LiLT
1.0.0
[2022/10] LILT已添加到這裡的HuggingFace/Transformers。
[2022/03]初始模型和代碼發布。
這是ACL 2022論文的官方Pytorch實施:“ LILT:一種簡單而有效的語言獨立的佈局變壓器,用於結構化文檔的理解”。 [官方] [arxiv]
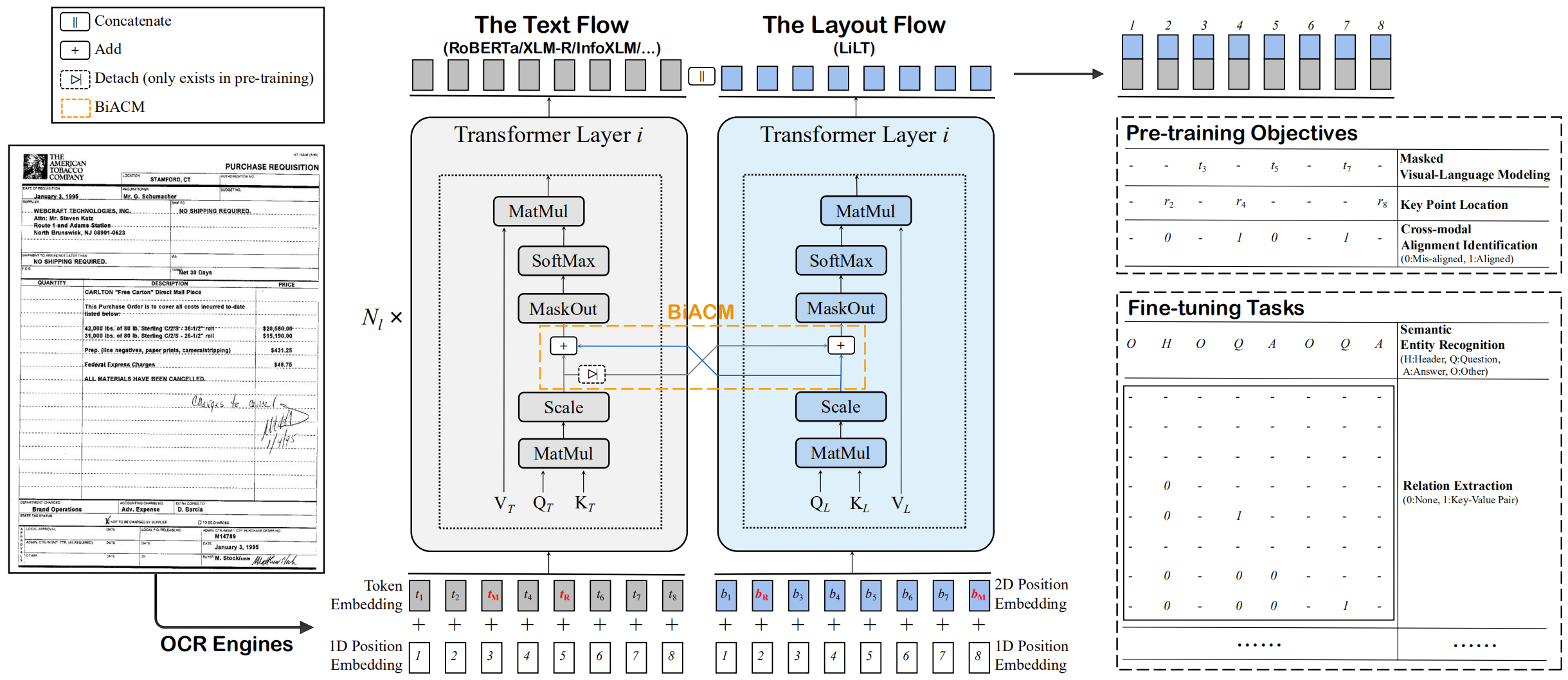
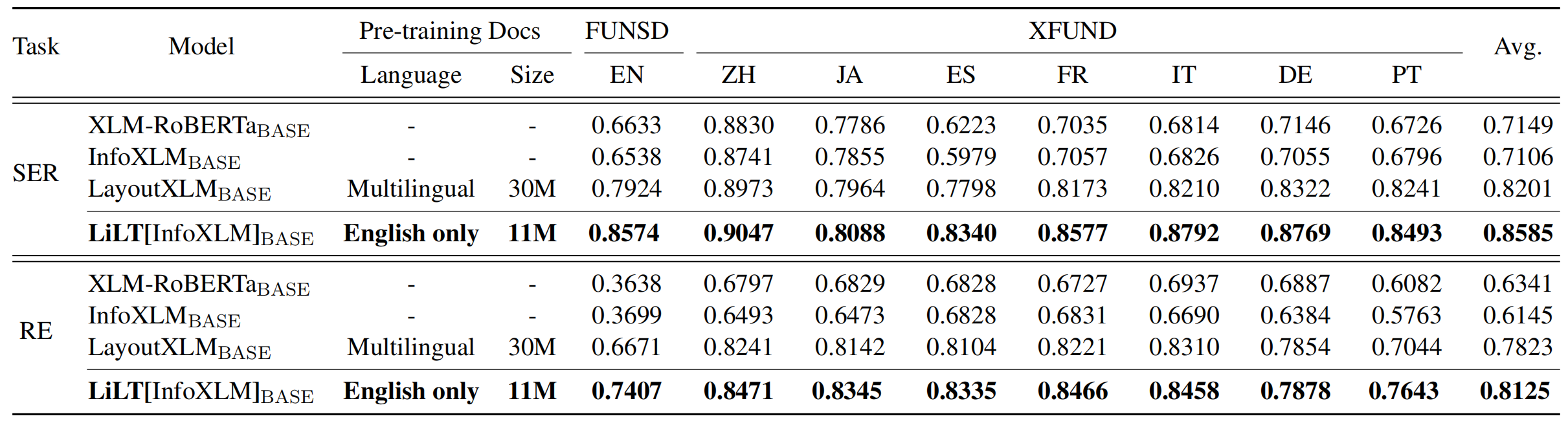
LILT已在單一語言(英語)的視覺文檔上進行了預先訓練,並且可以直接對其他語言進行微調,並具有相應的現成單語/多語言預訓練的預訓練的文本模型。我們希望這項工作的公眾可用性可以幫助記錄情報研究。
對於Cuda 11.x:
conda create -n liltfinetune python=3.7
conda activate liltfinetune
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=11.0 -c pytorch
python -m pip install detectron2==0.5 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html
git clone https://github.com/jpWang/LiLT
cd LiLT
pip install -r requirements.txt
pip install -e .或檢查detectron2/pytorch版本並相應地修改命令行。
在此存儲庫中,我們為FUNSD和XFUND提供了微調代碼。
您可以從此處下載我們的預處理數據(〜1.2GB) ,然後將未拉鍊的xfund&funsd/放在LiLT/下。
| 模型 | 語言 | 尺寸 | 下載 |
|---|---|---|---|
lilt-roberta-en-base | en | 293MB | OneDrive |
lilt-infoxlm-base | mul | 846MB | OneDrive |
lilt-only-base | 沒有任何 | 21MB | OneDrive |
如果您想將預先訓練的LILT與其他語言的Roberta相結合,請下載lilt-only-base ,並使用gen_weight_roberta_like.py生成自己的預訓練檢查點。
例如,將lilt-only-base與英語roberta-base相結合:
mkdir roberta-en-base
wget https://huggingface.co/roberta-base/resolve/main/config.json -O roberta-en-base/config.json
wget https://huggingface.co/roberta-base/resolve/main/pytorch_model.bin -O roberta-en-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text roberta-en-base/pytorch_model.bin
--config roberta-en-base/config.json
--out lilt-roberta-en-base或lilt-only-base與microsoft/infoxlm-base結合在一起:
mkdir infoxlm-base
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/config.json -O infoxlm-base/config.json
wget https://huggingface.co/microsoft/infoxlm-base/resolve/main/pytorch_model.bin -O infoxlm-base/pytorch_model.bin
python gen_weight_roberta_like.py
--lilt lilt-only-base/pytorch_model.bin
--text infoxlm-base/pytorch_model.bin
--config infoxlm-base/config.json
--out lilt-infoxlm-base CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_funsd.py
--model_name_or_path lilt-roberta-en-base
--tokenizer_name roberta-base
--output_dir ser_funsd_lilt-roberta-en-base
--do_train
--do_predict
--max_steps 2000
--per_device_train_batch_size 8
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_ser_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 2000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir ls_re_xfund_zh_lilt-infoxlm-base
--do_train
--do_eval
--lang zh
--max_steps 5000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_ser.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_ser_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 16000
--per_device_train_batch_size 16
--warmup_ratio 0.1
--fp16
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 examples/run_xfun_re.py
--model_name_or_path lilt-infoxlm-base
--tokenizer_name xlm-roberta-base
--output_dir mt_re_xfund_all_lilt-infoxlm-base
--do_train
--additional_langs all
--max_steps 40000
--per_device_train_batch_size 8
--learning_rate 6.25e-6
--warmup_ratio 0.1
--fp16
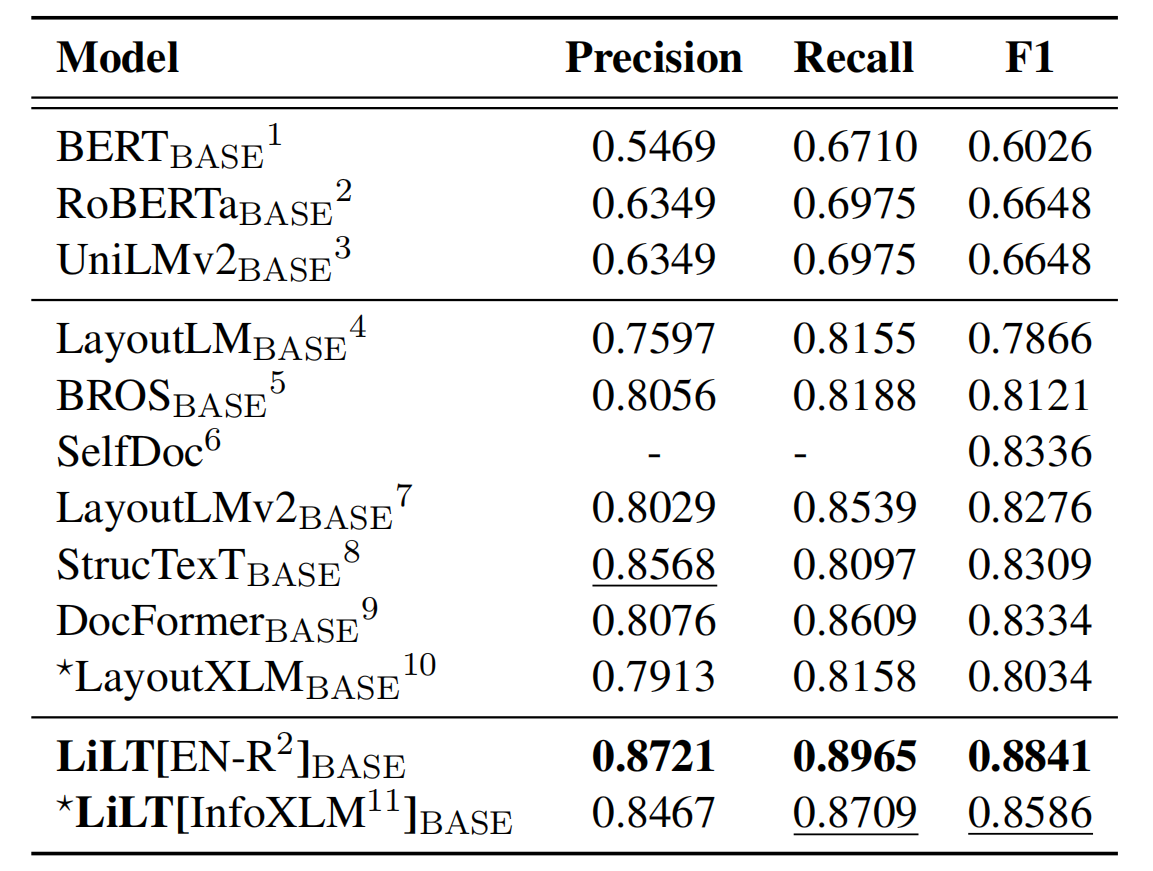
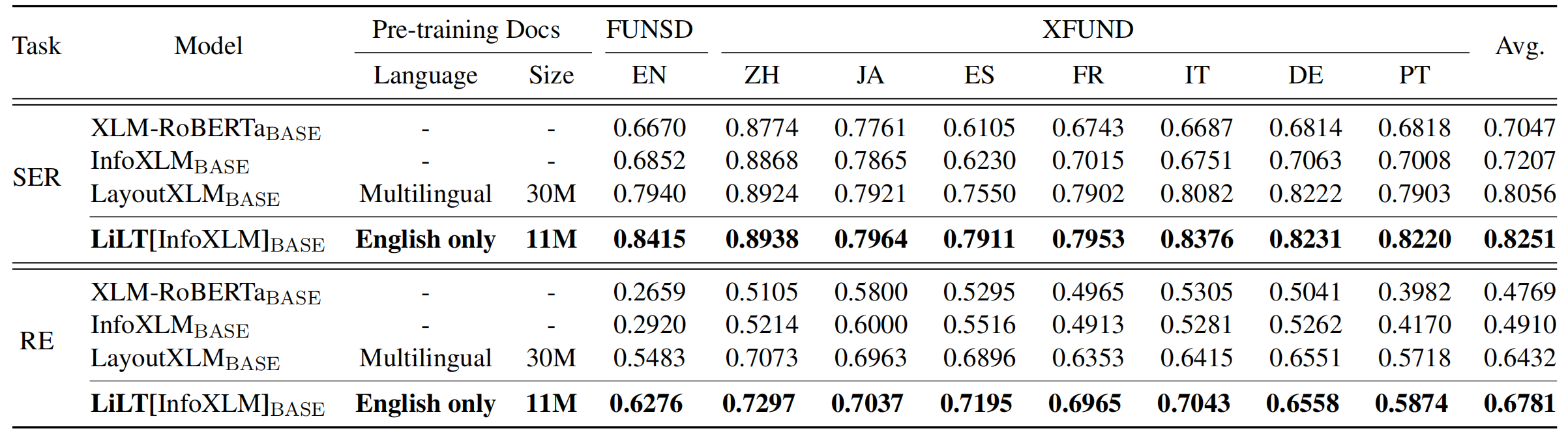
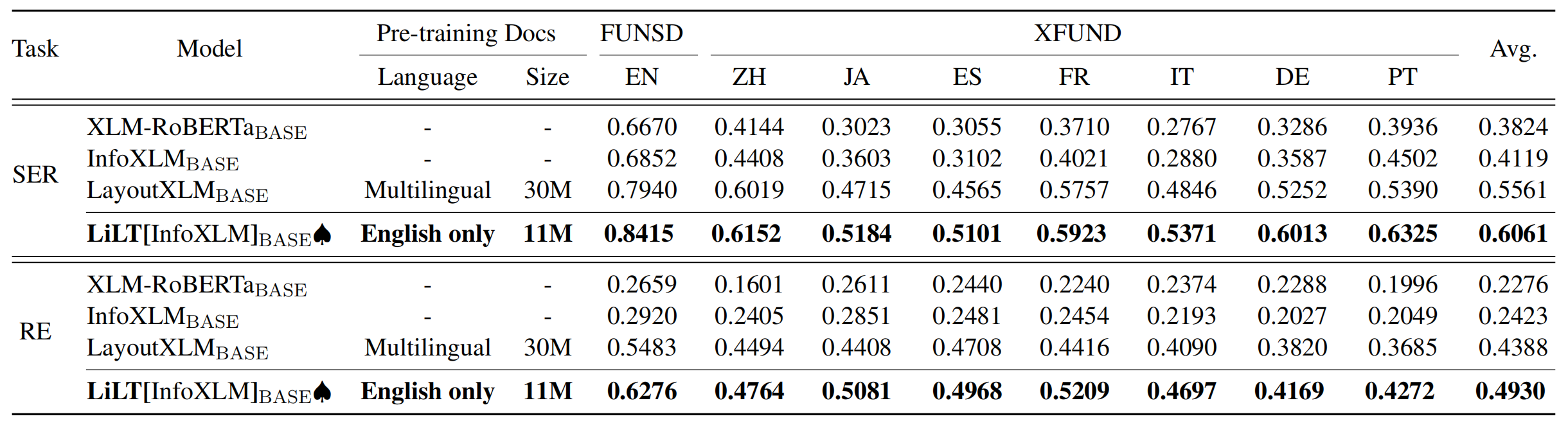
存儲庫從Unilm/Layoutlmft受益匪淺。非常感謝他們的出色工作。
如果我們的論文有助於您的研究,請在您的出版物中引用:
@inproceedings{wang-etal-2022-lilt,
title = "{L}i{LT}: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding",
author={Wang, Jiapeng and Jin, Lianwen and Ding, Kai},
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.534",
doi = "10.18653/v1/2022.acl-long.534",
pages = "7747--7757",
}
非常歡迎建議和討論。請通過發送電子郵件至[email protected]與作者聯繫。


