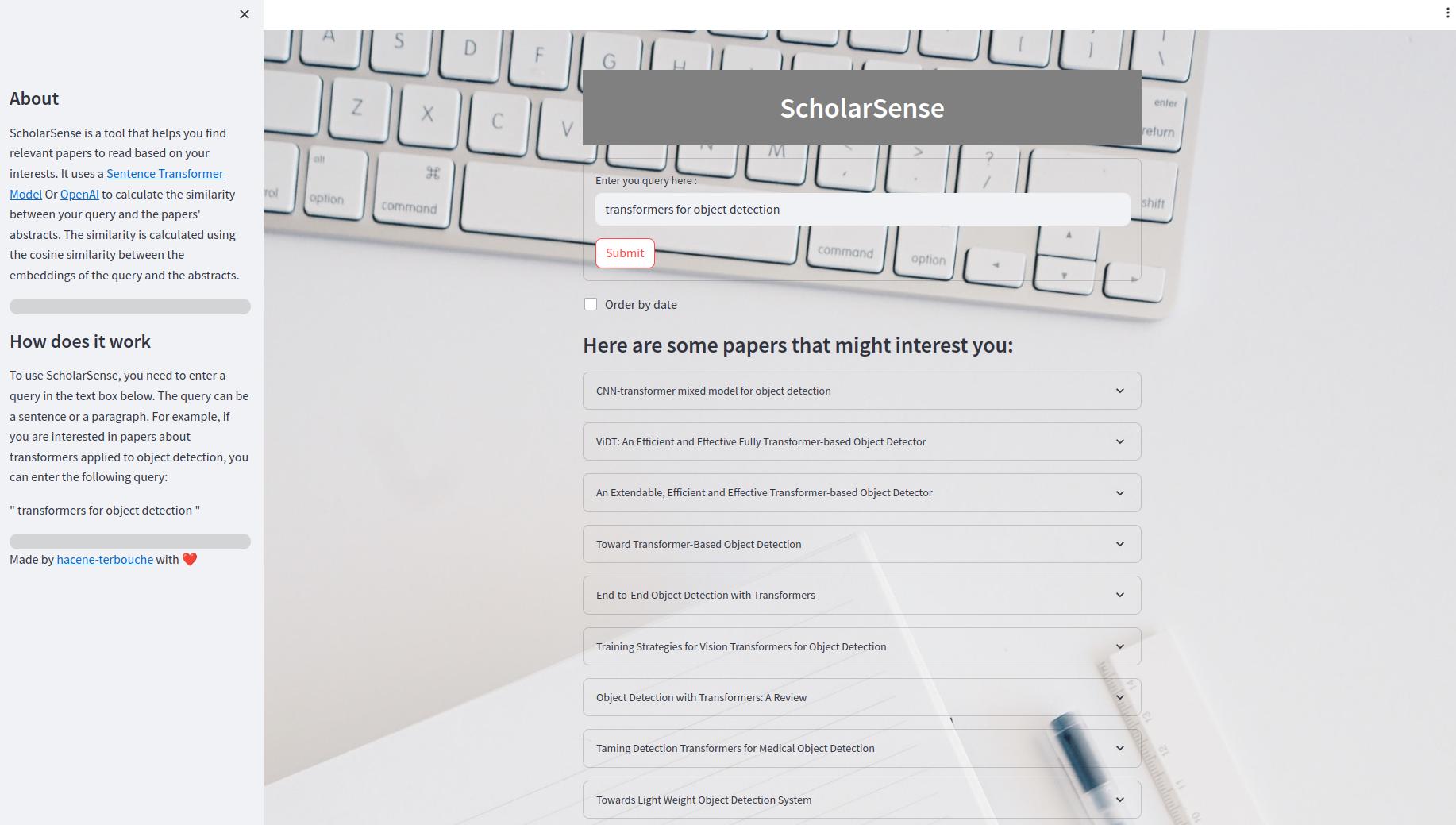
L'application Streamlit est une application Web qui vous permet de rechercher des articles à l'aide d'une requête. À l'intérieur de l'interface utilisateur, vous pouvez entrer une requête dans la zone de texte et cliquer sur le bouton "Soumettre" pour obtenir les résultats. Vous pouvez également commander les résultats par date. Les résultats sont affichés comme une liste extensible des articles. Chaque article a un titre, un résumé et un lien vers le fichier PDF.
Ce repo propose trois backends à utiliser avec l'application Streamlit: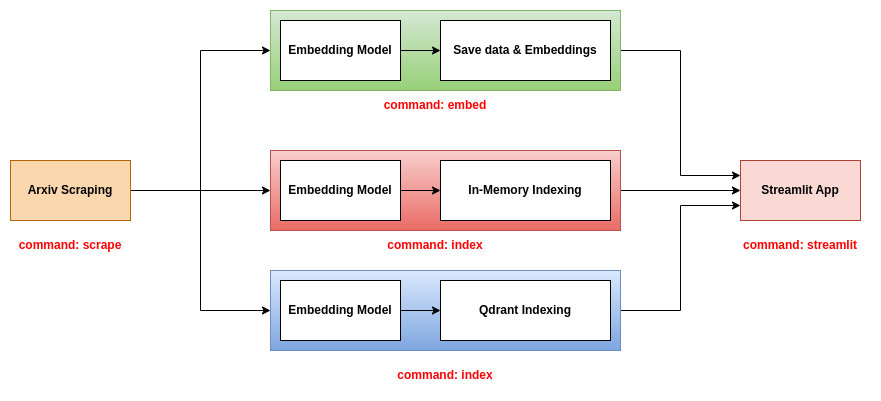
Ce backend est le plus simple. Il utilise un fichier CSV contenant les informations des papiers et un fichier de cornichon contenant les incorporations des papiers. Le fichier CSV contient les colonnes suivantes:
title : Le titre du journal.abstract : Le résumé de l'article.pdf_url : L'URL du fichier PDF.id : ID du papier.Le fichier de cornichon contient un tableau de forme numpy (n, d), où n est le nombre de papiers et d est la dimension des intérêts.
Pour utiliser ce backend, vous devez utiliser les trois commandes scrape , embed et streamlit . Pour plus d'informations sur ces commandes, veuillez vous référer à la section des outils CLI.
Ce backend utilise les fichiers JSON contenant les informations des articles et indexer les articles et les intégres dans une base de données en mémoire. L'index est enregistré en tant que fichier .bin. Pour utiliser ce backend, vous devez utiliser les trois commandes scrape , index et streamlit . Pour plus d'informations sur ces commandes, veuillez vous référer à la section des outils CLI.
Ce backend utilise les fichiers JSON contenant les informations des articles et indexer les articles et les intégres dans une base de données QDRANT. Pour utiliser ce backend, vous devez utiliser les trois commandes scrape , index et streamlit . Pour plus d'informations sur ces commandes, veuillez vous référer à la section des outils CLI.
Pour exécuter le serveur Qdrant, vous pouvez exécuter la commande suivante:
docker-compose up -d
La façon la plus simple d'utiliser Scholarsense est d'utiliser l'outil CLI. Vous pouvez exécuter la commande suivante pour obtenir le message d'aide:
scholarsense --help
L'outil CLI a des commandes de FOOR:
scrape : pour gratter les papiers d'Arxivembed : pour intégrer les papiers à l'aide du modèle de transformateur de phrase ou un modèle d'IA ouvririndex : Pour intégrer et indexer les articles à l'aide de la base de données A Vector (en mémoire ou QDRANT)streamlit : Pour exécuter l'application Streamlit et rechercher des articles Pour gratter les papiers d'Arxiv, vous pouvez exécuter la commande suivante:
scholarsense scrape --help
La commande prend les arguments suivants:
config : le chemin d'accès au fichier de configuration YAML, contenant les mots clés à rechercher.output_path : le chemin du fichier de sortie, où les papiers seront enregistrés sous forme de fichiers JSON.max_results : le nombre maximum d'articles à gratter pour chaque mot-clé, par défaut est 1000000. Cette commande est utilisée pour intégrer les articles à l'aide du modèle de transformateur de phrase ou ouvrir le modèle AI. Il enregistre ensuite les intégres dans un fichier de cornichon. Pour intégrer les papiers, vous pouvez exécuter la commande suivante:
scholarsense embed --help
La commande prend les arguments suivants:
input_path : le chemin du fichier JSON contenant les papiers.output_path : le chemin du fichier de sortie, où les papiers seront enregistrés sous forme de fichiers de cornichon.csv_file_path : Un chemin vers un fichier CSV, où les informations de Pepers seront enregistrées.model_type : Le type du modèle à utiliser, soit sentence-transformers ou openai , par défaut est sentence-transformers .model_name : le nom du modèle à utiliser le type choisi, par défaut est all-MiniLM-L6-v2 .encoding_method : Type de méthode de codage à utiliser {Title, Abstract, Concat, etc.}, la valeur par défaut est title . Cette commande est utilisée pour intégrer et indexer les articles à l'aide de la base de données Vector (en mémoire ou QDRANT). Pour intégrer et indexer les papiers, vous pouvez exécuter la commande suivante:
scholarsense index --help
La commande prend les arguments suivants:
db_path : le chemin d'accès aux fichiers JSON contenant les papiers.model_type : Le type du modèle à utiliser, soit sentence-transformers ou openai , par défaut est sentence-transformers .model_name : le nom du modèle à utiliser le type choisi, par défaut est all-MiniLM-L6-v2 .encoding_method : Type de méthode de codage à utiliser {Title, Abstract, Concat, etc.}, la valeur par défaut est title .indexing_method : La méthode à utiliser pour indexer les articles, in-memory ou qdrant , par défaut est in-memory .host : l'hôte du serveur QDrant, par défaut n'en est pas.port : le port du serveur QDrant, par défaut n'est pas.collection_name : le nom de la collection à utiliser dans Qdrant, la valeur par défaut n'est pas.index_file_path : Le chemin du fichier d'index enregistré en tant que fichier .bin pour l'indexation en mémoire, par défaut n'est pas. Cette commande est utilisée pour exécuter l'application Streamlit et rechercher des articles. Pour exécuter l'application Streamlit, vous pouvez exécuter la commande suivante:
scholarsense streamlit --help
La commande prend les arguments suivants:
backend : le backend à utiliser, simple , in-memory ou qdrant .model_type : Le type du modèle à utiliser, soit sentence-transformers ou openai .model_name : le nom du modèle à utiliser du type choisi.encoding_method : Type de méthode de codage à utiliser {Title, Résumé, Concat, etc.}.limit : le nombre maximum de papiers à afficher.collection_name : le nom de la collection à utiliser dans Qdrant.csv_file_path : un chemin vers le fichier CSV contenant les informations des papiers, utile si vous utilisez un backend simple.embedding_file_path : le chemin du fichier de cornichon contenant les intégres, utile si vous utilisez un backend simple.index_file_path : le chemin du fichier d'index enregistré en tant que fichier .bin pour l'indexation en mémoire, utile si vous utilisez un backend en mémoire.

